Redis的优缺点
优点:
- 速度快,因为数据存在内存中
- 支持数据持久化,支持AOF和RDB两种持久化方式
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
- 数据结构丰富:除了支持String类型的value外还支持Hash、Set、Sortedset、List等。
缺点:
- 内存数据库,单机存储的数据量有限。虽然Redis本身有key过期策略,但是还需要提前预估和节约
内存。如果内存增长过快,需要定期删除数据。
- 如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗现网的带宽。
不过Redis2.8以后版本,已经有部分重同步的功能,但是还是有可能有完整重同步的。比如,新上线
的备机,主从同步失败。
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,Redis不能提供
服务
单线程的Redis为什么如此快
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换,
- 采用了非阻塞I/O多路复用机制

IO多路复用示意图
配图说明: redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中
Redis的数据类型,使用场景,实现方式
Redis 最为常用的数据类型主要有以下五种:String、Hash、List、Set、Sorted set
一些高级特性:HyperLogLog、BItMap、GeoHash、Stream
命令参考网站: http://doc.redisfans.com/
Redis的数据类型,String
1. 常用命令:
Set、Get、Decr、Incr、Mget、Mset、SetEx、SetNx 等。
更多命令请移步到:http://doc.redisfans.com/string/index.html
2. 应用场景:
String 是最常用的一种数据类型,普通的 key/value 存储都可以归为此类,这里就不
做解释了。
3. 实现方式:
String 在 Redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到
incr、decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding (底层实
现结构)字段为int。
Redis的数据类型,Hash
1. 常用命令:
Hget、Hset、Hgetall、Hscan 等。
更多命令请移步到:http://doc.redisfans.com/hash/index.html
2. 应用场景:
我们简单举个实例来描述下 Hash 的应用场景,比如我们要存储一个用户信息对象数据
3. 实现方式:
Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,
这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,
而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 ziplist,
当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 hash table。
Redis的数据类型,List
1. 常用命令
Lpush、Rpush、Lpop、Rpop、Lrange等。
更多命令请移步到:http://doc.redisfans.com/list/index.html
2. 应用场景:
Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 weibo 的关注列表
粉丝列表,排行榜等都可以用 Redis 的 list 结构来实现. 通过lrange来查询
3. 实现方式:
Redis list 的实现为一个双向链表*(新版是quicklist)*,即可以支持反向查找和遍历,
更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等
也都是用的这个数据结构。
Redis的数据类型,Set
1. 常用命令:
Sadd、Spop、Smembers、Sunion 等。
更多命令请移步到:http://doc.redisfans.com/set/index.html
2. 应用场景:
Redis set 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排
重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且set
提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
3. 实现方式:
set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快
速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
Redis的数据类型,Sorted set
1. 常用命令:
Zadd、Zrange、Zrem、Zcard等。
更多命令请移步到:http://doc.redisfans.com/sorted_set/index.html
2. 应用场景:
Redis sorted set的使用场景与 set 类似,区别是set不是自动有序的,而 sorted set 可以
通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
当你需要一个有序的并且不重复的集合列表,那么可以选择 sorted set 数据结构,比如 weibo
