DSSM 的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
论文原文
模型结构:
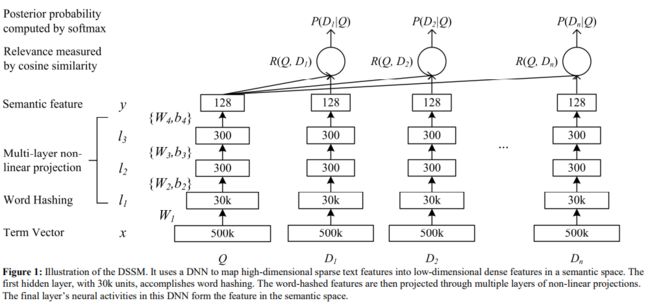
第一层是一个简单的映射层,使用word hashing 方法将句子50W的one-hot表示降低到了3W,原理是对句子做letter level 的trigrim 并累加。
如下图: #boy#会被切分成#-b-o, b-o-y, o-y-#。

选用trigrim而不用bigrim或者unigrim的原因是为了权衡表示能力和冲突,两个单词冲突表示两个单词编码后的表示完全相同。

第二层到第四层是典型的MLP网络,最终得到128维的句子表示

激活函数是tanh

对正负样本计算cosine距离
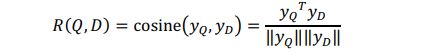
再利用平滑后的softmax得到概率
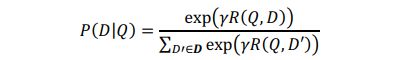
损失函数是似然损失,原理是最大化点击正样本的概率

论文中实现的一些细节:

下面用tensorflow实现这个经典的model
导包
import tensorflow as tf
定义基于语料的letter trigrim维度和输入的query batch 和 doc batch
#TRIGRAM_D 表示letter trigrim 之后的维度
TRIGRAM_D = 1000
#定义query输入和doc输入
query_batch = tf.sparse_placeholder(tf.float32,
shape=[None,TRIGRAM_D],
name='QueryBatch')
doc_batch = tf.sparse_placeholder(tf.float32,
shape=[None, TRIGRAM_D],
name='DocBatch')
初始化第一层的参数,L1_N表示输出的维度,参考的是论文中的初始化方法
#第一层输出维度
L1_N = 300
l1_par_range = np.sqrt(6.0 / (TRIGRAM_D + L1_N))
weight1 = tf.Variable(tf.random_uniform([TRIGRAM_D, L1_N],
-l1_par_range,
l1_par_range))
bias1 = tf.Variable(tf.random_uniform([L1_N],
-l1_par_range,
l1_par_range))
#因为数据比较稀疏,所以用sparse_tensor_dense_matmul
query_l1 = tf.sparse_tensor_dense_matmul(query_batch, weight1) + bias1
doc_l1 = tf.sparse_tensor_dense_matmul(doc_batch, weight1) + bias1
#激活层,也可以换成别的激活函数
query_l1_out = tf.nn.tanh(query_l1)
doc_l1_out = tf.nn.tanh(doc_l1)
接下来构造第二三层
#第二层的输出维度
L2_N = 300
l2_par_range = np.sqrt(6.0 / (L1_N+ L2_N))
weight2 = tf.Variable(tf.random_uniform([L1_N, L2_N],
-l2_par_range,
l2_par_range))
bias2 = tf.Variable(tf.random_uniform([L2_N],
-l2_par_range,
l2_par_range))
query_l2 = tf.sparse_tensor_dense_matmul(query_l1_out , weight2) + bias2
doc_l2 = tf.sparse_tensor_dense_matmul(doc_l1_out , weight2) + bias2
query_l2_out = tf.nn.tanh(query_l2)
doc_l2_out = tf.nn.tanh(doc_l2)
#第三层
L3_N = 128
l3_par_range = np.sqrt(6.0 / (L2_N+ L3_N))
weight3 = tf.Variable(tf.random_uniform([L2_N, L3_N],
-l3_par_range,
l3_par_range))
bias3 = tf.Variable(tf.random_uniform([L3_N],
-l3_par_range,
l3_par_range))
query_l3 = tf.sparse_tensor_dense_matmul(query_l2_out , weight3) + bias3
doc_l3 = tf.sparse_tensor_dense_matmul(doc_l2_out , weight3) + bias3
query_l3_out = tf.nn.tanh(query_l3)
doc_l3_out = tf.nn.tanh(doc_l3)
计算相似度
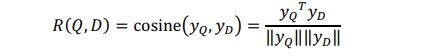
#NEG表示负样本的个数
NEG = 4
# ||yq||
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_l3_out ), 1, True)),
[NEG + 1, 1])
# ||yd||
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_l3_out), 1, True))
# yqT yd
prod = tf.reduce_sum(tf.mul(tf.tile(query_l3_out , [NEG + 1, 1]), doc_l3_out), 1, True)
norm_prod = tf.mul(query_norm, doc_norm)
# cosine
cos_sim_raw = tf.truediv(prod, norm_prod)
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [NEG + 1, BS])) * Gamma
计算loss
#BS为batch_size,计算batch平均损失
prob = tf.nn.softmax((cos_sim))
#正例的softmax值
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
#最小化loss,计算batch的平均损失
loss = -tf.reduce_sum(tf.log(hit_prob)) / BS
定义优化方法,训练
#定义优化方法和学习率
train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)
with tf.Session(config=config) as sess:
sess.run(tf.initialize_all_variables())
for step in range(FLAGS.max_steps):
sess.run(train_step, feed_dict={query_batch : ...
doc_batch : ...}})
实现过程中的一些细节:
- doc和query是share hash embedding和mlp层的;
- 损失函数只包含了正例,但是在计算softmax值的时候考虑了反例,这也是反例存在的意义;