脑抽的我上个文章烂尾,又开新坑,,,,我只能对自己前面开的烂坑说一句:青山不改,绿水长流,我们有缘再见!
这次我想刷一刷算法题(对,我又叒叕换目标了),把常见的基础算法做一个总结(千万别又是起个头就扔那里不管了,真的是废人一个了。。。)
好,话不多说,递归(Recursion)走起!
- 目录:
算法:附录
算法(1):递归
算法(2):链表
算法(3):数组
算法(4):字符串
算法(5):二叉树
算法(6):二叉查找树
算法(7):队列和堆栈(附赠BFS和DFS)
算法(8):动态规划
算法(9):哈希表
算法(10):排序
算法(11):回溯法
算法(12):位操作
概念理解:
首先我们分析一下定义,递归是一种使用某种函数来解决问题的方法(当然你可以忽略这句废话),特殊之处便在于该函数会不断调用它自身来作为其子程序。
那么,如何实现这么一个函数呢?它调用自己,又是干了些什么呢?
这个小技巧便是该递归函数每一次调用的时候,它都能将给定的问题变成该问题的子问题,该函数会不知疲倦的一直调用它自己(觉得像影分身之术,但是确切点说的话,是那种分身又施展影分身术的 feel...),直到子问题被解决掉,不再产生递归为止(所以说,不是子子孙孙无穷匮哦,递归没有我们的愚公爷爷厉害)。
所以,递归函数是一定存在边界的,也就是终止条件。在遇到某种情况时,递归函数将不再调用自身,而是输出一个结果(当然也可以什么也不输出,直接结束子程序)。所以写递归函数的时候,一定不要忘了写终止递归的条件(个人建议,先写这些边界条件,后面再写程序处理逻辑)~
扯了这么多,脑中挥散不去的还是大家对我爆喊 “talk is cheap, show me the code!"的场景,那么,代码兄,该你登场了(以下题目均来自LeetCode)~
附注:建议大家看看问题3,因为提到了一个递归经常遇到的问题,重复计算,而解决重复计算的方法也很简单,加入一个记忆机制(Memoization),也就是储存我们计算过的值即可。
问题1:字符串翻转,要求,O(1)空间复杂度(看所给的例子输入,题目应该叫列表翻转才更贴切)
例子:
输入: ['a','b','c']
输出: ['c','b','a']
解决思路:
1.取出首尾两个字符,并做交换;
2.递归调用该函数,来翻转剩下的子串。
3.设计跳出递归的边界条件,这里是begin >= end,即字符串遍历完毕。
def reverseString(begin, end,s) -> None:
"""
Do not return anything, modify s in-place instead.
"""
if begin >= end:
return
s[begin], s[end] = s[end], s[begin]
reverseString(begin + 1, end - 1, s)
s = ['a','b','c']
reverseString(0, len(s) - 1, s)
print(s)
### output ###
# ['c', 'b', 'a']
问题2:给定一个链表,每两个相邻的节点交换位置,并返回头节点。
例子:
输入链表:1->2->3->4
输出链表:2->1->4->3
解决思路:
1.交换前两个节点的位置;
2.把剩下的链表传递给自身,递归调用。
3.当抵达链表尾部时结束递归。
class ListNode: #定义节点类
def __init__(self, x):
self.val = x
self.next = None
def swapPairs(head) -> ListNode: #实现功能的递归函数
if head == None or head.next == None:
return head
temp = head.next # 节点2,也就是temp,即为我们所要的head
head.next = swapPairs(temp.next) #将节点1 和后面的链表串拼接,也就是(4->3)
temp.next = head # 将节点2的后面接上节点1
return temp #返回节点2
def printListNode(node): #辅助函数,打印链表
while node:
print(node.val, end=' ')
if node.next:
print('->', end=' ')
node = node.next
print()
if __name__ == '__main__':
head = node = ListNode(1)
for i in range(2,5):
node.next = ListNode(i)
node = node.next
printListNode(head)
ans = swapPairs(head)
printListNode(ans)
问题3:杨辉三角形(听说你不知道什么是杨辉三角形,链接附上,送给各位看官)

在讨论这个问题之前,为了让大家看的更清晰,我们先提纲挈领一波,在此讨论一下两个概念,递推关系和边界条件。
递推关系说白了就是问题结果和子问题的结果之间的关系,而边界条件我们前面提到过,便是递归到了终点,问题无法继续分解为子问题,可以直接得到答案。
