Gluserfs详解
doc home:https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
⚠️本文主要对官网进行了翻译,更方便记录查看,解释有误的地方请大家指出,架构整理和源码详解会在之后相继发布文章。
FUSE
GlusterFS is a userspace filesystem. This was a decision made by the GlusterFS developers initially as getting the modules into linux kernel is a very long and difficult process.
GlusterFS是一个userspace filesystem,这是GlusterFS开发人员最初做出的决定,因为将模块引入linux内核是一个非常漫长和困难的过程。
Being a userspace filesystem, to interact with kernel VFS, GlusterFS makes use of FUSE (File System in Userspace). For a long time, implementation of a userspace filesystem was considered impossible. FUSE was developed as a solution for this. FUSE is a kernel module that support interaction between kernel VFS and non-privileged user applications and it has an API that can be accessed from userspace. Using this API, any type of filesystem can be written using almost any language you prefer as there are many bindings between FUSE and other languages.
作为userspace filesystem,为了与kernel vfs交互,Glusterfs使用了FUSE。FUSE是一个kernel module,支持内核VFS和非特权用户应用程序之间的交互,并且有一个可以从用户空间访问的API,使用这个API,几乎可以使用您喜欢的任何语言来编写任何类型的文件系统,因为在FUSE和其他语言之间有许多绑定
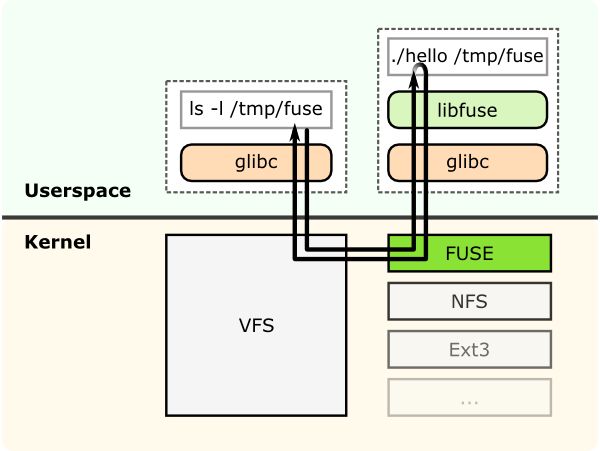
This shows a filesystem "hello world" that is compiled to create a binary "hello". It is executed with a filesystem mount point /tmp/fuse. Then the user issues a command ls -l on the mount point /tmp/fuse. This command reaches VFS via glibc and since the mount /tmp/fuse corresponds to a FUSE based filesystem, VFS passes it over to FUSE module. The FUSE kernel module contacts the actual filesystem binary "hello" after passing through glibc and FUSE library in userspace(libfuse). The result is returned by the "hello" through the same path and reaches the ls -l command.
这显示了一个文件系统“hello world”,它被编译来创建一个二进制“hello”。它是在文件系统挂载点/tmp/fuse上执行的。然后用户在挂载点/tmp/fuse上发出ls -l命令。这个命令通过glibc到达VFS,因为mount /tmp/fuse对应于基于fuse的文件系统,所以VFS将它传递给fuse模块。FUSE内核模块在用户空间(libfuse)中通过glibc和FUSE库之后,与实际的文件系统二进制文件“hello”进行联系。结果由“hello”通过相同的路径返回,并到达ls -l命令。
The communication between FUSE kernel module and the FUSE library(libfuse) is via a special file descriptor which is obtained by opening /dev/fuse. This file can be opened multiple times, and the obtained file descriptor is passed to the mount syscall, to match up the descriptor with the mounted filesystem.
FUSE内核模块与FUSE库(libfuse)之间的通信是通过一个特殊的file descriptor进行的,该file descriptor是通过打开/dev/fuse. .来获取的可以多次打开这个文件,并将获得的file descriptor传递给挂载的syscall,以便将描述符与挂载的文件系统相匹配。
More about userspace filesystems
FUSE reference
Translators
Translating “translators”:
A translator converts requests from users into requests for storage.(将用户请求转换为存储请求)
*One to one, one to many, one to zero (e.g. caching)

- A translator can modify requests on the way through :
==translator可以通过一下方式修改请求==
convert one request type to another ( during the request transfer amongst the translators) modify paths, flags, even data (e.g. encryption)
==将一种请求类型转换为另一种请求类型(在转换器之间的请求传输期间),修改paths、flags甚至data(例如,encryption)== - Translators can intercept or block the requests. (e.g. access control)
==Translators可以拦截或阻止请求(如访问控制)== - Or spawn new requests (e.g. pre-fetch)
==或产生新的请求(如预取)==
How Do Translators Work?
