agenda
- 构建数据和模型
- 数据预处理
- weight初始化
- 正规化(Regularization)
- Loss 函数
数据预处理
- 减均值
假如X是一幅图像(h,w, c): X -= np.mean(X), 若按照颜色通道划分还可以是np.mean(X, axis = 0), 减均值最大的好处就是处理之后的图像数据均值为零.以图像中只包含两个像素为例X = [a, b], Y = X - np.mean(X) = [a - (a + b)/ 2, b - (a + b)/2], E(Y) = (a - (a + b)/ 2 + b - (a + b)/2)/2 = 0, D(Y)确定, 经过减均值后Y服从高斯分布.后面在Xavier初始化中有作用. -
标准化(Normalization)
标准化使得数据在同一个尺度范围内伸缩, 图像X像素值除以标准差, X -= np.std(X, axis = 0).应用这种方法的前提是不同input feature的大小比例不同, 而它们大体相等对学习算法至关重要, 图像的像素范围已经是[0,255],所以通常不必应用标准化,借原笔记的图效果如下:
PCA/Whitening这里就不介绍了(In practice. We mention PCA/Whitening in these notes for completeness, but these transformations are not used with Convolutional Networks.) - weight初始化
2个不正确初始化方式:- 全0. 这样每个神经元的输入都是一样的, 每次反向传播所有参数都经历相同的更新, 每个神经元的差异没有体现
- 接近0的随机数. 因为weight的导数和weight成比例, 很小的weight的导数很小, 再反向传播时把更新杀死了, 造成参数基本不更新,难以收敛.
- Xavier 初始化
随机初始化weight还有一个问题,经过一次神经元运算后输出分布的方差大幅增长.下一层输入个体差异较大, 对于后一层参数训练非常不利, 个体差异巨大的输入对于一个weight的小更新就有可能带来loss的剧烈震荡.
本着控制运算后输出方差的思路: 高斯分布(有正/负向作用参数作用大体相等(均值为0), 参数间的差异是确定的方差). 假如经过一层神经网络后还可以保证方差稳定就达到了目的.
经过了一层线性运算后输出 y = Σ wi*xi + b, W和X独立同分布, 且X经过减均值的预处理已服从高斯分布,那么E(xi) = E(wi) = 0, N是W的行数.
D(y) = D(Σ wi*xi + b) = D(Σ E(wi)^2*D(xi) + E(xi)^2*D(wi) + D(wi)*D(xi)) = Σ D(wi)*D(xi) = N*D(wi)*D(xi)
要保持方差总体不变则 D(y) = D(xi) = N*D(wi)*D(xi) -> D(wi) = 1/N, 所以W服从高斯分布,并且方差是1/N,经过线性运算后方差总体不变.初始化方式可以是:w = np.random.randn(n) / sqrt(n). 实际使用caffe使用了另外一种方式:
可以看到scale = sqrt(3/n), 从区间[-scale, scale]从一个均值分布筛选出来设定的n个数.均值函数概率密度:class XavierFiller : public Filler{ public: explicit XavierFiller(const FillerParameter& param) : Filler (param) {} virtual void Fill(Blob * blob) { // set n by configuration Dtype scale = sqrt(Dtype(3) / n); //通过均值概率出E(W) = 0, D(W) = 1/n的高斯分布 caffe_rng_uniform (blob->count(), -scale, scale, blob->mutable_cpu_data()); CHECK_EQ(this->filler_param_.sparse(), -1) << "Sparsity not supported by this Filler."; } }; void caffe_rng_uniform(const int n, const Dtype a, const Dtype b, Dtype* r) { CHECK_GE(n, 0); CHECK(r); CHECK_LE(a, b); boost::uniform_real random_distribution(a, caffe_nextafter (b)); boost::variate_generator 均值方差如下:
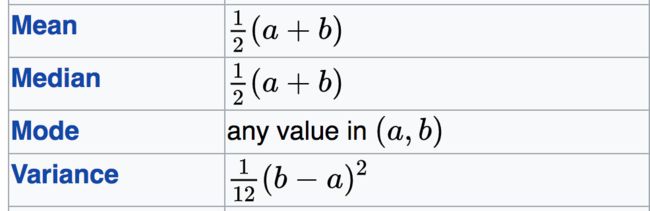
这里b = scale = sqrt(3/n), a = -scale = -sqrt(3/n).可以看出D(W) = 1/12(b - a)^2 = 1/12*(2*sqrt(3/n))^2 = 1/12*4*3/n = 1/n, E(w) = 1/2(a + b) = 0, W是方差为1/n的高斯分布, 至此可以看出caffe是何如通过XavierFiller保证W的方差等于1/n.
再有假如激活函数是常用Relu, 参见Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, w = np.random.randn(n) * sqrt(2.0/n) - 正规化(Regularization)
Regularization作用抑制过拟合的一种技术手段(其他手段包括relu,数据增强), 之前在neural-network-1有提及不能因为过拟合就使用小的网络.Regularization包括L2,L1,Max norm constraints, dropout.- L2 Regularization
最常用的手段, 施加于在loss函数上: new_loss = loss + λ/2n*Σ w^2, 感官上L2的作用是对大的w惩戒严格, 倾向于离散小的w. 使得噪声的作用不那么强烈(we discussed in the Linear Classification section, due to multiplicative interactions between weights and inputs this has the appealing property of encouraging the network to use all of its inputs a little rather that some of its inputs a lot).
