agenda
- 梯度检查
- 功能性检查
- 陪护训练过程
- loss函数
- train/val 准确率
- 参数更新比率
- 激活/梯度 分布
- 可视化
- 参数更新
- SGD, momentum, Nesterov momentum
- 调优lr
- 每个参数适应的lr(adagrad, RMSprop)
- 超参优化
梯度检查
- analysis gradient, 解析梯度. 假如
f(x) ={ x^2}$$$$f'(x) = 2x计算导数时直接代入公式, 故而运算代价较小, 但是会存在计算误差的可能 - numerical gradient, 数值梯度. Taylor expansion如下:f'(x) = \frac{f(x + h) - f(x - h)}{2h}, 当h小于1e-5以下时, 比高数那种公式要准确很多.代价是计算代价较大
思路是用数值梯度衡量解析梯度的准确性.caffe中在test utility有GradientChecker负责检查,自定义添加层的梯度是否计算正确.
这里参考一下, caffe中如何计算解析和数值梯度的.- analysis gradient例子, 交叉熵+softmax(p(x)是已知分布, q(x)是网络预测后通过softmax折射出的概率)
loss = -\sum_i{p(x_i)\log(q(x_i))} = -\log{q(x_k)} k中ground true的分量对应index, 其中q(x)是
q(x_k) = \frac{e^{x_k}} {\sum{e^{x_j}}}
代入其中最后的loss是 loss = -\log{q({x_k})} = -{x_k} + \log{\sum^n{ e^{x_j}}}
对其每一个分量求导
\frac{\partial loss}{\partial x_i}= \begin{cases} q(x_j) - 1 , z_j = z_k \\ q(x_j) , z_j != z_k \\ \end{cases}
caffe在softmax with layer中计算梯度就是直接代入公式求得, 代码如下:
templatevoid SoftmaxWithLossLayer ::Backward_cpu(const vector & propagate_down, const vector (label[i * inner_num_ + j]); if (has_ignore_label_ && label_value == ignore_label_) { for (int c = 0; c < bottom[0]->shape(softmax_axis_); ++c) { bottom_diff[i * dim + c * inner_num_ + j] = 0; } } else { //套交叉熵+softmax导数的数学公式 bottom_diff[i * dim + label_value * inner_num_ + j] -= 1; ++count; } } } // Scale gradient, 针对一个batch的数据 Dtype loss_weight = top[0]->cpu_diff()[0] / get_normalizer(normalization_, count); caffe_scal(prob_.count(), loss_weight, bottom_diff); } - analysis gradient例子, 交叉熵+softmax(p(x)是已知分布, q(x)是网络预测后通过softmax折射出的概率)
- 数值梯度全连接层
全连接层x标识一个batch的一个图像, w是参数矩阵,对w求导即是x
f(x_i, w) = wx + b , f'(x_i, w)_w = x
根据偏导传递的法则, loss对w的导数是
\frac {\partial loss} {\partial w} = \frac {\partial loss} {\partial f} \ast \frac {\partial f} {\partial w} = topdiff \ast \frac {\partial f} {\partial w} = topdiff \ast bottomdata
代码如下, caffe_cpu_gemm完成是通过blas做bottom[0]->mutable_cpu_diff() = 0*bottom[0]->mutable_cpu_diff() + 1*top_diff*bottom_data
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bottom data
caffe_cpu_gemm(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1.,
top_diff, this->blobs_[0]->cpu_data(), (Dtype)0.,
bottom[0]->mutable_cpu_diff());
}
解析梯度和数值梯度的比较, 比较两者差值是不具有参考意义的,绝对小的值并不能体现两者的差距, 用差值比率更有意义.
\frac { \left | f'_a - f'_n \right | } { max(\left | f'_a \right |, \left | f'_n \right |) }
相对错误relative error (RE)的经验统计如下:
* RE > 1e-2, 通常导数计算有错误
* 1e-2 > RE > 1e-4, 不是特别理想误差有点大
* 1e-4 > RE > 1e-7, 假如模型的loss或者激活函数中包含非线性的kinks通常是ok的, 假如没有kinks这个区间还是太大了
* 1e-7 > RE, 这个区间通常比较happy
导数计算用double不用float, 有人发现替换类型RE直接从1e-2数量级降低到1e-8.
-
kinks
kinks指的是目标函数的非线性部分(比如relu的激活函数,svm求loss时的max), 因为在边界时数值梯度和解析梯度存在差异, 以relu为例解析梯度刚好为0, 而数值梯度f(x + h) h < 1e-6可能刚好跨过这个kinks, 引用非零贡献.实际场景中kinks非常频繁出现.