- Shared Objects ==共享对象==
- Dynamically loaded according to 'volfile'
==根据“volfile”动态加载==
dlopen/dlsync setup pointers to parents / children call init (constructor) call IO functions through fops.
==dlopen/dlsync设置指针的父/子调用init(构造函数)通过fops调用IO函数== - Conventions for validating/ passing options, etc.
==约定验证/传递选项等== - The configuration of translators (since GlusterFS 3.1) is managed through the gluster command line interface (cli), so you don't need to know in what order to graph the translators together.
==Translators 配置(自从GlusterFS 3.1)是通过gluster命令行接口(cli)进行管理的,所以不需要知道以什么顺序将这些翻译器组合在一起。==
Types of Translators
List of known translators with their current status.
| Translator Type | Functional Purpose | note |
|---|---|---|
| Storage | Lowest level translator, stores and accesses data from local file system. | Lowest level转换器,存储和访问本地文件系统中的数据 |
| Debug | Provide interface and statistics for errors and debugging | 提供错误和调试的接口和统计信息。 |
| Cluster | Handle distribution and replication of data as it relates to writing to and reading from bricks & nodes. | 处理数据的分布和复制,因为它涉及到对块和节点的写入和读取 |
| Encryption | Extension translators for on-the-fly encryption/decryption of stored data. | 动态加密/解密存储数据的加密扩展 |
| Protocol | Extension translators for client/server communication protocols. | translators 客户端/服务器通信协议的扩展程序 |
| Performance | Tuning translators to adjust for workload and I/O profiles. | 调整translator以适应工作负载和I/O配置文件 |
| Bindings | Add extensibility, e.g. The Python interface written by Jeff Darcy to extend API interaction with GlusterFS. | 添加可扩展性,例如Jeff Darcy编写的Python接口,以扩展与GlusterFS的API交互 |
| System | System access translators, e.g. Interfacing with file system access control. | 文件系统访问接口 |
| Scheduler | I/O schedulers that determine how to distribute new write operations across clustered systems. | I/O调度程序,确定如何跨集群系统分发新的写操作 |
| Features | Add additional features such as Quotas, Filters, Locks, etc. | 添加额外的特性,如配额、过滤器、锁等 |
The default / general hierarchy of translators in vol files :

All the translators hooked together to perform a function is called a graph. The left-set of translators comprises of Client-stack.The right-set of translators comprises of Server-stack.
==所有translator hook在一起执行一个function称作一个graph==
The glusterfs translators can be sub-divided into many categories, but two important categories are - Cluster and Performance translators :
==gluster translator可以分为很多类别,两个重要的类别是Cluster and Performance(性能) translators==
One of the most important and the first translator the data/request has to go through is fuse translator which falls under the category of Mount Translators.
==data/request必须通过的一个translator是fuse translator,它属于Mount translator的范畴。==
- Cluster Translators:
- DHT(Distributed Hash Table)==(分布式Hash Table)==
- AFR(Automatic File Replication)==(自动文本复制)==
- Performance Translators:
- io-cache
- io-threads
- md-cache
- O-B (open behind)
- QR (quick read)
- r-a (read-ahead)
- w-b (write-behind)
例如:gluster volume info查看到
[root@node4 /]# gluster volume info
Volume Name: heketidbstorage
Type: Replicate
Volume ID: d141e423-cc06-4fa5-a7ef-5edbc1b405ce
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: 10.8.4.184:/var/lib/heketi/mounts/vg_cbdb3ac545853d57be6c39db60b7f647/brick_661b5cdd36ee50aaeeeb3490737f2851/brick
Brick2: 10.8.4.182:/var/lib/heketi/mounts/vg_ddfdf2348bf510c356d5234e0ed0a0ec/brick_5ca55df9bbb54e531d6fc4205b297503/brick
Brick3: 10.8.4.183:/var/lib/heketi/mounts/vg_2ceb6870ad884b6507a767308980cf8a/brick_eaa40efdc196a5a18158c79e0b1b0459/brick
Options Reconfigured:
user.heketi.id: 4550c84383c151de59bd6679e73b9117
user.heketi.dbstoragelevel: 1
performance.readdir-ahead: off
performance.io-cache: off
performance.read-ahead: off
performance.strict-o-direct: on
performance.quick-read: off
performance.open-behind: off
performance.write-behind: off
performance.stat-prefetch: off
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
Other Feature Translators include:
- changelog ==(日志更新)==
- locks - GlusterFS has locks translator which provides the following internal locking operations called
inodelk,entrylk, which are used by afr to achieve synchronization of operations on files or directories that conflict with each other.