那么通过这个例子,大家一起来看看这两个概念的具现到底是何方神圣把~
首先,我们定义一个函数,, 代表第 行, 代表第 列,那么,我们可以列出递归关系式:
其次,再列出边界条件:
这样子,思路是不是就清晰明了一些了呢?当以后遇到复杂的递归问题的时候,可以先尝试列出递归关系式和边界条件,可以方便我们更清晰的整理思路呦~
当然,问题以及代码如下:
输入: 5
输出:
[
[1],
[1,1],
[1,2,1],
[1,3,3,1],
[1,4,6,4,1]
]
def generate(numRows) -> list:
def helper(i, j):
if j == 0 or j == i:
return 1
return helper(i - 1, j - 1) + helper(i - 1, j)
ans = []
for i in range(0, numRows):
temp = []
for j in range(0, i + 1):
temp.append(helper(i, j))
ans.append(temp)
print(ans)
return ans
if __name__ == '__main__':
generate(5)
上面我们的helper函数,完美的按照边界条件和递归关系式要求所写,结果也是没有任何问题。但是,但是,但是!各位小伙伴试试把generate(5) 换成generate(30)试试(测测你电脑性能 /斜眼笑)?花费的时间多的让你怀疑人生,哈哈~ 那么问题来了,到底是什么原因导致的呢?
我们思考一下,当计算的时候,我们需要计算 和,而这两个都需要计算一次,聪明的朋友,你是不是发现了问题所在?对,那就是重复计算(这个地方一定要加黑加粗,因为递归非常容易遇到这个问题,大家一定要留意才行)!当你需要显示的行数愈多时,重复计算的量就会越大。
所以,上面的程序也就逗小孩子玩玩,实用性几乎为零(为什么用几乎?因为它还能逗小孩子玩玩。所以这里充分体现了作者严谨的撰文态度)。那么,这种问题该如何解决呢?正解,加入记忆机制,将我们之前计算过的全部储存下来即可~
关门,上代码!
def generate(numRows) -> list:
cache = {}
def helper(i, j):
if (i,j) in cache:
return cache[(i,j)]
if j == 0 or j == i:
return 1
result = helper(i - 1, j - 1) + helper(i - 1, j)
cache[(i,j)] = result
return result
ans = []
for i in range(0, numRows):
temp = []
for j in range(0, i + 1):
temp.append(helper(i, j))
ans.append(temp)
print(ans)
return ans
if __name__ == '__main__':
generate(5)
这个时候,我们哪怕把5换成500,也是分分钟的事情,不,秒秒钟。
问题4:链表翻转(又是一道可恶的链表题)
例子:
输入: 1->2->3->4->5
输出: 5->4->3->2->1
解决思路:
1.递归函数传递两个参数,head 和 pre,head 保存的是原来的链表,pre 保存的是翻转的链表。
2.在每次递归时,从head上取下来一个节点,然后把 pre 接在该节点后面。
3.在递归到最后时,head 节点为空,而 pre 里面则为翻转好的链表。
class ListNode: #定义节点类
def __init__(self, x):
self.val = x
self.next = None
def reverseList( head, pre = None):
if not head: return pre
cur, head.next = head.next, pre
return reverseList(cur, head)
def printListNode(node): #辅助函数,打印链表
while node:
print(node.val, end=' ')
if node.next:
print('->', end=' ')
node = node.next
print()
if __name__ == '__main__':
head = node = ListNode(1)
for i in range(2,6):
node.next = ListNode(i)
node = node.next
printListNode(head)
ans = reverseList(head)
printListNode(ans)
问题5:链表相加(跟链表杠上了)
一个链表相当于存了一个数,如链表(2 -> 4 -> 3)相当于数字342,我们要做的就是把数读出来,然后相加,再将结果写成链表形式。
输入: (2 -> 4 -> 3) + (5 -> 6 -> 4)
输出: 7 -> 0 -> 8
解释: 342 + 465 = 807.