的 timeline 可以以发表时间作为 score 来存储,这样获取就是自动按时间排好序的。
3. 实现方式:
Redis sorted set 的内部使用 HashMap 和跳跃表(SkipList)来保证数据的存储和有序,
HashMap 里放的是成员到 score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap
里存的 score,使用跳跃表的结构可以获得比较高的查找效率,且实现较简单
Redis的内存模型
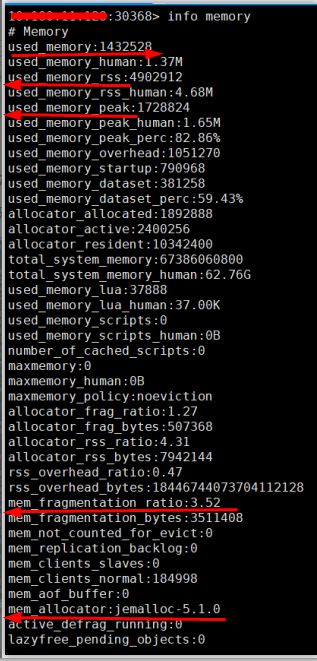
Redis内存消耗统计情况
info详解:https://blog.csdn.net/wufaliang003/article/details/80742978
info命令可以显示redis服务器的许多信息,包括服务器基本信息、
CPU、内存、持久化、客户端连接信息
等等;memory是参数,表示只显示内存相关的信息。返回结果中比较重要的几个说明如下:
1. used_memory:即Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);
used_memory_human只是显示更友好。
2. used_memory_rss:即Redis进程占据操作系统的内存(单位是字节),与top及ps命令看到的值是一
致的;除了分配器分配的内存之外,used_memory_rss还包括进程运行本身需要的内存、内存碎片等,
但是不包括虚拟内存。因此,used_memory和used_memory_rss,前者是从Redis角度得到的量,
后者是从操作系统角度得到的量。二者之所以有所不同,一方面是因为内存碎片和Redis进程运行需要
占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大。
由于在实际应用中,Redis的数据量会比较大,此时进程运行占用的内存与Redis数据量和内存碎片相
比,都会小得多;因此used_memory_rss和used_memory的比例便成了衡量Redis内存碎片率的参数;
这个参数就是mem_fragmentation_ratio。
3. mem_fragmentation_ratio:即内存碎片比率,该值是used_memory_rss / used_memory的比值。
mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。如果mem_fragmentation
_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种
情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内
存、优化应用等。
一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说);左图
中的mem_fragmentation_ratio值有点大,是因为向Redis中存入数据比较少,Redis进程本身运行
的内存使得used_memory_rss 比used_memory大得多。
4. mem_allocator:**即Redis使用的内存分配器,在编译时指定,可以是 libc 、jemalloc或者
tcmalloc,默认是jemalloc。截图中使用的便是默认的jemalloc。
Redis的内存模型, 内存划分
Redis作为内存数据库,在内存中存储的内容主要是数据(键值对)Redis内存占用主要划分一下几个部分:
-数据
作为数据库,数据是最主要的部分,这部分占用的内存会统计在used_memory中。Redis使用键值对存
储数据,其中的值(对象)包括5种类型:字符串、哈希、列表、集合、有序集合。这5种类型是Redis
对外提供的。实际上,在Redis内部,每种类型可能有2种或更多的内部编码实现。此外,Redis在存
储对象时,并不是直接将数据扔进内存,而是会对对象进行各种包装:如RedisObject、SDS等。
-进程本身运行需要的内存
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等。这部分内存大约几兆,在大多数生产
环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在
used_memory中。另外除了主进程外,Redis创建的子进程运行也会占用内存,如Redis执行AOF、
RDB重写时创建的子进程。当然,这部分内存不属于Redis进程,也不会统计在used_memory和
used_memory_rss中。
-缓冲内存(这部分内存由jemalloc分配,因此会统计在used_memory中)
1. 客户端缓冲区:存储客户端连接的输入输出缓冲;
2. 复制积压缓冲区:用于部分复制功能;
3. AOF缓冲区:用于在进行AOF重写时,保存最近的写入命令。
-内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据更改频繁,而且数据之间
的大小相差很大可能导致Redis释放的空间在物理内存中并没有释放,但Redis又无法有效利用,这
就形成了内存碎片。内存碎片不会统计在used_memory中。内存碎片的产生与对数据进行的操作、
数据的特点等都有关。此外,与使用的内存分配器也有关系——如果内存分配器设计合理,可以尽可能
的减少内存碎片的产生。如果Redis服务器中的内存碎片已经很大,可以通过安全重启的方式减小内
存碎片。因为重启之后,Redis重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选