==locks - GlusterFS,提供了以下称为inodelk、entrylk的内部锁定操作,afr使用这些操作来实现对相互冲突的文件或目录的操作的synchronization== - marker ==(标记)==
- quota ==(配额)==
Debug Translators
- trace - To trace the error logs generated during the communication amongst the translators.
==跟踪translator程序之间通信过程中产生的错误日志== - io-stats ==(io状态)==
DHT(Distributed Hash Table) Translator
What is DHT?
DHT is the real core of how GlusterFS aggregates capacity and performance across multiple servers. Its responsibility is to place each file on exactly one of its subvolumes – unlike either replication (which places copies on all of its subvolumes) or striping (which places pieces onto all of its subvolumes). It’s a routing function, not splitting or copying.
DHT是GlusterFS跨多个服务器聚合容量和性能的真正核心。它的职责是将每个文件精确地放在其中的一个subvolumes(子卷)上——这与replication(将副本放在所有子卷上)和striping(将分片放在所有子卷上)不同。它是一个路由函数,而不是分割或复制。
How DHT works?
The basic method used in DHT is consistent hashing. Each subvolume (brick) is assigned a range within a 32-bit hash space, covering the entire range with no holes or overlaps. Then each file is also assigned a value in that same space, by hashing its name. Exactly one brick will have an assigned range including the file’s hash value, and so the file “should” be on that brick. However, there are many cases where that won’t be the case, such as when the set of bricks (and therefore the range assignment of ranges) has changed since the file was created, or when a brick is nearly full. Much of the complexity in DHT involves these special cases, which we’ll discuss in a moment.
DHT中使用的基本方法是consistent hashing。每一个subvolume(brick)在32-bit hash space分配一个范围,覆盖entire range(整个范围),没有holes or overlaps(漏洞或重叠)。然后,通过hash每个文件的名称,在相同的空间中为每个文件分配一个值。只有一个brick具有指定的范围,包括文件的hash value,因此文件“应该”位于该brick上。但是,在许多情况下,情况并非如此,例如brick集(因此,范围的范围分配)发生了变化,或者brick几乎满了。DHT中的许多复杂性都涉及到这些特殊情况,我们稍后将对此进行讨论
When you open() a file, the distribute translator is giving one piece of information to find your file, the file-name. To determine where that file is, the translator runs the file-name through a hashing algorithm in order to turn that file-name into a number.
当您打开一个file时,distribute translator将会提供一条信息来查找您的文件,即file-name文件名称。为了确定文件的位置,translator通过哈希算法运行文件名,以便将文件名转换为数字。
A few Observations of DHT hash-values assignment:
The assignment of hash ranges to bricks is determined by extended attributes stored on directories, hence distribution is directory-specific.
Consistent hashing is usually thought of as hashing around a circle, but in GlusterFS it’s more linear. There’s no need to “wrap around” at zero, because there’s always a break (between one brick’s range and another’s) at zero.