还有一点对于L2 W跟新是线性的, d nl/ dw = dl/dw + λ/n*w, 对w的更新变成了
newly w = w - learning_rate*dl/dw - learning_rate*λ/n*w, 这里可以看出对w的更新依然线性.再看下caffe L2的实现:
L1类似于L2, 这里就不细讲了.void SGDSolver::ApplyUpdate() { CHECK(Caffe::root_solver()); Dtype rate = GetLearningRate(); for (int param_id = 0; param_id < this->net_->learnable_params().size(); ++param_id) { //标准化 Normalize(param_id); //正规化 Regularize(param_id); //其实没更新 ComputeUpdateValue(param_id, rate); } //真更新了 this->net_->Update(); } case Caffe::CPU: { if (local_decay) { if (regularization_type == "L2") { // add weight decay y = ax + y = local_decay*w + loss caffe_axpy(net_params[param_id]->count(), local_decay, net_params[param_id]->cpu_data(), // 可修改数据的地址, 内部是static cast, l += local_decay*w, 这里其实就直接计算导数的变化了,至此可以理解问loss更新了 net_params[param_id]->mutable_cpu_diff()); } void SGDSolver ::ComputeUpdateValue(int param_id, Dtype rate) { const vector & net_params_lr = this->net_->params_lr(); //摆脱local minima的加速度 Dtype momentum = this->param_.momentum(); Dtype local_rate = rate * net_params_lr[param_id]; // Compute the update to history, then copy it to the parameter diff. switch (Caffe::mode()) { case Caffe::CPU: { //先改历史数据, y = a*x + y*b = local_rate*loss(包括了L2项) + momentum*w(加速度) caffe_cpu_axpby(net_params[param_id]->count(), local_rate, net_params[param_id]->cpu_diff(), momentum, history_[param_id]->mutable_cpu_data()); //拷贝到cpu_data中, w跟新 caffe_copy(net_params[param_id]->count(), history_[param_id]->cpu_data(), net_params[param_id]->mutable_cpu_diff()); break; } - L2 Regularization
- Max norm constraints
最大范数约束.相当于给参数更新设置了一个边界,防止过度更新,一定程度上防止学习率过高造成训练震荡.这里参考一下Keras的实现.
class MaxNorm(Constraint):
"""MaxNorm weight constraint.
Constrains the weights incident to each hidden unit
to have a norm less than or equal to a desired value.
# Arguments
m: the maximum norm for the incoming weights.
axis: integer, axis along which to calculate weight norms.
For instance, in a `Dense` layer the weight matrix
has shape `(input_dim, output_dim)`,
set `axis` to `0` to constrain each weight vector
of length `(input_dim,)`.
In a `Conv2D` layer with `data_format="channels_last"`,
the weight tensor has shape
`(rows, cols, input_depth, output_depth)`,
set `axis` to `[0, 1, 2]`
to constrain the weights of each filter tensor of size
`(rows, cols, input_depth)`.
# References
- [Dropout: A Simple Way to Prevent Neural Networks from Overfitting Srivastava, Hinton, et al. 2014](http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf)
"""
def __init__(self, max_value=2, axis=0):
self.max_value = max_value
self.axis = axis
def __call__(self, w):
# from . import backend as K
norms = K.sqrt(K.sum(K.square(w), axis=self.axis, keepdims=True))
# 把norm限制在0-max之间
desired = K.clip(norms, 0, self.max_value)
# K.epsilon()是一个极小的随机因子 _EPSILON = 1e-7 the fuzz factor used in numeric expressions
w *= (desired / (K.epsilon() + norms))
return w
def get_config(self):
return {'max_value': self.max_value,
'axis': self.axis}
- Dropout
Dropout is an extremely effective, VGG16中就有用到, Dropout: A Simple Way to Prevent Neural Networks from Overfitting.Dropout的想法是降低神经元之间的内耦, 训练时按照threshold关闭网络, 使用部分网络训练, 极大的降噪.对Dropout后续paper还有Dropout paper和Dropout Training as Adaptive RegularizationAll in all:In practice: It is most common to use a single, global L2 regularization strength that is cross-validated. It is also common to combine this with dropout applied after all layers. The value of (p = 0.5) is a reasonable default, but this can be tuned on validation data.
还是从实际caffe如何做Dropout看下运作:
void DropoutLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();
const int count = bottom[0]->count();
//只在训练时生效
if (this->phase_ == TRAIN) {
// 抹top数据, 按照threshold_置值
caffe_rng_bernoulli(count, 1. - threshold_, mask);
//prototxt里是否设置比例训练
if (scale_train_) {
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] * mask[i] * scale_;
}
} else {
for (int i = 0; i < count; ++i) {
//& mask -> 设置top数据
top_data[i] = bottom_data[i] * mask[i];
}
}
} else {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
if (!scale_train_) {
caffe_scal( count, 1. / scale_, top_data);
}
}
}
- Loss 函数
常见的分类loss之前有讲过, svm和使用cross-entropy的softmax.分类众多时可以考虑参考Hierarchical Softmax.对于属性簇或者回归问题首先考虑是否能够转化成一些独立的分类问题, 直接在回归问题应用L2平方loss比较难训练和脆弱(Notice that this is not the case with Softmax, where the precise value of each score is less important: It only matters that their magnitudes are appropriate. Additionally, the L2 loss is less robust because outliers can introduce huge gradients).