题目
一、场景
HR想要分析员工的离职原因。(本数据集是造出来的,并非某公司的真实数据。)
二、数据集简介
字段包括:
· Satisfaction Level
· Last evaluation
· Number of projects
· Average monthly hours
· Time spent at the company
· Whether they have had a work accident
· Whether they have had a promotion in the last 5years
· Departments (column sales)
· Salary
· Whether the employee has left
其中left字段是label, 1表示离职了,0表示没有离职。
三、要求
1、通过聚类算法将员工进行分类,并计算每种类别员工的离职率。
2、通过调整聚类模型的参数,尝试找出离职率最高的一类员工。
3、尝试分析离职率最高的这一类员工的特征
这是第一次接触这类业务场景,在聚类算法在这块的应用中,开始时有一些不理解,很容易被监督学习的思维习惯带跑,在完成这次作业的过程中,逐渐对聚类的应用有了新的看法。
数据:
import pandas as pd
data=pd.read_csv('C:\\RAM\\HR_comma_sep.csv')
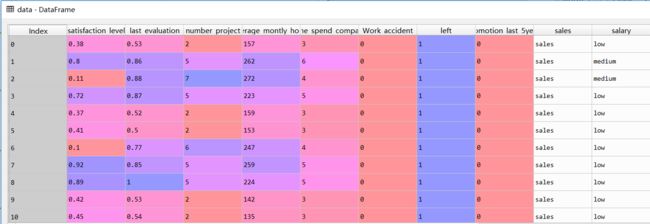

在这里我们发现sales和salary的数据特点时文本数据,因此我们需要建立虚拟变量dummies variable。

dummiescolumns={
'sales':1,'accounting':2,'hr':3,
'technical':4,'support':5,'management':6,
'IT':7,'product_mng':8,'marketing':9,
'RandD':10,'low':1,'medium':2,'high':3}
for column in ['sales','salary']:
column1='量化'+column
data[column1]=data[column].map(dummiescolumns)
建立相关性矩阵
import matplotlib
font={
'family':'SimHei'
}
matplotlib.rc('font',**font)
pd.plotting.scatter_matrix(data,alpha=0.7,figsize=(10,10), diagonal='kde')
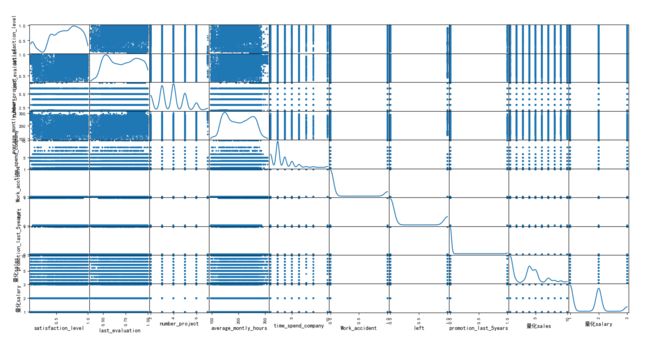
data.corr()
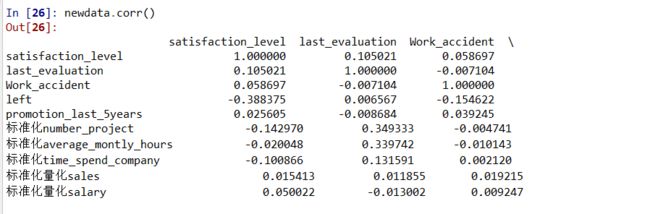
从可视化矩阵图和相关系数矩阵中可以看出,我们目前的特征都是相互独立。
数据标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
for column in ['number_project','average_montly_hours','time_spend_company','量化sales','量化salary']:
column1='标准化'+column
data[column1]=scaler.fit_transform(data[column])
接下来进行,特征筛选
特征筛选主要是剔除掉离散程度不高的变量。
from sklearn.feature_selection import VarianceThreshold
varianceThreshold=VarianceThreshold(threshold = 0.01)
#这里因为我们已经进行了数据标准化,因此我们假设阈值为0.01
varianceThreshold.fit_transform(newdata)