If a brick is missing, there will be a hole in the hash space. Even worse, if hash ranges are reassigned while a brick is offline, some of the new ranges might overlap with the (now out of date) range stored on that brick, creating a bit of confusion about where files should be.hash范围到brick的分配是由存储在目录中的扩展属性决定的,因此分布是特定于目录的。Consistent hashing is usually thought of as hashing around a circle, but in GlusterFS it’s more linear 但在GlusterFS中它更线性,没有必要在0处“缠绕”,因为在0处总是有一个断点(在一个brick的范围和另brick的范围之间)。如果丢了一个brick,hash space就会有一个洞,更糟糕的是,如果在brick离线时重新分配hash范围,那么一些新的范围可能与brick上存储的(现在已经过时的)范围重叠,从而造成文件应该放在哪里的混乱。
AFR(Automatic File Replication) Translator
The Automatic File Replication (AFR) translator in GlusterFS makes use of the extended attributes to keep track of the file operations.It is responsible for replicating the data across the bricks.
GlusterFS中的AFR使用扩展属性来跟踪文件操作。它负责跨块复制数据
RESPONSIBILITIES OF AFR
Its responsibilities include the following:
- Maintain replication consistency (i.e. Data on both the bricks should be same, even in the cases where there are operations happening on same file/directory in parallel from multiple applications/mount points as long as all the bricks in replica set are up).
保持复制一致性(即两个brick上的数据应该是相同的,即使在多个应用程序/挂载点并行地在相同的文件/目录上发生操作的情况下,只要复制集中的所有brick都已建立)。
- Provide a way of recovering data in case of failures as long as there is at least one brick which has the correct data.
提供一种在发生故障时恢复数据的方法,只要至少有一个brick具有正确的数据。
- Serve fresh data for read/stat/readdir etc.
为read/stat/readdir等提供新的数据
Geo-Replication
Geo-replication provides asynchronous replication of data across geographically distinct locations and was introduced in Glusterfs 3.2. It mainly works across WAN and is used to replicate the entire volume unlike AFR which is intra-cluster replication. This is mainly useful for backup of entire data for disaster recovery.
Geo-replication提供跨地理位置的异步数据复制,这在Glusterfs 3.2中介绍过。它主要跨WAN工作,用于复制整个卷,而不像AFR,它是集群内复制。这主要用于备份整个数据以进行灾难恢复。
Geo-replication uses a master-slave model, whereby replication occurs between Master - a GlusterFS volume and Slave - which can be a local directory or a GlusterFS volume. The slave (local directory or volume is accessed using SSH tunnel).
Geo-replication使用主从模型,在主从(GlusterFS卷)和从(可以是本地目录或GlusterFS卷)之间进行复制。从(本地目录或卷使用SSH隧道访问)。
Geo-replication provides an incremental replication service over Local Area Networks (LANs), Wide Area Network (WANs), and across the Internet.
Geo-replication通过局域网(LANs)、广域网(WANs)和Internet提供增量复制服务。
Geo-replication over LAN
You can configure Geo-replication to mirror data over a Local Area Network.
Geo-replication over WAN
You can configure Geo-replication to replicate data over a Wide Area Network.
Geo-replication over Internet
You can configure Geo-replication to mirror data over the Internet.

Multi-site cascading Geo-replication
You can configure Geo-replication to mirror data in a cascading fashion across multiple sites.

There are mainly two aspects while asynchronously replicating data:
1.Change detection - These include file-operation necessary details. There are two methods to sync the detected changes: ==(两种方法来同步检测到的变化:)==
i. Changelogs - Changelog is a translator which records necessary details for the fops that occur. The changes can be written in binary format or ASCII. There are three category with each category represented by a specific changelog format. All three types of categories are recorded in a single changelog file.
