论文:RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
,CIKM,2018,Microsoft Research Asia & Meituan AI Lab
1. 应用背景
与 DKN 一样,RippleNet 也是利用知识图谱(Knowledge Graph,KG)作为辅助信息(side information)来进行推荐的一种方法。

文章认为 KG 的优点有三:
1.KG引入物品间的语义相关性,有助于找到潜在的联系,提升推荐的准确性;
2.KG有多种类型的关系边,有助于合理地扩展用户的兴趣,可以提升推荐的多样性;
3.KG可以描述用户历史记录与推荐物品间的关联,提升推荐的可解释性;
认为现有的基于知识图谱的推荐方法的问题有二:
1.embedding-based 的策略(如DKN)更适合于in-graph应用,如链接预测,并不能直接有效的描述实体间关系;
2.path-based 的策略(如PER)基于元路径/元图的提取潜在特征,严重依赖于手工设计元路径;
因此,提出了 RippleNet:一种端到端的点击率(click-through rate,CTR)预测模型。
1.相较于 embedding-based 方法,RippleNet 将知识图嵌入(Knowledge Graph Embedding,KGE)通过偏好传播(preference propagation)的方式融合在推荐中;
2.相较于 path-based 的方法,RippleNet 可以自动化发现候选物品和用户历史交互物品间的连接路径,无需人工;
Ripple是波纹的意思,表示在KG上用户兴趣集合如水波般扩散,如水波般衰减。
RippleNet就是模拟用户兴趣在知识图谱上的一个传播过程,如下图所示。用户的兴趣以其历史记录为中心,在知识图谱上逐层向外扩散,而在扩散过程中不断的衰减,类似于水中的波纹,因此称为RippleNet。
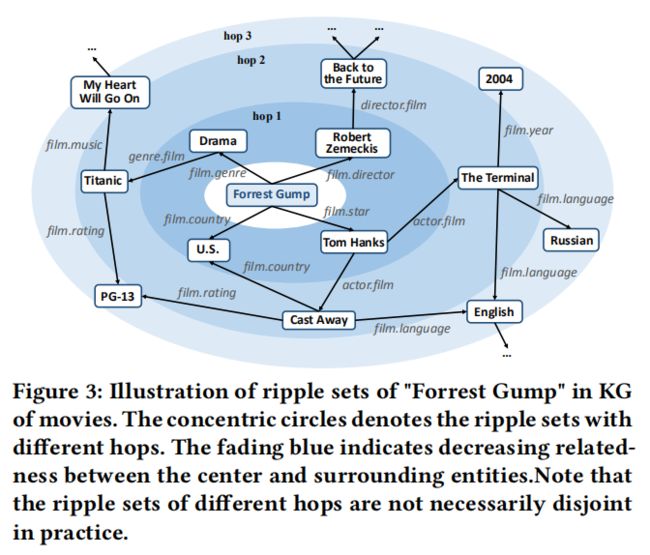
2. RippleNet结构
2.1 整体框架
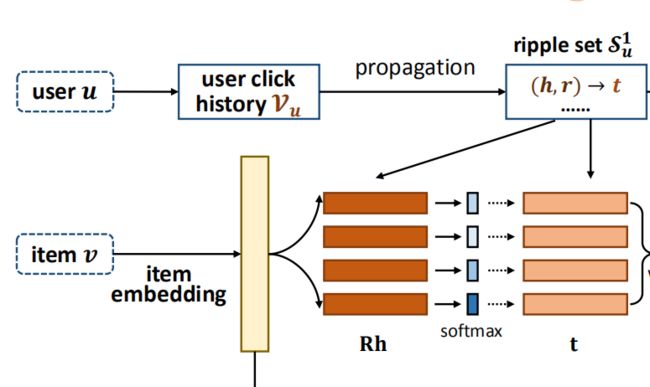
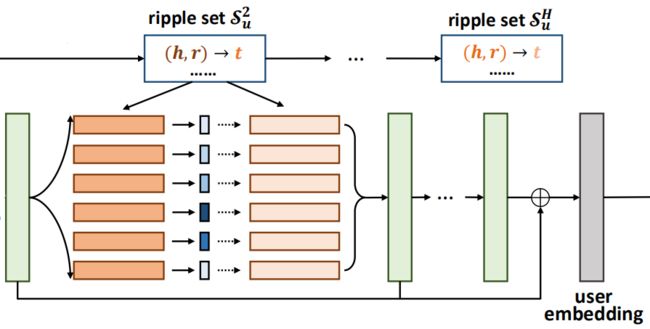
可以看到,最终的预测值是通过item embedding和user embedding得到的,item embedding通过embedding 层可以直接得到,关键是user embedding的获取。user embedding是通过图中的绿色矩形表示的向量相加得到的,而绿色矩形又是由repple set计算得到的,接下来,我们以第一个绿色矩形表示的向量为例,来看一下具体是如何计算的。