择合适的内存单元,减小内存碎片。
Redis的内存模型, 数据存储细节
1. 概述
关于Redis数据存储的细节,涉及到内存分配器(如jemalloc,tcmalloc)、简单动态字符串(SDS)、
5种对象类型及内部编码、RedisObject。在讲述具体内容之前,先说明一下这几个概念之间的关系。
下图是执行set hello world时,所涉及到的数据模型。
(1)dictEntry:Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指
向Key和Value的指针;next指向下一个dictEntry
(2)Key:“hello”并不是直接以字符串存储,而是存储在SDS结构中。
(3)redisObject:Value(“world”)既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,
而是存储在redisObject中。实际上,Value都是通过RedisObject来存储的;而RedisObject中的type
字段指明了Value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了
RedisObject的包装,但仍然需要通过SDS存储。
RedisObject除了type和ptr字段以外,还有用于指定对象内部编码的字段。
(4)jemalloc:无论是DictEntry对象,还是RedisObject、SDS对象,都需要内存分配器(如jemalloc
)分配内存进行存储。以DictEntry对象为例,有3个指针组成,在64位机器下占24个字节,jemalloc会
为它分配32字节大小的内存单元。

set hello world涉及数据类型
2. jemalloc概述
Redis在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc或者tcmalloc,默认是
jemalloc。
jemalloc作为Redis的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc在64位系统
中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存
储数据时,会选择大小最合适的内存块进行存储。
jemalloc划分的内存单元如下图所示:
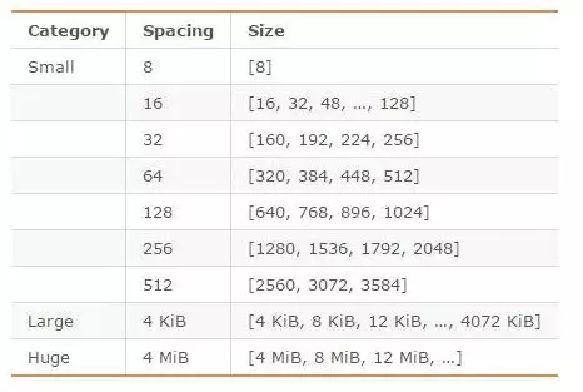
jemalloc内存单元规格图
配图说明:
1.Small Object 的size以8字节,16字节,32字节等分隔开,小于页大小;
2.Large Object 的size以分页为单位,等差间隔排列,小于chunk的大小;3.Huge Object 的大小是chunk大小的整数倍。
对于64位系统,一般chunk大小为4M,页大小为4K
3. RedisObject概述
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过RedisObject对
象进行存储。
RedisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要
RedisObject支持,下面将通过RedisObject的结构来说明它是如何起作用的。
RedisObject的定义如下:
#define OBJ_SHARED_REFCOUNT INT_MAX
typedef struct redisObject {
unsigned type:4; //4bit
unsigned encoding:4; //4bit
unsigned lru:LRU_BITS; //4bit
/* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //4byte
void *ptr; //8byte
} robj;
(1)type
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、
REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型。如下图所示:

type类型示意图
(2)encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码
通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵
活性和效率。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:

encoding示意图
(3)LRU
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占
24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转
时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了
maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys-lru,那么当Redis内存占用超过
maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
(4)refcount
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数
和内存回收:
-当创建新对象时,refcount初始化为1;
-当有新程序使用该对象时,refcount加1;
-当对象不再被一个新程序使用时,refcount减1;
-当refcount变为0时,对象占用的内存会被释放。