通过特征筛选,我们发现所有特征满足我们的阈值要求。
因为数据维度太大,因此,降维。我们直接降为二维。
from sklearn.decomposition import PCA
colors={
0:'r',
1:'b'
}
markers={
0:'x',
1:'D'
}
pca_2 = PCA(n_components=2)
data_pca_2 = pca_2.fit_transform(newdata)
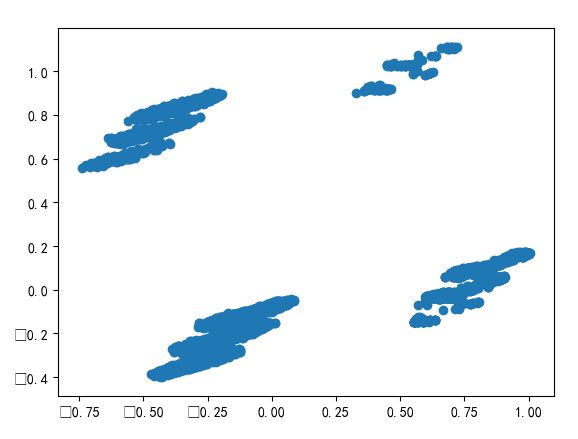
从上图中,我们发现,似乎可以分为四类。
接下来,聚类。
from sklearn.cluster import KMeans
kmModel = KMeans(n_clusters=4)
kmModel = kmModel.fit(newdata)
pTarget = kmModel.predict(newdata)
plt.figure()
plt.scatter(data_pca_2[:,0],data_pca_2[:,1],c=pTarget)
dMean=pd.DataFrame(columns=newcolumns+['分类'])
data_gb = newdata.groupby(pTarget)
for g in data_gb.groups:
rMean=data_gb.get_group(g).mean()
rMean['分类']=g
dMean=dMean.append(rMean,ignore_index=True)
subData=data_gb.get_group(g)
pd.crosstab(pTarget, pTarget)
leftGroup=newdata.groupby(pTarget)['left'].agg({'left':np.sum})
leftGroup['离职率']=leftGroup['left']/newdata['left'].size
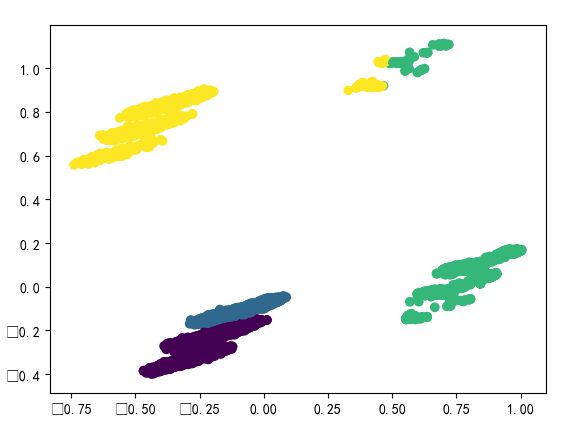


接下来看四类人的离职率
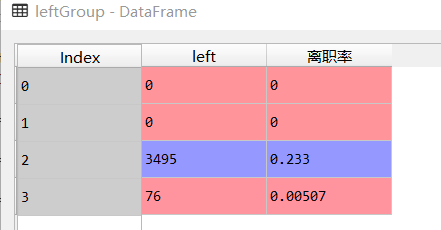
可以看出,第一类和第二类在离职问题上,有共性,离职率为0,第三类人离职率为0.233,第四类人离职率为0.00507。这样看来,分为三类似乎就可以了。
离职率最高一类员工的特征:
featurescolumns=['satisfaction_level',
'last_evaluation',
'Work_accident',
'promotion_last_5years',
'标准化number_project',
'标准化average_montly_hours',
'标准化time_spend_company',
'标准化量化sales',
'标准化量化salary']
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import SelectFromModel
IrModel = LinearRegression()
SelectFromModel = SelectFromModel(IrModel)
SelectFromModel.fit_transform(newdata[featurescolumns],newdata['left'])

