Scrapy框架
构架图
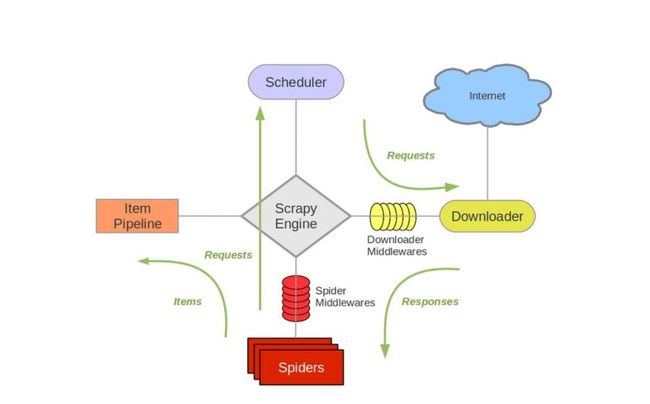
- Scrapy Engine(引擎模块)
- Scheduler(调度模块):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排队、入队,并且在引擎需要时,交换给引擎
- Downloader(下载模块、下载器):负责下载引擎模块发送的所有Requests请求,并将其获取到的Responses交换给引擎模块,由引擎交给Spider来处理
- Spider(爬虫模块):负责处理所有Response,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler
- Item Pipline(管道模块):负责处理Spider中获取的Item,并进行后期处理
1、安装配置
Windows
pip install --upgrade pip
pip install twisted
pip install lxml
pip pywin32
pip install Scrapy
Ubuntu
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
pip install --upgrade pip
sudo pip install scrapy
2、操作步骤
1、scrapy startproject JobSpider
2、cd JobSpider cd spider
3、scrapy genspider 爬虫程序名 域名
4、编写items.py文件
import scrapy
class DoubanmoviesItem(scrapy.Item):
name = scrapy.Field()
score = scrapy.Field()
intro = scrapy.Field()
info = scrapy.Field()
5、编写爬虫文件
import scrapy
from ..items import DoubanmoviesItem
class RunmoviesSpider(scrapy.Spider):
name = 'runMovies'
allowed_domains = ['movie.douban.com']
def parse(self, response):
item = DoubanmoviesItem()
content_list = response.xpath("//div[@class='article']/ol/li/div[@class='item']/div[@class='info']")
next_link = response.xpath("//div[@class='paginator']/span/a/@href").extract()
print(next_link)
for content in content_list:
name = content.xpath(".//div[@class='hd']/a/span[1]/text()").extract()[0]
score = content.xpath(".//div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract()[0].strip()
intro = content.xpath(".//div[@class='bd']/p[1]/text()").extract()[0].strip()
info = content.xpath(".//div[@class='bd']/p[@class='quote']/span[@class='inq']/text()").extract()[0].strip()
if name and score and intro and info:
print(name, score, intro, info)
item["name"] = name
item["score"] = score
item["intro"] = intro
item["info"] = info
yield item
time.sleep(random.randint(0, 2))
if next_link:
url = "https://movie.douban.com/top250" + next_link[len(next_link) - 1]
print(url)
yield scrapy.Request(url=url, callback=self.parse)
6、编写pipelines.py 文件
import pymysql
class DoubanmoviesPipeline(object):
def __init__(self):
# 连接数据库
self.my_conn = pymysql.connect(
host='localhost',
port=3306,
database='douban',
user='root',
password='',
charset='utf8',
)
self.my_cursor = self.my_conn.cursor()
def process_item(self, item, spider):
insert_sql = "insert into movies(`name`,`score`,`intro`,`info`) value(%s,%s,%s,%s)"
print(item["name"], item["score"], item["intro"], item["info"])
self.my_cursor.execute(insert_sql, [item["name"], item["score"], item["intro"], item["info"]])
self.my_conn.commit()
return item
def close_item(self, spider):
self.my_cursor.close()
self.my_conn.close()
7、设置settings.py 文件
- 设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Accept-Language': 'en',
}
- 设置管道文件
ITEM_PIPELINES = {
'doubanMovies.pipelines.DoubanmoviesPipeline': 300,
}
3、细节
1、Item pipeline
可以通过管道处理爬起的数据,在pipelines.py 文件中对传输过来的数据进行筛选
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price']
return item
else:
raise DropItem('Missing price in %s'% item)
将item写入JSON文件
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
去重:给item进行赋id,若id重复,则清除,否则加入。