(5)ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
(6)总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;
一个redisObject对象的大小为16字节:4bit+4bit+24bit+4Byte+8Byte=16Byte。

redisObject结构图
Redis的内存模型, 优化内存占用
了解Redis的内存模型,对优化Redis内存占用有很大帮助。下面介绍几种优化场景:
(1)利用jemalloc特性进行优化
由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用
内存很大的变动,在设计时可以利用这一点。例如,如果key的长度如果是8个字节,则SDS为17字节,
jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则
每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此
在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了RedisObject的创建),节省内存空间。
目前Redis中的共享对象只包括10000个整数(0-9999),可以通过调整REDIS_SHARED_INTEGERS参
数提高共享对象的个数。例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可
以共享。
考虑这样一种场景: Redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,
这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影
响到代码的复杂度、可维护性。如果数据量较小,那么为了节省内存而使得代码的开发、维护变得
更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是
如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
Redis的内存模型, 关于内存碎片率
内存碎片率是一个重要的参数,对Redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重。这时便可以考
虑重启Redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明Redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取
速度比物理内存差很多(2-3个数量级),此时Redis的访问速度可能会变得很慢。因此必须设法增大物理
内存(可以增加服务器节点数量,或提高单机内存),或减少Redis中的数据。
要减少Redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策
略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
Redis的内存管理与数据淘汰机制
最大内存设置
默认情况下,在32位OS中,Redis最大使用3GB的内存,在64位OS中则没有限制。
在使用Redis时,应该对数据占用的最大空间有一个基本准确的预估,并为Redis设定最大使用的内存。
否则在64位OS中Redis会无限制地占用内存(当物理内存被占满后会使用swap空间),容易引发各种各样的问题。
通过如下配置控制Redis使用的最大内存:maxmemory 100mb
在内存占用达到了maxmemory后,再向Redis写入数据时,Redis会:
"根据配置的数据淘汰策略尝试淘汰数据,释放空间"
如果没有数据可以淘汰,或者没有配置数据淘汰策略,那么Redis会对所有写请求返回错误,但读请求
仍然可以正常执行
在为Redis设置maxmemory时,需要注意:
"如果采用了Redis的主从同步,主节点向从节点同步数据时,会占用掉一部分内存空间,如果
maxmemory过于接近主机的可用内存,导致数据同步时内存不足。所以设置的maxmemory不要过于接近
主机可用的内存,留出一部分预留用作主从同步。"
数据淘汰机制
Redis提供了5种数据淘汰策略:
"volatile-lru:使用LRU算法进行数据淘汰(淘汰上次使用时间最早的,且使用次数最少的key),
只淘汰设定了有效期的key
allkeys-lru:使用LRU算法进行数据淘汰,所有的key都可以被淘汰
volatile-random:随机淘汰数据,只淘汰设定了有效期的key
allkeys-random:随机淘汰数据,所有的key都可以被淘汰
volatile-ttl:淘汰剩余有效期最短的key"
最好为Redis指定一种有效的数据淘汰策略以配合maxmemory设置,避免在内存使用满后发生写入失败的
情况。
一般来说,推荐使用的策略是volatile-lru,并辨识Redis中保存的数据的重要性。对于那些重要的,
绝对不能丢弃的数据(如配置类数据等),应不设置有效期,这样Redis就永远不会淘汰这些数据。对于那
些相对不是那么重要的,并且能够热加载的数据(比如缓存最近登录的用户信息,当在Redis中找不到时,
程序会去DB中读取),可以设置上有效期,这样在内存不够时Redis就会淘汰这部分数据。
配置方法:
"maxmemory-policy volatile-lru #默认是noeviction,即不进行数据淘汰"
Redis的持久化
Redis提供了将数据定期自动持久化至硬盘的能力,包括"RDB和AOF"两种方案,两种方案分别有其长处和短
板,可以配合起来同时运行,确保数据的稳定性。
必须使用数据持久化吗?
