其实事情是这样的,上个礼拜我去面试一家公司,工作是做爬虫。然后有了以下对话。
面试官:你是自学的,我有一些问题问你,python的浅拷贝和深拷贝是什么?
我:呵呵
面试官:额。。。你能不能说一说你是怎么理解python的面向对象编程?
我:呵呵
面试官:额。。。。好吧,我不问你基础了。你有没有爬过动态的网页?
我:有啊,我爬过豆瓣啊。
面试官:那我让你爬视频网站你怎么爬?F12里查看器是看不到视频地址的!
我:看不到么?
面试官:嗯!
我:不知道。。。。。
面试官:额。。。。你这样让我很为难的,要不你去试试爬腾讯视频。
我:好啊好啊!
面试官:你不要想用那些模拟浏览器来渲染JS哦!直接抓包!
结果我回到家一看!!什么鬼!!!!
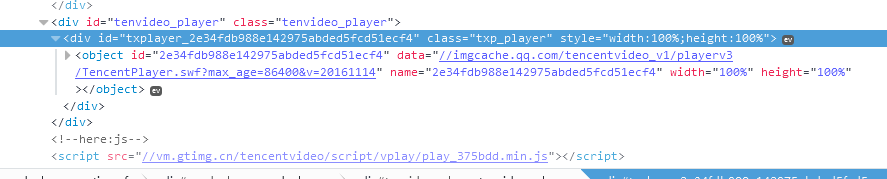

真的什么地址都没有啊!!!
怎么办?抓包?什么是抓包啊!!!
我只会用selenium加火狐浏览器来模拟爬动态网页啊。。。这工作是没希望了么?
我是个不会放弃的人!!然后就去百度了:
如何用python抓包
如何用python爬JS
后来经人指点我才明白抓包就是去F12里的network找包。。。。
然后我又百度了:
如何用python爬AJAX
仍然没个吊用!
不过我在搜索爬腾讯视频时候学会了直接用chrome的模拟手机浏览器可以登录移动端的视频网站,可以直接看到视频的地址链接。
但是。。。。。怎么用代码爬啊??
好了废话到此为止,大家也不想听下去了。我直接进入正题吧!
经过三天的学习,我首先弄清楚了对于这种动态网站的爬取方法。
首先,用network找到一个专门接收请求的真实地址,或者后门网址。

就是这个,只要在网址里加入参数,它就会返回数据。拉下去,我们可以看道参数

这里的参数有很多并不是必须的。我先在这里提前说一下,最后我们是要根据观察来找出规律重构出这个网址,因为我们做爬虫的不可能上网站开F12来找信息的。
我们看下网址打开后有什么
This XML file does not appear to have any style information associated with it. The document tree is shown below.
0
0
0
1479138997
1
135
0
3
0
64
10703
sd
0
1
标清;(270P)
4795182
8435750
1
235
10712
hd
0
1
高清;(480P)
0
1
超清;(720P)
17133689
0
650
10701
shd
o
60
5
480
0
1619695007
1
200
- 2
10
http://222.84.158.26/vhot2.qqvideo.tc.qq.com/
10
http://222.84.158.27/vhot2.qqvideo.tc.qq.com/
200
- 2
http://222.84.158.28/vhot2.qqvideo.tc.qq.com/
200
- 2
10
0
- 2
10
http://video.dispatch.tc.qq.com/96405217/
2
23
0
0
0
0
0
q0345aui4cn
q0345aui4cn
q0345aui4cn.p712.mp4
8435750
79487AB1BD24866699D881C26FC8E62D2131609CE05CC1F18B76EC6481957C2416C28CAE6B21FEE56DCB157706205BC52F3928F51CC08EE79AF4E3157C4940870340CFB9B9407A55FF02A8EA1B560B00A3ADC310709553ED9AC0E8E67705AE5D4097A5370B4BF1AB75B444A3A2EB7F51
0
135.722
9cac5ea26dbf008bce792704b6d67c97
21600
0
1
1
8435748
135.722
40a954202d9f663ac2443372afde8d4b
q0345aui4cn.10712.1
1
9
2
0
健忘症老人同一问题连问17次!这名耐心的医生火了
848
1
2
http://video.qpic.cn/video_caps/0/
2
10
45
80
10
q1
40001
40002
http://video.qpic.cn/video_caps/0/
2
5
90
160
5
q2
1
先不管,我们再打开另一个叫做getkey的网址看看里面的东西
50C099826174CDA1036AC3F8BB82BEC4A6E91005384153F81E3EF477C719CBF0B442C8D533F36402878D2B7C639318CD3078DEFC435C8C865813DBEB689F66D789F410D5115A745C3019F6ABAEBFF53258F4F524A9FE978D26595B6B1732F25992A33CB6F3F2C792FA22CAC171C7087C
62154.61
o
这么多,我们怎么知道爬虫需要哪些东西呢?