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
self.prev = None
def printListNode(node): #辅助函数,打印链表
while node:
print(node.val, end=' ')
if node.next:
print('->', end=' ')
node = node.next
print()
def addTwoNumbers( l1: ListNode, l2: ListNode) -> ListNode:
def toint(node):
return node.val + 10 * toint(node.next) if node else 0
def tolist(n):
node = ListNode(n % 10)
if n >= 10:
node.next = tolist(n // 10)
return node
return tolist(toint(l1) + toint(l2))
if __name__ == '__main__':
head1 = node1 = ListNode(1)
for i in range(2,10,2):
node1.next = ListNode(i)
node1 = node1.next
printListNode(head1)
ans = addTwoNumbers(head1,head1)
printListNode(ans)
最后的最后,渴望变成天使,,,啊呸,最后的最后,我们来分析一下递归问题的时间复杂度和空间复杂度,这也是一个需要我们下功夫思考的地方,那么,Let’s begin!
- 时间复杂度:
递归问题时间复杂度可以由一个公式来表示:
其中,为递归问题的时间复杂度, 表示为该问题共调用递归函数的次数(递归花时间,一般问题出在这里。重复计算导致计算机吐血而亡,GG前,面对电脑前的你,带着疑惑和不甘,向你道出了最后的遗言:“我跟你...咳咳...什么仇什么怨,我如此强大的计算能力,咳咳,精通千万种高级计算方法,你为什么要...咳咳...要让我算1+1算到死?”。这时,你会如何回答?),而表示单个递归函数的时间复杂度。很好理解吧~
在此,我给大家列两个例子,方便各位理解:
例子1:我们来一起重温一下问题1,字符串翻转问题。每次我们取出两个字符,剩下的继续调用递归函数,那么我们需要调用n/2次(n代表字符串长度),那么可得。在每个递归函数当中,我们只做了一个交换动作,s[begin], s[end] = s[end], s[begin],所以时间复杂度为,那么,该算法的复杂度便为:是不是很简单呢?
例子2:大家可以回想一下斐波那契数列,如果我们用递归来表示的话,可以得到如下公式: 看起来,好像的复杂度也是,但是!但是!但是!他的复杂度为!因为当它计算到第n个数时,需要调用该递归函数共次!
如下图所示(为了表示方便,我们在该数列前面加上一个数字0),我们要得到f(4),那么需要计算f(2)和f(3),而计算f(3),我们又需要再算一遍f(2)!从图中可以看出,通过这种方式计算,调用递归函数次数是指数级上升的!那么,当你回想问题3当中的杨辉三角形时,会不会发现了什么异曲同工之处?那么,如何解决这种指数爆炸问题,是不是各位老爷也心中有数了呢?(是的,就是加入记忆机制,把之前计算结果全部保存下来即可~这时你会惊奇的发现,时间复杂度变成了!
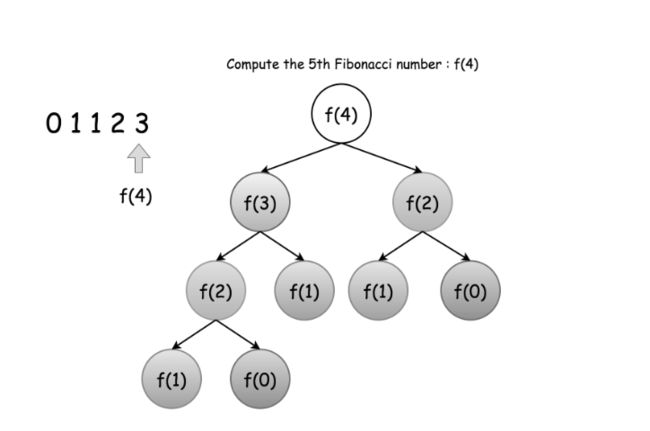 斐波那契数列计算.png
斐波那契数列计算.png
- 空间复杂度:
空间复杂度我们也是分两部分来考虑,一部分是递归相关的空间,另一部分是非递归相关的空间。
递归相关空间:每次调用递归函数时,计算机都会从一个栈(stack)当中给该函数分配一些空间,如,当该函数执行结束时,需要返回原先运算的地方,这便需要一块内存来存储之前中断的位置(计算机需要该地址,才知道该函数执行结束后,从哪里开始下一步运算),还有传递给该递归函数的参数,以及该函数的局部变量等等,这些都是跟递归相关的空间使用。
如果只是一个普通的函数,那么当他运行完之后,该空间就会被释放,但是对于递归调用来说,直到遇到边界条件之前,所有被调用到的递归函数占用的空间都不会被释放,相当于每调用一次递归函数,空间使用是累计增加的。所以如果不注意,便会遇到 “stack overflow”的场景。
对于问题1当中的字符串翻转问题来说,递归函数里只进行了一步交换元素位置的操作,所以需要的额外空间为,递归共进行了n次,所以该算法的递归相关空间的复杂度为。
非递归相关空间:这部分空间指的是不直接跟递归相关的那部分空间使用情况。诸如全局变量(常储存在堆(heap)当中),如我们为了克服重复计算问题,所加入的记忆机制,还有算法程序的输入以及输出数据所占用的空间等。
尾递归(Tail Recursion)
有一种递归较为特殊,叫尾递归。在此简单讲解一下:尾递归是一种递归,其中递归调用是递归函数中的最后一条指令。 并且函数中应该只有一个递归调用。说白了,其他地方不能出现递归调用,只能是最后一句是递归调用。那么,这么搞到底有什么好处呢?大家先来看两个例子(功能很简单,列表求和):
def sum_non_tail_recursion(ls):
"""
:type ls: List[int]
:rtype: int, the sum of the input list.
"""
if len(ls) == 0:
return 0
# not a tail recursion because it does some computation after the recursive call returned.
return ls[0] + sum_non_tail_recursion(ls[1:])
def sum_tail_recursion(ls):
"""
:type ls: List[int]
:rtype: int, the sum of the input list.
"""
def helper(ls, acc):
if len(ls) == 0:
return acc
# this is a tail recursion because the final instruction is a recursive call.
return helper(ls[1:], ls[0] + acc)
return helper(ls, 0)
第一个便不是尾递归,虽然递归调用只出现了一次且出现在最后一句,即return语句里,但是,该return里面还包含了加法运算,相当于是先递归调用,再计算加法,然后把该加法结果返回。这样子看,最后一步运算确实不是递归调用。
那么大家明白了什么是尾递归,可能就有疑惑了,这么做到底有啥好处,代码变得略复杂了,并且还多了个参数,那么这么做到底能得到什么呢?答案就是,极大的降低了空间复杂度!各位懵逼的少年,且听我慢慢道来:
从前有座山,山上呢有座庙,庙里呢,有个老和尚...(此处省略十万八千字),于是,琦玉老师对杰诺斯说到,假设,我们的递归函数为,如果我们的递归调用如下:
那么正常情况下,代码运行结束前,每次调用需要开辟一块空间,最终需要开辟n块空间才行。即空间复杂度为。但是如果是尾递归呢?我们只需要开辟两块空间,空间复杂度骤降为!
因为尾递归函数在递归结束时不需要再进行任何计算,直接将结果返回给上一层递归函数,那么也就意味着,递归到的时候,可以直接将返回值送给,而不是!那么,当我计算完的时候,函数所占用的内存便可以释放掉,无需保留!
杰诺斯赶紧拿小本本记下来,心中想道,这可能就是老师这么强的原因,我要赶快记下来才行。
当然,还有一点需要提醒一下大家,那就是这种内存优化是需要看语言的。C 以及 C++ 都支持尾递归的这种优化方式,但是据我所知,Java 和 Python 好像还不行(当然不排除以后会支持)。所以当你所使用的语言不支持时,什么尾不尾的,那都是浮云一片~
总结:
接下来说三点递归算法使用小贴士:
- 毫无疑问,首先写下递归关系式。
- 只要有可能,咱就用记忆机制。
- 当发生stack overflow 的时候,尝试使用尾递归。
附注:
Answer 1. 你向濒死的计算机冷笑道:“谁让你只认识 0 和 1 两个数呢”。
Answer 2. 你掏出了另一台闪闪发光的计算机,“对不起,我有新欢了。”
Answer 3. 你语重心长、态度坚定的说到:“为了实现中华民族伟大复兴。”
各位看官老爷,希望可以不吝赐教,如有不妥之处还望指出~
也热切希望大家可以给个小赞,或点个关注!
在此谢谢各位爷勒~