"Redis的数据持久化机制是可以关闭的。如果你只把Redis作为缓存服务使用,Redis中存储的所有数
据都不是该数据的主体而仅仅是同步过来的备份,那么可以关闭Redis的数据持久化机制。"
但通常来说,仍然建议至少开启RDB方式的数据持久化,因为:
"RDB方式的持久化几乎不损耗Redis本身的性能,在进行RDB持久化时,Redis主进程唯一需要做的事
情就是fork出一个子进程,所有持久化工作都由子进程完成"
Redis无论因为什么原因crash掉之后,重启时能够自动恢复到上一次RDB快照中记录的数据。这省去了手
动从其他数据源(如DB)同步数据的过程,而且要比其他任何的数据恢复方式都要快
RDB
采用RDB持久方式,Redis会定期保存数据快照至一个rbd文件中,并在启动时自动加载rdb文件,恢复
之前保存的数据。可以在配置文件中配置Redis进行快照保存的时机:
"save [seconds] [changes]"
意为在[seconds]秒内如果发生了[changes]次数据修改,则进行一次RDB快照保存,例如
save 60 100
会让Redis每60秒检查一次数据变更情况,如果发生了100次或以上的数据变更,则进行RDB快照保存。
可以配置多条save指令,让Redis执行多级的快照保存策略。
Redis默认开启RDB快照,默认的RDB策略如下:
"save 900 1"
"save 300 10"
"save 60 10000"
也可以通过BGSAVE命令手工触发RDB快照保存。
RDB的优点:
1.对性能影响最小。Redis在保存RDB快照时会fork出子进程进行,几乎不影响Redis处理客户端请求的效
率。
2.每次快照会生成一个完整的数据快照文件,所以可以以其他手段保存多个时间点的快照(例如把每天0
点的快照备份至其他存储媒介中),作为非常可靠的灾难恢复手段。
"使用RDB文件进行数据恢复比使用AOF要快很多。"
RDB的缺点:
1.快照是定期生成的,所以在Redis crash时或多或少会丢失一部分数据。
2.如果数据集非常大且CPU不够强(比如单核CPU),Redis在fork子进程时可能会消耗相对较长的时间
(长至1秒),影响这期间的客户端请求。
AOF
采用AOF持久方式时,Redis会把每一个写请求都记录在一个日志文件里。在Redis重启时,会把AOF文
件中记录的所有写操作顺序执行一遍,确保数据恢复到最新。
AOF默认是关闭的,如要开启,进行如下配置:appendonly yes
AOF提供了三种fsync配置,always/everysec/no,通过配置项[appendfsync]指定:
"appendfsync no:不进行fsync,将flush文件的时机交给OS决定,速度最快
appendfsync always:每写入一条日志就进行一次fsync操作,数据安全性最高,但速度最慢
appendfsync everysec:折中的做法,交由后台线程每秒fsync一次"
随着AOF不断地记录写操作日志,必定会出现一些无用的日志,例如某个时间点执行了命令SET key1 abc,
在之后某个时间点又执行了SET key1 bcd,那么第一条命令很显然是没有用的。大量的无用日志会让AOF文
件过大,也会让数据恢复的时间过长。
所以Redis提供了"AOF rewrite"功能,可以重写AOF文件,只保留能够把数据恢复到最新状态的最小写
操作集。
AOF rewrite可以通过BGREWRITEAOF命令触发,也可以配置Redis定期自动进行:
"auto-aof-rewrite-percentage 100"
"auto-aof-rewrite-min-size 64mb"
上面两行配置的含义是,Redis在每次AOF rewrite时,会记录完成rewrite后的AOF日志大小,当AOF日志
大小在该基础上增长了100%后,自动进行AOF rewrite。同时如果增长的大小没有达到64mb,则不会进行
rewrite。
AOF的优点:
1.最安全,在启用appendfsync always时,任何已写入的数据都不会丢失,使用在启用appendfsync
everysec也至多只会丢失1秒的数据。
2.AOF文件在发生断电等问题时也不会损坏,即使出现了某条日志只写入了一半的情况,也可以使用
redis-check-aof工具轻松修复。
3.AOF文件易读,可修改,在进行了某些错误的数据清除操作后,只要AOF文件没有rewrite,就可以把
AOF文件备份出来,把错误的命令删除,然后恢复数据。
AOF的缺点:
1.AOF文件通常比RDB文件更大
2.性能消耗比RDB高
3.数据恢复速度比RDB慢
Redis的高可用
1. Redis Sentinel
Redis Sentinel是社区版本推出的原生高可用解决方案,其部署架构主要包括两部分:Redis Sentinel
集群和Redis数据集群。
其中Redis Sentinel集群是由若干Sentinel节点组成的分布式集群,可以实现故障发现、故障自动转移
、配置中心和客户端通知。Redis Sentinel的节点数量要满足2n+1(n>=1)的奇数个。

Redis Sentinel示意图

Redis Sentinel示意图
优点:
1.Redis Sentinel集群部署简单;
2.能够解决Redis主从模式下的高可用切换问题;
3.很方便实现Redis数据节点的线形扩展,轻松突破Redis自身单线程瓶颈,可极大满足Redis大容量或
高性能的业务需求;
4.可以实现一套Sentinel监控一组Redis数据节点或多组数据节点。
缺点:
1. 部署相对Redis主从模式要复杂一些,原理理解更繁琐;
2. 资源浪费,Redis数据节点中slave节点作为备份节点不提供服务;
3. Redis Sentinel主要是针对Redis数据节点中的主节点的高可用切换,对Redis的数据节点做失败
判定分为主观下线和客观下线两种,对于Redis的从节点有对节点做主观下线操作,并不执行故障
转移。
4. 不能解决读写分离问题,实现起来相对复杂。
2. Redis Cluster
Redis Cluster是社区版推出的Redis分布式集群解决方案,主要解决Redis分布式方面的需求,比如,
当遇到单机内存,并发和流量等瓶颈的时候,Redis Cluster能起到很好的负载均衡的目的。
Redis Cluster集群节点最小配置6个节点以上(3主3从),其中主节点提供读写操作,从节点作为备用
节点,不提供请求,只作为故障转移使用。
Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0~16383个整数槽内,每个节点负责
维护一部分槽以及槽所印映射的键值数据。

Redis Cluster结构示意图

Redis Cluster 节点失败示意图

Redis Cluster结构示意图
优点:
1.无中心架构;
2.数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布;
3.可扩展性:可线性扩展到1000多个节点,节点可动态添加或删除;
4.高可用性:部分节点不可用时,集群仍可用。通过增加Slave做standby数据副本,能够实现故障自动
failover,节点之间通过gossip协议交换状态信息,用投票机制完成Slave到Master的角色提升;
5.降低运维成本,提高系统的扩展性和可用性。
缺点:
1. Client实现复杂,驱动要求实现Smart Client,缓存slots mapping信息并及时更新,提高了开
发难度。
2. 节点会因为某些原因发生阻塞(阻塞时间大于clutser-node-timeout),被判断下线,这种
failover是没有必要的。
3. 数据通过异步复制,不保证数据的强一致性。
4. 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的
情况。
5. Slave在集群中充当“冷备”,不能缓解读压力,当然可以通过SDK的合理设计来提高Slave资源的
利用率。
6. Key批量操作限制,如使用mset、mget目前只支持具有相同slot值的Key执行批量操作。对于映射
为不同slot值的Key由于Keys不支持跨slot查询,所以执行mset、mget、sunion等操作支持不友
好。
7. Key事务操作支持有限,只支持多key在同一节点上的事务操作,当多个Key分布于不同的节点上时
无法使用事务功能。
8. 不支持多数据库空间,单机下的Redis可以支持到16个数据库,集群模式下只能使用1个数据库空间
,即db 0。
9. 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
10. Redis Cluster不建议使用pipeline和multi-keys操作,减少max redirect产生的场景。
总结
本文讲述了Redis的方方面面,但只是从宏观的角度去讲解,后面会分章节去一点点剖析Redis这款高性能
的缓存软件
接下来讲解Redis的字符串源码实现