梯度检查的一些tips:- 从一个batch中抽取样本进行梯度检查(use few datapoints), 抽样的道理有点像大数定律, 抽样的梯度检查有问题基本上代表着batch中数据kinks饱和.
- 挑选step size h, h并不是越小越好, 因为有可能陷入精度问题, 有时候h进入h进入[1e-6, 1e-4]区间中, 梯度突然就对了, 笔记中看一下推荐Numerical differentiation
- 梯度充溢于数据分布中, 训练初期w没有规律, loss波动, 这时候进行梯度检查不能反映数据分布.
- 不要被regularization主导loss修正数据. 梯度的主要来自regularization, 这样会隐藏data loss的错误, 所以通常首先loss呈现下降趋势后进行梯度检查关闭regularization, 后面再开启; 或者λ系数开始很小渐渐增强到上届, 这样梯度有错误就会暴露出来.
- 关闭dropout/data argumentation. 每次都是随机的, 会引入大量错误, 但是关闭又不能对他们检查, 一个更好的方式是:强制一个随机概率在计算解析梯度之前校验f(x + h)和f(x - h)
- Check only few dimensions. 抽检一个datapoint的某些dimension的所有参数梯度.(Be careful: One issue to be careful with is to make sure to gradient check a few dimensions for every separate parameter)
训练前检查tips:
Look for correct loss at chance performance.首先单独检查dataloss, 以softmax 10分类 CIFAR-10为例, 初始的loss应该是2.302. 每一个分类的概率是0.1, -log(0.1)=2.302, 假如不是这个值应该好好检查一下原因, 是不是初始化有问题.
Overfit a tiny subset of data. 拿出训练数据的一小部分(比如20的样本).把regularization关闭, 可以很快训练到loss = 0. 即使loss = 0, 也不代表整个训练集可以收敛, 到测试集的泛化. 但是tiny data set都不能zero cost应该好好检查一下
这两点几乎没见过有人这么做过, 都是拿来就训练.-
看护训练过程
我见过大多数的情况都是开启训练后,看log的loss变化, 然后等第二天早上再看.看log有一个不好的地方就是不能体现出随着epoch的变化.-
loss变化
这是原笔记的图:
值得注意的是, 由于削微高的lr, 造成对参数更新过高'能量', 后面难以到达全局最优.
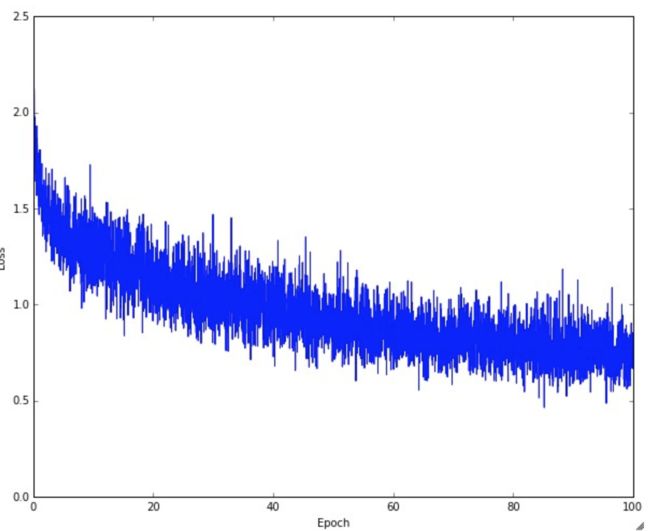
一个typical CIFAR-10的训练过程, loss震荡下降, 但是幅度有点低, 可能是lr削微有点低或者batch size过小. 当batch size是1时, loss震荡会比较明显, batch size是整个训练集时(通常显存放不下)loss曲线会更平滑.
-
train/val 准确率:
比较明显准确率 训练> 验证集, 之前总结常用的技术手段, 增加数据集;加入/加强 L2正则化; 网络假如Dropout;数据增强. 有一个点是最近感悟的: 把图片当做统计学的一个随机分布变量, 训练集和测试集是否是大体同分布(光照, 色差, 角度, crop等等因素), 对于没有精心挑选的训练集并不能真是反应测试集的真是特性, 那么训练就会误入歧途, 自然准确率表现差强人意.
- Ratio of weights:updates
还需要track参数更新大小比率 = |参数更新/参数大小|, 理想的radio是1e-3, 过大或者过小都不理想, 实际中很少人关注这一点. 因为有Dropout的缘故, track min/max的radio容易干扰, 有人统计total更新的比率, 伪代码如下:
# assume parameter vector W and its gradient vector dW param_scale = np.linalg.norm(W.ravel()) update = -learning_rate*dW # simple SGD update update_scale = np.linalg.norm(update.ravel()) W += update # the actual update print update_scale / param_scale # wants 1e-3- Activation / Gradient distributions per layer
不好的参数初始化会阻塞甚至毁掉训练过程, 训练过程中可以已直方图的形式输出激活函数输出或者导数, 理想情况激活在full range均匀分布, 假如大量0输出或者在边界过度饱和都应该终止, 先找到问题原因. -
First-layer Visualizations.
