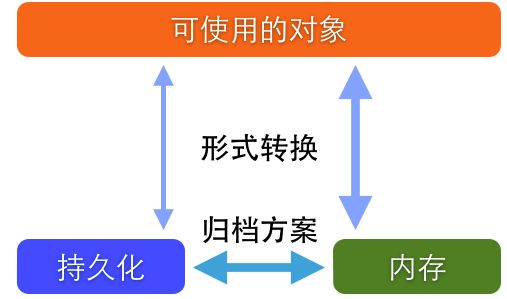
谈到数据储存,首先要明确区分两个概念,数据结构和储存方式。所谓数据结构就是数据存在的形式。除了基本的NSDictionary、NSArray和NSSet这些对象,还有更复杂的如:关系模型、对象图和属性列表多种结构。而存储方式则简单的分为两种:内存与闪存。内存存储是临时的,运行时有效的,但效率高,而闪存则是一种持久化存储,但产生I/O消耗,效率相对低。把内存数据转移到闪存中进行持久化的操作称成为归档。
plist
它全名是:Property List,属性列表文件,它是一种用来存储串行化后的对象的文件。属性列表文件的扩展名为.plist ,因此通常被称为 plist文件。文件是xml格式的。
Plist文件通常用于储存用户设置,也可以用于存储捆绑的信息在开发过程中,有时候需要把程序的一些配置保存下来,或者游戏数据等等。 这时候需要写入Plist数据。写入的plist文件会生成在对应程序的沙盒目录里。
NSUserDefaults
NSUserDefaults被设计用来存储设备和应用的配置信息,它通过一个工厂方法返回默认的、也是最常用到的实例对象。这个对象中储存了系统中用户的配置信息,开发者可以通过这个实例对象对这些已有的信息进行修改,也可以按照自己的需求创建新的配置项。
NSUserDefaults把配置信息以字典的形式组织起来,支持字典的项包括:字符串或者是数组,除此之外还支持数字等基本格式。一句话概括就是:基础类型的小数据的字典。操作方法几乎与NSDictionary的操作方法无异,另外还可以通过指定返回类型的方法获取到指定类型的返回值。
NSUserDefaults的所有数据都放在内存里,因此操作速度很快,并还提供一个归档方法:+ (void)synchronize。开发者自定义的配置项会以plist格式的文件归档在相应应用目录的/Library/Preferences/[App_Bundle_Identifier].plist文件。再次初始化获得实例对象后,框架会把用户自定义的这个配置和系统配置合并得到完整数据。
归档
归档(对象从内存转移到硬盘)和解归档(从硬盘读取对象到内存), 需要继承NSObject并遵循NSCoding协议
class Student: NSObject, NSCoding
{
var name: String
var age: Int
var gender: Bool
init(name: String, age: Int, gender: Bool)
{
self.name = name
self.age = age
self.gender = gender
}
// 解归档的时候要调用的方法(解码)
required init?(coder aDecoder: NSCoder)
{
name = aDecoder.decodeObjectForKey("name") as! String
age = aDecoder.decodeIntegerForKey("age")
gender = aDecoder.decodeBoolForKey("sex")
}
// 归档的时候要调用的方法(编码)
func encodeWithCoder(aCoder: NSCoder)
{
aCoder.encodeObject(name, forKey: "name")
aCoder.encodeInteger(age, forKey: "age")
aCoder.encodeBool(gender, forKey: "sex")
}
func study()
{
}
}
归档和解归档也是一种实现数据持久化的方案, 游戏的存档和读档就可以用归档和解归档来完成
let stu = Student(name: "骆昊", age: 35, gender: true)
// 创建一个数据中转站
let mData = NSMutableData()
// 创建归档器
let archiver = NSKeyedArchiver(forWritingWithMutableData: mData)
// 将学生对象用键值对的方式进行归档
archiver.encodeObject(stu, forKey: "student")
// 完成归档
archiver.finishEncoding()
// 将中转站中的数据写入文件
mData.writeToFile("/Users/Hao/Desktop/my.dat", atomically: true)
// 从文件中读取解归档要使用的数据
if let data = NSData(contentsOfFile: "/Users/Hao/Desktop/my.dat")
{
// 创建解归档器
let unachiver = NSKeyedUnarchiver(forReadingWithData: data)
// 通过键找到需要解归档的对象
let stu = unachiver.decodeObjectForKey("student") as! Student
print(stu.name)
print(stu.age)
print(stu.gender ? "男" : "女")
}
数据库(sqlite和CoreData)
1.sqlite
iOS的SDK里预置了SQLite的库,开发者可以自建SQLite数据库。SQLite每次写入数据都会产生IO消耗,把数据归档到相应的文件。
SQLite擅长处理的数据类型其实与NSUserDefaults差不多,也是基础类型的小数据,只是从组织形式上不同。开发者可以以关系型数据库的方式组织数据,使用SQL DML来管理数据。 一般来说应用中的格式化的文本类数据可以存放在数据库中,尤其是类似聊天记录、Timeline等这些具有条件查询和排序需求的数据。
每一个数据库的句柄都会在内存中都会被分配一段缓存,用于提高查询效率。另一个方面,由于查询缓存,当产生大量句柄或数据量较大时,会出现缓存过大,造成内存浪费。
SQLite的使用起来要比NSUserDefaults复杂的多,因此建议开发者使用SQLite要搭配一个操作控件使用,可以简化操作。笔者开发的SQLight是一款对SQLite操作的封装,把相对复杂的SQLite命令封装成对象和方法,可以供大家参考。大家可以在Github上获取这个工程的代码进一步了解。
2.CoreData
官方给出的定义是,一个支持持久化的,对象图和生命周期的自动化管理方案。严格意义上说CoreData是一个管理方案,他的持久化可以通过SQLite、XML或二进制文件储存。如官方定义所说,CoreData的作用远远不止储存数据这么简单,它可以把整个应用中的对象建模并进行自动化的管理。
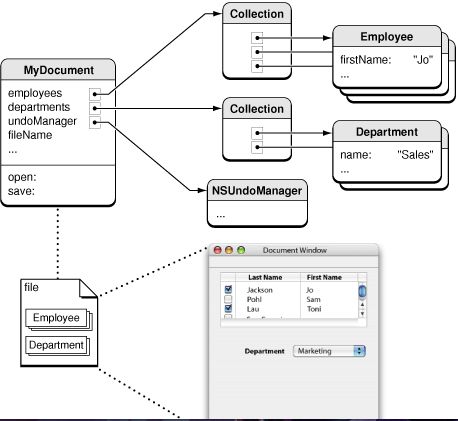
正如上图所示,MyDocument是一个对象实例,有两个Collection:Employee和Department,存放各自的对象列表。MyDocument、Employee和Department三个对象以及他们之间的关系都通过CoreData建模,并可以通过save方法进行持久化。
从归档文件还原模型时CoreData并不是一次性把整个模型中的所有数据都载入内存,而是根据运行时状态,把被调用到的对象实例载入内存。框架会自动控制这个过程,从而达到控制内存消耗,避免浪费。
无论从设计原理还是使用方法上看,CoreData都比较复杂。因此,如果仅仅是考虑缓存数据这个需求,CoreData绝对不是一个优选方案。CoreData的使用场景在于:整个应用使用CoreData规划,把应用内的数据通过CoreData建模,完全基于CoreData架构应用。
总结
以上介绍了几种iOS开发中经常会遇到的储存数据方法,从其存储原理、使用方式和适用场景几方面进行进了简单的对比。事实上每一款应用都很难采用一种单一的方案完成整个应用的数据储存任务,需要根据不同的数据类型,选择最合适的方案,以便整个应用获得良好的运行时性能。