论文:Knowledge Graph Convolutional Networks for Recommender Systems,WWW,2019,Microsoft Research Asia
1. 应用背景
知识图谱卷积网络(Knowledge Graph Convolutional Networks,KGCN)是一种自动捕捉KG中高阶的结构信息和语义信息的推荐方法。其关键思想是在计算KG中给定实体的表示时,将具有偏差的邻域信息进行汇总和合并。
KGCN好处有二:
1.通过汇总邻居,局部临近结构(local proximity structure)可以有效的捕捉并存贮在实体中;
2.邻居的权重取决于连接关系和特定用户,这既代表了KG的语义信息(semantic information),又体现了用户对关系的个性化兴趣(personalized interests)。
文章贡献有三:
1.提出KGCN,通过扩展KG中每个实体的表示域,来捕获用户的高阶个性化兴趣;
2.在movielen-20M,book-crossing,lastFM三个real-world数据集上实验并与state-ofart比较;
3.开源代码和数据集;
2. 模型结构
2.1 问题表述
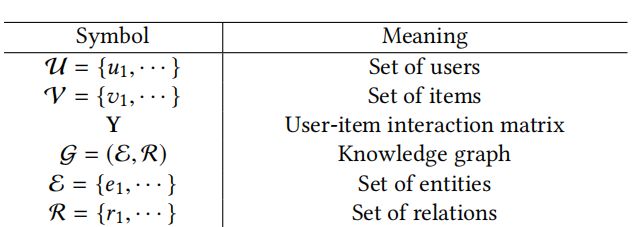
使用知识图谱的推荐算法的问题描述和符号定义是基本一致的,贴一个基础符号的表示表。
2.2 KGCN结构
KGCN的结构如图所示
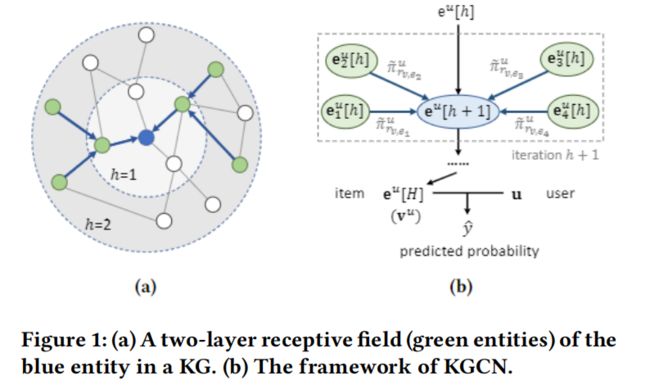
主要关注的是KGCN是如何在KG中学习实体的表示的,下面进行推导:
记一个用户为;
记一个候选物品/实体为;
记KG中与相连的实体集合为;
记实体与的关系边为;
0.记算用户对关系的得分:,函数;
举个例子:电影推荐场景下,有的用户可能更关注和历史浏览有相同 'star' 的电影;而有的用户更关注和历史浏览有相同 'genre' 的电影。'star' 和 'genre' 属于不同的边,表示了用户对于不同关系的不同关注度。
1.对每个用户对边的得分进行标准化表示,得:
2.得到的拓扑邻近结构:
但在实际的KG中,往往的尺寸大小会差别很大,因此使用固定尺寸的代替,
3.得到使用的邻近表示:
4.设计并使用聚合器函数:,来聚合和
作者设计了sum,concat,neighbor三种聚合器,最终效果是sum最好,其表示为:
5.用h-1层的聚合结果作为h层的实体表示:
2.3 损失函数
通过这种聚合更新,可以在KG上训练得到实体对于用户的H层向量表示:
预测结果为:
使用类似pairwise的交叉熵损失:其中,是交叉熵,是用户对应负样本的个数,满足 ,服从均匀分布。
3. 实验结果
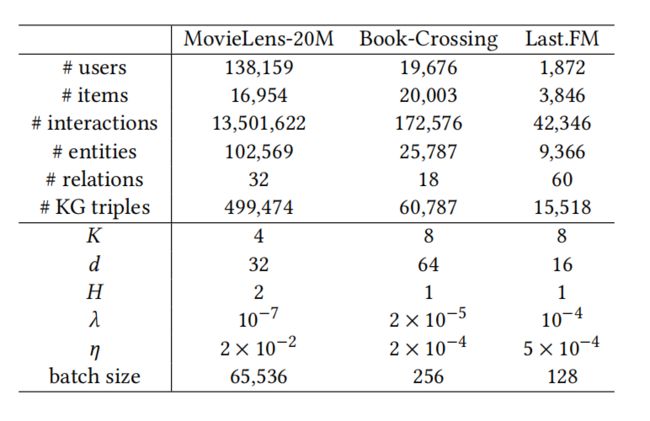
数据集:
MovieLens-20M,Book-Crossing dataset,Last.FM dataset
知识图谱:
Microsoft Satori
数据描述:
实验结果:
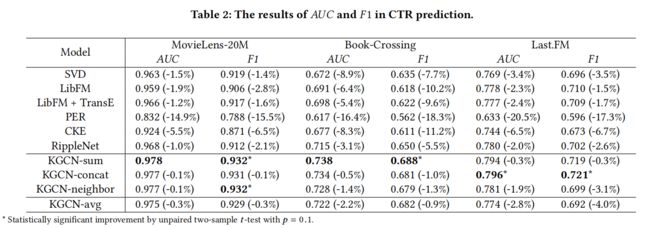
相关分析:
1.neighbor的尺寸大小:
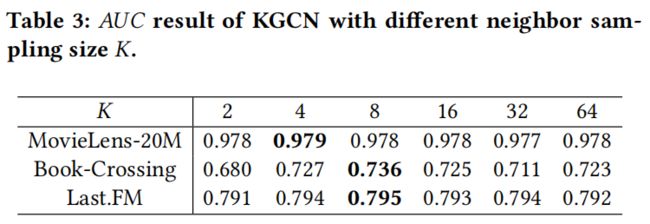
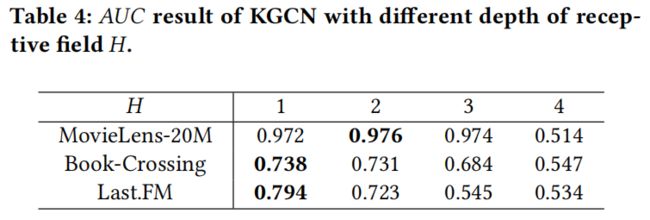
2.迭代的深度:
4. 代码实现
输入:user_id , item_id , label
self.user_indices = tf.placeholder(dtype=tf.int64, shape=[None], name='user_indices')
self.item_indices = tf.placeholder(dtype=tf.int64, shape=[None], name='item_indices')