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem('Duplicate item found: %s' % item)
else:
self.ids_seen.add(item['id'])
return item
2、Link Extractor
引用
from scrapy.contrib.linkextractors import LinkExtractor
参数
- allow (a regular expression (or list of))
- deny (a regular expression (or list of))
- allow_domains(str or list)
- deny_domains(str or list)
- restrict_xpath(str or list)
- attrs(list)
- unique(boolean)
- process_value(callable)
3、Logging
通过scrapy.log 模块使用,必须通过显示调用scrapy.log.start()来开启
- CRITICAL - 严重错误
- ERROR - 一般错误
- WARRING - 警告错误
- INFO - 一般信息
- DEBUG - 调试信息
scrapy.log模块
启动log功能:
scrapy.log.start(logfile=None, loglevel=None, logstdout=None)
记录信息:
scrapy.log.msg(message, level=INFO, spider=None)
scrapy.log.CRITICAL
scrapy.log.ERROR
scrapy.log.WARRING
scrapy.log.INFO
scrapy.log.DEBUG
通过在setting.py中进行以下设置可以被用来配置logging:
1、LOG_ENABLED 默认: True,启用logging
2、LOG_ENCODING 默认: 'utf-8',logging使用的编码
3、LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
4、LOG_LEVEL 默认: 'DEBUG',log的最低级别
5、LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示
4、email
python可以通过smtplib库发送email,scrapy提供了自己的实现。采用了Twisted非阻塞式IO,其避免了对爬虫的非阻塞式IO的影响。
from scrapy.mail import MailSender
mailer = MailSender()
或者可以传递一个Scrapy设置对象,其会参考setting:
mailer = MailSender.from_setting(settings)
mailer.send(to=["[email protected]"], subject="Some subject", body="Some body", cc=["[email protected]"])
MailSender类
class scrapy.mail.MailSender(smtphost=None, mailfrom=None, smtpuser=None, smtppass=None, smtpport=None)
参数:
- smtphost (str) – 发送email的SMTP主机(host)。如果忽略,则使用
MAIL_HOST。 - mailfrom (str) – 用于发送email的地址(address)(填入
From:) 。 如果忽略,则使用MAIL_FROM。 - smtpuser – SMTP用户。如果忽略,则使用
MAIL_USER。 如果未给定,则将不会进行SMTP认证(authentication)。 - smtppass (str) – SMTP认证的密码
- smtpport (int) – SMTP连接的短裤
- smtptls – 强制使用STARTTLS
- smtpssl (boolean) – 强制使用SSL连接
4、scrapy框架爬取图片
1、编写Item文件
import scrapy
class MyItem(scrapy.Item):
# ... other item fields ...
image_urls = scrapy.Field()
images = scrapy.Field()
2、开启图片管道
ITEM_PIPELINES = {'scrapy.contrib.pipeline.images.ImagesPipeline': 1}
3、设置图片存储信息
#图片存储位置
IMAGES_STORE = '/path/to/valid/dir'
# 90天的图片失效期限
IMAGES_EXPIRES = 90
#缩略图信息
IMAGES_THUMBS = {
'small': (50, 50),
'big': (270, 270),
}
4、编写爬虫文件
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import TuxingspiderItem
class TuxingSpider(CrawlSpider):
name = 'tuxing'
allowed_domains = ['so.photophoto.cn']
start_urls = ['http://so.photophoto.cn/tag/%E6%B5%B7%E6%8A%A5']
# 下一页连接
link_next_page = LinkExtractor(restrict_xpaths=("//div[@id='page']/a[@class='pagenexton']/img/@src"))
rules = [
Rule(link_next_page, callback='parse_item', follow=True),
]
def parse_item(self, response):
img_url_list = response.xpath("//ul[@id='list']/li/div[@class='libg']")
for img_url in img_url_list:
item = TuxingspiderItem()
name = img_url.xpath(".//div[@class='text']/div[@class='text2']/a/text()")
url = img_url.xpath(".//div[@class='image']/a/img/@src")
item["name"] = name
item["imagesUrls"] = url
yield item
5、编写pipelines文件
import scrapy
from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.exceptions import DropItem
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item