变更日志-变更日志是一个记录发生的fops的必要细节的翻译程序。更改可以用二进制格式或ASCII编写。有三个类别,每个类别由特定的changelog格式表示。所有这三种类型的类别都记录在一个单独的变更日志文件中。
Entry - create(), mkdir(), mknod(), symlink(), link(), rename(), unlink(), rmdir()
Data - write(), writev(), truncate(), ftruncate()
Meta - setattr(), fsetattr(), setxattr(), fsetxattr(), removexattr(), fremovexattr()
In order to record the type of operation and entity underwent, a type identifier is used. Normally, the entity on which the operation is performed would be identified by the pathname, but we choose to use GlusterFS internal file identifier (GFID) instead (as GlusterFS supports GFID based backend and the pathname field may not always be valid and other reasons which are out of scope of this document). Therefore, the format of the record for the three types of operation can be summarized as follows:
为了记录所执行的操作和实体的类型,使用了类型标识符。通常情况下,实体的操作将被执行路径名,但我们选择使用从而内部文件标识符(GFID)而不是(从而支持基于GFID端和路径名字段可能并不总是有效的)。因此,三种操作的记录格式可以概括为:
Entry - GFID + FOP + MODE + UID + GID + PARGFID/BNAME [PARGFID/BNAME]
Meta - GFID of the file
Data - GFID of the file
GFID's are analogous to inodes. Data and Meta fops record the GFID of the entity on which the operation was performed, thereby recording that there was a data/metadata change on the inode. Entry fops record at the minimum a set of six or seven records (depending on the type of operation), that is sufficient to identify what type of operation the entity underwent. Normally this record includes the GFID of the entity, the type of file operation (which is an integer [an enumerated value which is used in Glusterfs]) and the parent GFID and the basename (analogous to parent inode and basename).
GFID类似于inode。数据和元fops记录执行操作的实体的GFID,从而记录inode上的数据/元数据更改。输入fops记录至少有6条或7条记录(取决于操作的类型),这足以确定实体所经历的操作类型。通常,这个记录包括实体的GFID、文件操作的类型(它是一个整数[Glusterfs中使用的枚举值])、父GFID和basename(类似于父inode和basename)。
Changelog file is rolled over after a specific time interval. We then perform processing operations on the file like converting it to understandable/human readable format, keeping private copy of the changelog etc. The library then consumes these logs and serves application requests.
Changelog文件在特定的时间间隔后滚动。然后,我们对文件执行处理操作,例如将其转换为可理解/人类可读的格式,保留更改日志的私有副本等。然后,库使用这些日志并为应用程序请求提供服务。
ii. Xsync - Marker translator maintains an extended attribute “xtime” for each file and directory. Whenever any update happens it would update the xtime attribute of that file and all its ancestors. So the change is propagated from the node (where the change has occurred) all the way to the root.
==Xsync—标记转换器为每个文件和目录维护一个扩展属性“xtime”。每当发生任何更新时,它都会更新该文件及其所有祖先的xtime属性。因此,更改从节点(发生更改的地方)一直传播到根==
 image.png
image.png
Consider the above directory tree structure. At time T1 the master and slave were in sync each other.
 image.png
image.png
At time T2 a new file File2 was created. This will trigger the xtime marking (where xtime is the current timestamp) from File2 upto to the root, i.e, the xtime of File2, Dir3, Dir1 and finally Dir0 all will be updated.在T2时,创建了一个新文件File2。这将触发从File2到根i的xtime标记(其中xtime是当前时间戳)。e, File2的xtime, Dir3, Dir1,最后Dir0都会被更新。
Geo-replication daemon crawls the file system based on the condition that xtime(master) > xtime(slave). Hence in our example it would crawl only the left part of the directory structure since the right part of the directory structure still has equal timestamp. Although the crawling algorithm is fast we still need to crawl a good part of the directory structure.
Geo-replication守护进程根据xtime(主)> xtime(从)的条件抓取文件系统。因此,在我们的示例中,它只会爬行目录结构的左侧部分,因为目录结构的右侧部分仍然具有相同的时间戳。虽然抓取算法比较快,但仍然需要抓取目录结构的一部分。
2.Replication - We use rsync for data replication. Rsync is an external utility which will calculate the diff of the two files and sends this difference from source to sync.
==Replication——我们使用rsync进行数据复制。Rsync是一个外部实用程序,它将计算两个文件的差异,并将这种差异从源文件发送到sync。==
Overall working of GlusterFS
As soon as GlusterFS is installed in a server node, a gluster management daemon(glusterd) binary will be created. This daemon should be running in all participating nodes in the cluster. After starting glusterd, a trusted server pool(TSP) can be created consisting of all storage server nodes (TSP can contain even a single node). Now bricks which are the basic units of storage can be created as export directories in these servers. Any number of bricks from this TSP can be clubbed together to form a volume.