self.labels = tf.placeholder(dtype=tf.float32, shape=[None], name='labels')
可训练矩阵:user_emb_matrix,entity_emb_matrix,relation_emb_matrix
self.user_emb_matrix = tf.get_variable(
shape=[n_user, self.dim], initializer=KGCN.get_initializer(), name='user_emb_matrix')
self.entity_emb_matrix = tf.get_variable(
shape=[n_entity, self.dim], initializer=KGCN.get_initializer(), name='entity_emb_matrix')
self.relation_emb_matrix = tf.get_variable(
shape=[n_relation, self.dim], initializer=KGCN.get_initializer(), name='relation_emb_matrix')
找到 item 的n层的邻居很容易,主要难点是关注如何聚合:
def _mix_neighbor_vectors(self, neighbor_vectors, neighbor_relations, user_embeddings):
avg = False
if not avg:
# [batch_size, 1, 1, dim]
user_embeddings = tf.reshape(user_embeddings, [self.batch_size, 1, 1, self.dim])
# [batch_size, -1, n_neighbor]
user_relation_scores = tf.reduce_mean(user_embeddings * neighbor_relations, axis=-1)
user_relation_scores_normalized = tf.nn.softmax(user_relation_scores, dim=-1)
# [batch_size, -1, n_neighbor, 1]
user_relation_scores_normalized = tf.expand_dims(user_relation_scores_normalized, axis=-1)
# [batch_size, -1, dim]
neighbors_aggregated = tf.reduce_mean(user_relation_scores_normalized * neighbor_vectors, axis=2)
else:
# [batch_size, -1, dim]
neighbors_aggregated = tf.reduce_mean(neighbor_vectors, axis=2)
return neighbors_aggregated
可以看到,neighbors_aggregated向量是通过邻居向量x用户-关系得分权重得到的。
5. 个人总结
KGCN是将GCN与RS任务相结合,其做法是:
对于一个实体向量v,每个Hop选固定size的neighbor来当做类CNN的感知野,用neighbor在特定“user-relation”下的得分作为权重,neighbor加权的结果来表示neighbor向量,尝试通过sum/concat/replace三种方式来更新v,迭代H个hop,得到KG中所有实体的emb。
其核心思想还是:利用邻居向量来扩充当前实体的向量表示,再通过Loss回传更新。
与RippleNet有意思的区别是:RippleNet关注于用户历史的扩充,KGCN关注于物品实体的扩充,其实可以尝试同时扩充二者,获取更丰富的表示。