network里是可以直接找到video的,我们看一下视频的真实地址
`
http://183.60.171.154/vhot2.qqvideo.tc.qq.com/q0345aui4cn.p712.1.mp4?sdtfrom=v1090&type=mp4&
vkey=E1B062FA0354A56228FFE25100D1B41F83FEBC012471446999AA386A8FC8A8273AE07BFF6092B4F4AABCE8D98E7F622D71AF44C88B5D3F63A6ED4BFE45457ED0D95E67CA930861F396967521A97ED4154449A61DD95F24A7945262EEB481C3BAC8FE53A2B186F1FC111CE8D32FFBB8C1
&level=0&platform=11&br=60&fmt=hd&sp=0&guid=ED20EE2DB93337F04708204D247CB34A&locid=f9aa455a-6a68-4fd9-a4dd-0dcf179bd6b3&size=8435748&ocid=2535331244
`
很长很复杂对吧!让我们来精简一下,看能把哪些参数删掉。我下面就直接放出我爬虫爬到的精简版的地址吧
`
http://222.84.158.29/vhot2.qqvideo.tc.qq.com/q0345aui4cn.p701.1.mp4?vkey=46994EBB71F530AC11AB11EFA265508534036712DA0187B3939F9FDE9062FBA7B5C37F0C80D72626AEEB3CD87A15B19CB064817D98C4DD0D43D113804FE8F50F67DE15DD2FC48CC06FA9AE67678FD2CE9363358A1AC9BBCDB831B1AF79E7B105
`
首先我们看到 两个地址的IP,VKEY是不一样的。IP这个好解释,视频源不一样,地址不一样。然后Vkey它是一直在变化的,每次打开getkey这个页面都在变。我分析下一个视频地址精简后需要哪些东西
Ip=http://222.84.158.29/vhot2.qqvideo.tc.qq.com/(getinfo页面中有)
filenname=VID +P701.1.MP4(`P701其实由getinfo中的ID的1701去掉10,改为P获得。而.1.MP4是属于后缀.2.mp4应该也能播放,只要有这个视频源`)
vkey=46994EBB71F530AC11AB11EFA265508534036712DA0187B3939F9FDE9062FBA7B5C37F0C80D72626AEEB3CD87A15B19CB064817D98C4DD0D43D113804FE8F50F67DE15DD2FC48CC06FA9AE67678FD2CE9363358A1AC9BBCDB831B1AF79E7B105(`这个在getkey页面中获得`)
好了所以我们来重新整理下思路吧!
我要在一开始的视频页面获得vid(`这个我不想解释自己开F12查看器`)
然后在getinfo页面获得ID,拼接filename
在getkey页面获得Vkey
最后拼接成我们的视频url
这里我放出我精简过了的getinfo和getkey网址,只要更换vid,filename就额可以打开了
`getinfo='http://vv.video.qq.com/getinfo?vids={vid}&otype=xlm&defaultfmt=fhd'`
`getkey='http://vv.video.qq.com/getkey?format={id}&otype=xml&vt=150&vid={vid}&ran=0%2E9477521511726081\\\\&charge=0&filename={filename}&platform=11'`
这里我得强调,getkey的参数是由getinfo中获得的!
分析得差不多了,我们开始写爬虫把!!
from urllib.request import Request, urlopen
from urllib.error import URLError,HTTPError
from bs4 import BeautifulSoup
import re
print('https://v.qq.com/x/page/h03425k44l2.html\\n \\
https://v.qq.com/x/cover/dn7fdvf2q62wfka/m0345brcwdk.html\\n \\
http://v.qq.com/cover/2/2iqrhqekbtgwp1s.html?vid=c01350046ds')
web = input('请输入网址:')
if re.search(r'vid=',web) :
patten =re.compile(r'vid=(.*)')
vid=patten.findall(web)
vid=vid[0]
else:
newurl = (web.split("/")[-1])
vid =newurl.replace('.html', ' ')
从视频页面找出vid
getinfo='http://vv.video.qq.com/getinfo?vids={vid}&otype=xlm&defaultfmt=fhd'.format(vid=vid.strip())
def getpage(url):
req = Request(url)
user_agent = 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit'
req.add_header('User-Agent', user_agent)
try:
response = urlopen(url)
except HTTPError as e:
print('The server couldn\\'t fulfill the request.')
print('Error code:', e.code)
except URLError as e:
print('We failed to reach a server.')
print('Reason:', e.reason)
html = response.read().decode('utf-8')
return(html)
打开网页的函数
a = getpage(getinfo)
soup = BeautifulSoup(a, "html.parser")
for e1 in soup.find_all('url'):
ippattent = re.compile(r"((?:(2[0-4]\\d)|(25[0-5])|([01]?\\d\\d?))\\.){3}(?:(2[0-4]\\d)|(255[0-5])|([01]?\\d\\d?))")
if re.search(ippattent,e1.get_text()):
ip=(e1.get_text())
for e2 in soup.find_all('id'):
idpattent = re.compile(r"\\d{5}")
if re.search(idpattent,e2.get_text()):
id=(e2.get_text())
filename=vid.strip()+'.p'+id[2:]+'.1.mp4'
找到ID和拼接FILENAME
getkey='http://vv.video.qq.com/getkey?format={id}&otype=xml&vt=150&vid={vid}&ran=0%2E9477521511726081\\
&charge=0&filename={filename}&platform=11'.format(id=id,vid=vid.strip(),filename=filename)
利用getinfo中的信息拼接getkey网址
b = getpage(getkey)
key=(re.findall(r'
videourl=ip+filename+'?'+'vkey='+key[0]
print('视频播放地址 '+videourl)
完成了

然后我就把爬虫上传到github发给面试官了,满心欢喜的等着上班结束讨饭生活!
但素!!
面试官:嗯,不错!居然真的做出来了!你的期望薪酬是多少?
我:嗨,这个吗我没经验。你随便给我个六七千打发我就可以了!
面试官:嗯,你没有经验我们是只能按应届生标准给你薪酬的。
我:没事没事,薪酬不重要。最重要先让我进这个行业积累经验!
过了一会
面试官:其实。。。。我们老大说你基础太差了,虽然你自学能力不错。但是你懂数据结构与算法吗?
我:不会。。。。
面试官:其实爬虫我们已经开发好了,接下来要做的是日志分析和推荐系统开发。
我:。。。。。。
所以,我没拿到offer,继续要饭。。。。
我又不看腾讯视频,爬腾讯也没用,把源码放上来大家学习下吧。谁爱爬自己爬,还可以免广告。
o(╥﹏╥)o 我什么时候才能找到工作啊???
算了,明天我就学前端去,争取年底前当个切图仔!!