一旦GlusterFS安装到服务器节点上,就会创建一个gluster管理守护进程(glusterd)二进制文件。这个守护进程应该在集群中所有参与节点中运行。启动glusterd之后,可以创建由所有storage server nodes(TSP甚至可以包含单个节点)组成的可信服务器池(TSP)。这个TSP中的任意数量的brick可以被连接在一起形成一个volume。
Once a volume is created, a glusterfsd process starts running in each of the participating brick. Along with this, configuration files known as vol files will be generated inside /var/lib/glusterd/vols/. There will be configuration files corresponding to each brick in the volume. This will contain all the details about that particular brick. Configuration file required by a client process will also be created. Now our filesystem is ready to use. We can mount this volume on a client machine very easily as follows and use it like we use a local storage:
创建卷之后,glusterfsd进程将在每个participating brick(参与的brick)中运行。与此同时,将在
/var/lib/glusterd/vol/中生成称为vol的配置文件,将有与volume中的每个brick对应的配置文件。这将包含关于特定砖块的所有细节。还将创建客户机进程所需的配置文件。现在我们的文件系统可以使用了。我们可以很容易地将这个卷挂载在客户端机器上,如下所示,并像使用本地存储一样使用它:
mount.glusterfs:
IP or hostname can be that of any node in the trusted server pool in which the required volume is created.When we mount the volume in the client, the client glusterfs process communicates with the servers’ glusterd process. Server glusterd process sends a configuration file (vol file) containing the list of client translators and another containing the information of each brick in the volume with the help of which the client glusterfs process can now directly communicate with each brick’s glusterfsd process. The setup is now complete and the volume is now ready for client's service.
在客户机中挂载卷时,客户机glusterfs进程与服务器的glusterd进程通信。服务器glusterd进程发送一个配置文件(vol文件),其中包含the list of client translators,另一个配置文件包含卷中每个brick的信息,在此帮助下,客户端glusterfs进程现在可以直接与每个brick的glusterfsd进程通信。安装现在已经完成,卷已经为客户端服务做好了准备。
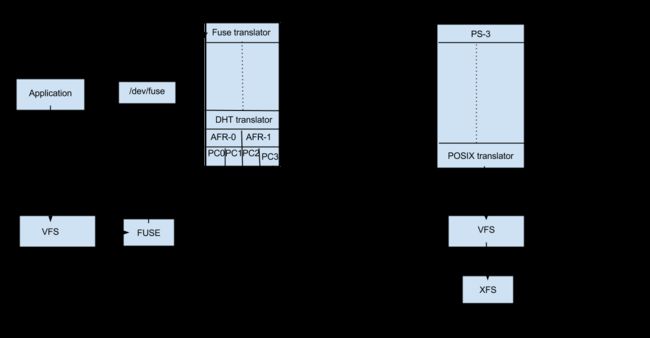 image.png
image.png当客户机在挂载的文件系统中发出系统调用(文件操作或Fop)时,VFS(确定文件系统的类型为glusterfs)将把请求发送到FUSE内核模块。FUSE内核模块将依次通过/dev/fuse将其发送到客户机节点的userspace中的GlusterFS(这在FUSE部分已经描述过了)。客户机上的GlusterFS进程由一组 client translators的translator程序组成,这些translatot在存储服务器glusterd进程发送的配置文件(vol文件)中定义。这些转换器中的第一个是FUSE Translator,它由FUSE库(libfuse)组成。每个translator都具有与glusterfs支持的每个文件操作或fop对应的function。该请求将在每个translator中执行相应的功能。主要client translators包括:
- FUSE translator
- DHT translator- DHT translator maps the request to the correct brick that contains the file or directory required.
- AFR translator- It receives the request from the previous translator and if the volume type is replicate, it duplicates the request and passes it on to the Protocol client translators of the replicas.
- Protocol Client translator- Protocol Client translator is the last in the client translator stack. This translator is divided into multiple threads, one for each brick in the volume. This will directly communicate with the glusterfsd of each brick.
In the storage server node that contains the brick in need, the request again goes through a series of translators known as server translators, main ones being:在storage server node中包含需要的brick,请求再次通过一系列称为server translators的translator,主要有:
- Protocol server translator
- POSIX translator
The request will finally reach VFS and then will communicate with the underlying native filesystem. The response will retrace the same path.请求将最终到达VFS,然后与底层本机文件系统通信。响应将重新跟踪相同的路径。