参数可视化输出:
可以看出左边的图表明训练过程是有问题, 可能是low learning rate, L2惩罚项太低.右边是好的分布, 可以看到特征明显,平滑,特征多样性好, 表明训练过程是ok的
还有一个点, 比如识别或者分类不准, 可视化也非常有用, 从最后输出错误score的大头, 返追回feature map, 最终追回原图看看是那部分造成了score的异常
- Parameter updates
这部分是目前比较hot的区域, 对应caffe不同solver和tensorflow的optimizer之前有一篇腾讯同学写的比较清楚.Adam那么棒,为什么还对SGD念念不忘, 基于数据稀疏可以考虑RMSprop, default option是Adam或者SGD + momentum/NAG到达目标区域, 然后再用SGD辅合适的learning rate到达全局最优. 之前看到faster rcnn里面训练hard code就是SGD的solver.
SGD最为基础, 就是dx*lr更新进入参数, 简单看假如参数大体就位了, 用极小的学习率微调最为合适, 伪代码如下:
它也有自己问题: 慢, 容易进入局部最优出不来.# Vanilla update x += - learning_rate * dx
所以就有了momentum, 它训练过程建模成为一个小球在landscape滑动的过程, 抽象出一阶动量和二阶动量, 如何能从局部最优的波谷中跳出来.momentum使用了一阶动量也就是之前的速度累积:# v初始化'0', mu是一个超参通常是0.9, 物理含义是摩擦系数 # Momentum update v = mu * v - learning_rate * dx # integrate velocity x += v # integrate position - Ratio of weights:updates
Nesterov Momentum: 理论上性能好于标准momentum, 实际应用效果更好应用更多. Momentum可以理解为惯性方向和loss梯度下降方向矢量的和, Nesterov core idea是先顺着Momentum方向,然后按着梯度方向更新(Momentum到达的点), 简单示意代码如下:
x_ahead = x + mu * v # evaluate dx_ahead (the gradient at x_ahead instead of at x) v = mu * v - learning_rate * dx_ahead x += v通常梯度计算都是在起始点x进行的,为了和其他形式兼容, 通常以下形式:
v_prev = v # back this up v = mu * v - learning_rate * dx # velocity update stays the same x += -mu * v_prev + (1 + mu) * v # position update changes form后面有个文章详细说明NAG加速:Advances in optimizing Recurrent Networks by Yoshua Bengio, Section 3.5, Ilya Sutskever's thesis (pdf) contains a longer exposition of the topic in section 7.2
-
Per-parameter adaptive learning rate methods: 截至目前为止介绍的方法都是一刀切每一个参数都是按照一个力度调整, 细致优化learning rate又是一个非常消耗的工作,这里介绍几种参数适应的学习方法.
- Adagrad: 持续累积每个参数梯度的开方, 这样等效于learning rate实际等效于越来越小, 而且这个参数累积梯度越大, 更新起到一定的抑制的作用.eps通常在[1e-8,1e-4]中保证不会除0.代码如下:
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
Adagrad一个不好点是单调降低学习率, 过早的停止, 学习停止不前.
RMSprop: 针对稀疏数据比较有用的一种方法, 抑制过早停止学习:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
decay_rate是一个超参,调节下降的强度, RMSprop还是针对每一个参数强度的调优方法.
Adam:截止目前比较流程的方式, 结合了RMSprop和Momentum, 有助于跳出局部最优和独立更新.
# t is your iteration counter going from 1 to infinity
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt / (np.sqrt(vt) + eps)
推荐超参:eps = 1e-8, beta1 = 0.9, beta2 = 0.999.
总结如下: 实际使用中缺省推荐是Adam, 另一种推荐方式SGD + NAG(faster RCNN 代码里也只用SGD, 因为在最有区域SGD+合适的学习率能达到最佳目的地). 实际中训练中持续baby caring训练过程, 多用几个GPU实践不同训练策略.
超参优化
通常我们看到超参优化包括:
* 初始学习率
* decay强度
* 正则化强度
实现: 一个master - worker的工作方式, mater sample一组方式, 让worker训练, 最后用验证集验证性能, master持续迭代参数组合达到最优. 通常找一个足够大的验证集保证模型的性能.
超参范围:初始学习率范围learning_rate = 10 ** uniform(-6, 1), L2正则化强度也是这样生成.