2.2 Ripple Set
Relevant Entity 定义
在给定 KG 的情况下,用户的 k-hop 相关实体定义如下:
其中,,即用户历史交互过的物品集合。
Ripple Set 定义
用户的 k-hop 的 Ripple Set 被定义为以 k-1 相关实体为头节点的相关三元组:
Ripple Set 的尺寸会随着 hop 的值变得越来越大怎么办?
1.大量实体是水槽实体(sink entity),只有输入边,没有输出边,如“PG-13”。一定程度上控制尺寸;
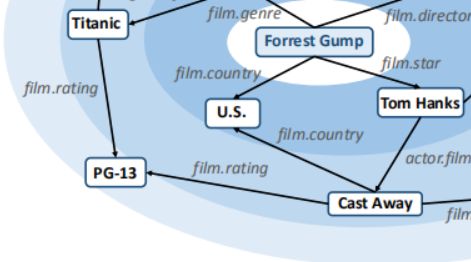
2.在特定推荐场景下,可以限定边也是场景特定的,如图是电影推荐,只选择电影相关的边,来控制尺寸;

3.hop的最大值 H 一般不会很大,因为离用户太远的实体可以意义不大,以此来控制尺寸;
4.可以使用固定尺寸的Ripple Set而非使用完整的Ripple Set。
2.3 偏好传播
相似度计算
物品:定义物品的 embedding 为 ,其中为维度;
Ripple Set:set中的第个元素记为,定义关系的 embedding 为,头节点 的 embedding 为;
相似度:第个元素与物品的相关性:
为什么要使用?
因为物品-实体对在通过不同关系测量时可具有不同的相似性。 例如,“Forrest Gump”和“Cast Away”在考虑他们的导演或明星时非常相似,但如果按流派或作家来衡量,则没有共同之处。
用户向量表示
得到set中每个在下与的相似度后,将三元组中的乘以其对应的相似度权值,得到用户兴趣经第一轮扩散后的结果:
,即绿色矩形表示的向量。
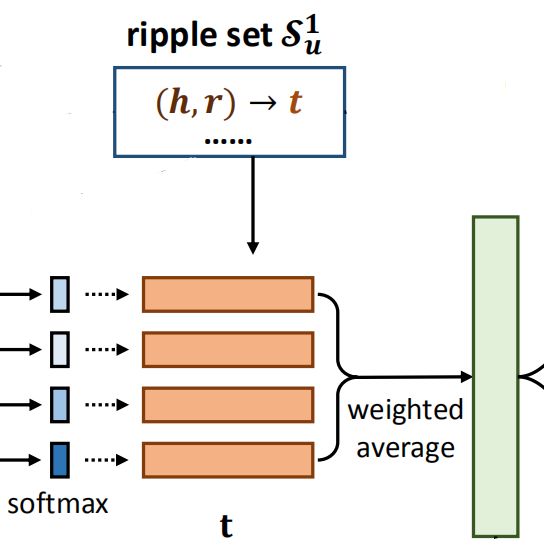
接下来,我们重复上面的过程,假设一共H次,那么最终 user embedding 为:u = o_u^1 + o_u^2 + ... + o_u^H。
3. 损失函数
预测:
损失:
即交叉熵+正则项。
4. 实验结果
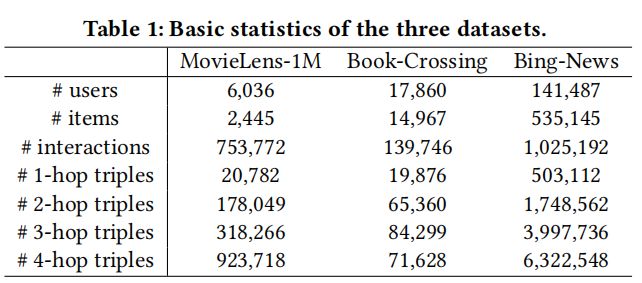
数据集:
MovieLens-1M,Book-Crossing dataset,Bing-News dataset
知识图谱:
Microsoft Satori
数据描述:
特征:
MovieLens-1M:使用电影的 ID embedding
Book-Crossing:使用书籍的 ID embedding
Bing-News :使用新闻的 ID embedding 和 titles word embedding 的拼接
实验结果:

超参数分析:
