关键字:分布式事务、数据库
背景:
首先先说下Percolator出现的背景:众所周知Google是一家以技术著称的搜索公司:,而倒排索引又是搜索引擎中最为关键的一个技术,在面对海量数据时,高效的索引创建和索引的实时更新都是必须面对的难题。Google采用MR设计了一个批量创建索引的系统,解决了海量数据索引创建的问题,但是该索引系统不能有效对新增的数据做实时更新。
简单来说论文要表达的是:该方案的索引存储系统不支持跨行事务,不支持随机增量更新。每次需要重新对全量数据进行一次索引创建,这个效率是非常低下的,而且最新的文档是否能被检索到取决于本次全量索引创建的时间,时间间隔较长。
上面这段不理解也没关系---不重要,重要的是作者想要表达的意思: 现在就缺一个支持海量数据存储,支持并行随机读写,支持跨行事务的分布式数据库。
现状:
Bigtable支持海量数据存储,支持随机读写,但是不支持跨行事务。
传统单机型数据库支持随机读写,支持跨行事务,但是不支持分布式,无法满足海量数据的存储需求。
而Percolator能有效的结合两者的优点:分布式,随机读写,支持事务的分布式数据库。(依托Bigtable实现)
另外论文提到,因为Percolator事务设计模型考虑的主要因素是吞吐而不是延时,决定了它的事务处理延时性可能会较高,不如传统关系型数据库那么高效,因为本身的设计初衷是对海量数据创建索引,以吞吐为第一目标。
Percolator其实是构建在Bigtable之上,Bigtable本身是支持海量数据随机读写,提供单行级别的事务的,Percolator利用了Bigtable的优点,也因此保留了很多Bigtable的接口,需要特别注意的一点:Percolator中为事务提供支持的元数据是列的方式存储在Bigtable对应的行中。可以认为Percolator为每行记录都新增了一些隐藏列,这些列保证了事务的正确执行或回滚。
Percolator简单介绍:
下面我们来先简单看看Percolator中的一些设计点。
隔离级别:
Percolator提供跨表、跨行的分布式事务,隔离级别为快照隔离(snapshot-isolation)。快照隔离级别中,如果两个事务同时修改同一个行,那么事务冲突,其中一个事务必须回滚然后重试。
首先我们先来简单看一下快照隔离(snapshot-isolation),也可以参考上篇文章隔离级别简单介绍。
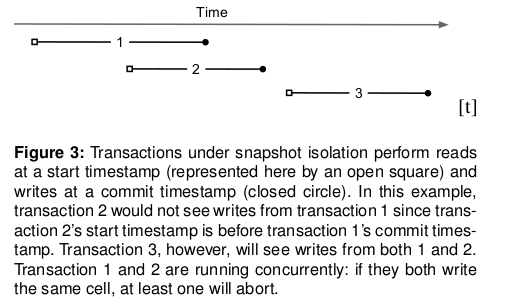
Percolator依赖Bigtable的timestamp来提供基于时间戳的多版本支持mvcc,快照隔离(snapshot-isolation)的实现需要mvcc来提供支持。快照隔离需要能够有效的处理写冲突,当有一个事务A和一个事务B同时写入同一个cell时,最多只有一个能提交成功。但是快照隔离并不满足serializability隔离级别,而且存在write skew的问题,但是相对比serializability隔离级别,快照隔离的好处是:提供更高效的读性能。可以认为:任何一个时间戳都对应一个快照,读取一个cell时,只需要根据指定的时间戳从Bigtable中找到对应的版本即可,并不需要获取读锁。下图展示了快照隔离下多个事务各自执行的状态:
锁的实现:
因为Percolator是通过Bigtable来访问数据,并不是直接访问底层数据存储,所以Percolator跟PDBMS(分布式数据库?)有些不同,别的并行数据库中锁就是系统组件的一部分,控制节点和数据节点就在一起,每个节点node都可以直接访问自己磁盘上的数据,锁的分配由该node自己来决定,可以直接对数据进行锁操作。
而Percolator则是通过访问Bigtable,每个节点都需要向Bigtable发送数据请求,因此没有很有效的获取锁的方式(个人理解,作者想要表达的意思应该是:上面所说的数据库每个节点既是控制节点,又是数据节点,该节点上的数据就由该节点来控制,而Percolator访问数据时,则需要通过Bigtable,而且Bigtable中数据也不是直接由Bigtable的节点来控制的,数据是存储在GFS上面的,B
igtable中的节点和GFS的节点可以是完全不同的两套集群,通过rpc通讯
),所以Percolator必须自己显式的来维护锁。那么就有了如下要求:
1.锁必须能够在机器宕机时依然可见。
2.锁服务必须能够提供高吞吐。
3.锁服务也必须满足低延迟。
考虑到上述需求,锁必须满足:replicated、distributed、balanced属性,而Bigtable本身就提供这些属性,所以Percolator直接将锁保存在Bigtable的额外的多个新的内存列中(称之为meta数据,主要就两列:一个lock、一个write,另外还有3列:data,notify,ack_O)。
事务的流程:
(这段看不懂没关系,后面可以再看图的解释)
下面我们详细了解一下Percolator的事务流程:事务的发起者首先向时间服务器请求一个timestamp(所有的节点都通过该服务器获取时间戳,这样能够保证所有节点所看到的是时间是全局有序的。时间服务器如何实现不知道,hahah),表示事务开始的时间,get读操作通过这个timestamp来决定读取的数据的版本,set写操作的数据则一直缓存到commit的时候再提交。
事务提交采用两阶段提交(分布式事务多是采用这种方式,note:两阶段和提交和两阶段锁并不一样)。两阶段提交通过client来协调。具体client是什么节点论文并没有解释,但是并不影响我们理解论文,可以简单理解client就是发起并执行事务流程的节点。
在提交的第一个阶段(prewrite):我们首先获取所有需要写入的cell的锁(考虑到client故障情况,我们会任意指定一个lock为primary,后面详细讨论),每个事务都会读取meta数据来检测事务是否存在冲突。
有两种冲突的情况:
1.如果一个事务A看到cell的write列中已经存在一条记录,记录的时间戳晚于该事务开始的时间戳,那么说明存在写冲突,即说明有一个事务在A发起之后更新了cell的值,事务A需要aborted。
2.如果事务看到cell的lock列中存在任意一条锁记录,不管时间戳为多少,直接aborted。(这里需要说明一点:因为事务执行过程中有可能会失败,事务A看到的lock有可能是失败的事务B留下来的,这种lock是需要清除的,事务A此时是不应该aborted的,这里说的直接aborted,个人理解应该是不考虑失败事务的情况,即假设看到是锁都是正在进行事务操作的锁)
如果两种冲突都不存在,那么我们更新cell,并向lock列中写入上锁信息。理解这两个判断条件需要了解快照隔离级别下哪些会判断事务发生冲突。
如果没有cell冲突,那么说明事务可以提交,进行下一个阶段commit:首先client会向时间服务器申请一个timestamp,表示commit的时间。然后client会释放事务中涉及的所有cell的锁(清空lock列),释放顺序从primary lock开始。
释放锁之后便更新write列来使新的read能够读到本次事务的数据。write列的数据表示:本次事务的数据已经成功更新至cell中,write列中的数据包含了一个timestamp,该timestamp表示本次事务数据的timestamp,用户可以通过该timestamp来找到数据。一旦primary锁对应记录的write列数据可见了,代表该事务一定已经commit了,reader此时能看到该事务的数据。

个人理解
相信大家看了前面这些精心的翻译和详细的解释,一定还是看不懂的^ ^,写的是个啥!!!下面是笔者个人理解,可以参考,不保证正确,有问题可以提出来共同探讨。
下面我们谈一下上面判断冲突的两个条件,首先我们将并行事务分为3种情况:
1.读-读
由于快照隔离read并不加锁,所以读-读操作并不会冲突,事务并不需要aborted。
2.读-写
而当有读-写情况发生时,执行get操作时,需要检查[0,start_timestamp]之间的lock信息,如果此时lock列中有数据时,说明目前该cell正在被一个事务操作,那么get操作等待该事务完成,lock释放后再读取数据。如果没有发现lock数据,那么get操作获取write列中在[0,start_timestamp]之间最新数据的timestamp,该timestamp指向了该get操作可以访问的最新的数据。这种情况下读事务等待写事务完成,也不会需要aborted。
3.写-写
只有当发生写-写冲突时,才需要将其中的一个事务aborted,而上面的两个判断条件就是判断事务是否存在写-写冲突。
假如事务A需要修改一个cell,但是看到了cell已经存在lock锁,那么说明可能存在事务B正在对cell进行修改,此时事务B处于两阶段提交的第一阶段。两个事务发生冲突,需要aborted。
假如事务A需要修改cell,并且lock列中没有发现有数据,但是write列中有数据,并且该write列的时间戳晚于事务A的开始的时间戳,说明在事务A开始后,有事务B已经修改了cell的值,此时的B处于两阶段提交的第二个阶段或者已经提交成功,存在冲突,事务A需要aborted。
另外如果write列的时间戳早于事务A开始的时间戳的话,说明事务B结束后事务A才开始,这时候就没必要aborted了,所以除了看write列是否有数据外,还要看write列的时间戳是否跟A有冲突。
可能看了上面这些还有点云里雾里,没关系,下面我们直接拿图说话:

首先,假设有两个用户:一个Bob,一个Joe,bob有10块钱,Joe有2块钱,可以看到每条记录都有3列。第一列:数据列,存放用户的账户金额;第二列:lock列,当里面有数据时,说明该列被某事务上锁,并且该事务处于两阶段提交的第一阶段;第三列:write列,当write列有数据时,代表事务已提交,write列前面的数字代表该事务commit的时间,write列@符号后面的数值表示该事务修改后的数据的时间戳(也是事务开始的时间)。比如图中表示目前最新的数据的时间戳为5,Bob时间戳为5的数据中存放的是:10

然后,Bob开始给Joe转账,转7块钱。(具体为什么要转账就不清楚了,有可能是存在py交易吧^ ^)首先该事务会先获取一个开始时间戳,表示事务开始的时间,这里starttime为7,修改data列为3,时间戳为7,并且在lock列中写入lock信息:I am primary我是主锁,并且lock的时间戳也为7。
这里需要注意一下,在分布式环境下,Percolator为了保证容灾,确保事务正常执行完毕或者发生错误时回滚,提出了一个primary lock的概念:一个事务可能涉及多行的修改,两阶段提交的第一阶段,需要对所有行都进行加锁,Percolator会对第一个操作的数据加primary锁,并对后续的数据加slave锁,而且slave锁都会指向primary锁,并且修改需要修改的数据,当所有数据都修改完毕之后,进入第二阶段——commit提交,事务提交时会首先处理primary锁对应的行,并且清空primary锁,如果处理成功,则认为该事务提交成功。注意:只要primary对应的行提交成功,就认为事务提交成功。而提交的操作就是:清空lock列中的信息,并在write列写入新的信息,
假设事务因为某种原因挂了,不论当时事务是处于第一阶段还是第二阶段,部分记录的lock锁信息都是有可能还存在的,那么当后续的事务再访问数据的时候,发现该记录有锁,则会去找对应的primary锁是否还存在(因为slave锁包含有指向primary锁的信息,也就是说一定能找到primary锁的位置),假如发现primary锁依然存在,说明之前事务没有提交成功,这个锁是残留下来的,直接清空,假如primary锁已经不存在了,说明事务已经提交成功,之后后续的操作还没处理完,那么后续的事务必须首先处理之前的未执行完的事务。(primary锁对应行中的write列有事务开始和结束的时间戳等信息,而且slave的数据其实已经被修改,只是还没有提交而已,可以根据这些信息来补全整个事务)

然后Joe的账户中修改data列为:9,lock列添加:primary @ Bob.bal,该信息指向bob中的primary锁,也就是我们上面所说的:假如因为事务失败,Joe中的锁有残留,可以通过lock中的信息来找到primary锁的位置,来判断该事务是否应该继续还是应该丢弃。
注意,到这里为止,都是两阶段提交中的第一阶段。

之后进入两阶段提交的第二阶段:首先Bob清空primary锁信息,并且在自己的write列中添加新字段: data@7,该数据的时间戳为:8,表示该事务提交的时间戳为8,data后面跟的数字7代表事务开始的时间为7,并且也是本次事务对应数据的时间戳。
事务开始的时间戳:其他事务的读操作可以根据lock信息中该事务开始的时间戳来判断是否应该等待该事务完成。
事务结束的时间戳:可以用来判断其他事务是否需要aborted自己事务来避免冲突。

之后Joe也清空自己的lock信息,并且更新write列,当事务涉及数据的操作都执行完毕后,事务结束。
以上图为论文中的图,解释部分是个人理解,若有不对的地方可以指出。
下面是论文中事务故障时的处理流程,上面其实基本已经说完了,大致看一下即可。
故障——事务回滚or回放
下面考虑client故障的情况(Bigtable的 tablet server故障并不会影响系统,因为Bigtable本身就有容灾功能):如果一个事务正在committing的时候,client挂了,lock信息此时会被留下来,Percolator必须对这些lock信息进行清理,否则它们会把后面的事务永久的hang住,Percolator采用了一种lazy的方式进行lock清理:一个事务A碰到了事务B留下来的锁信息之后,A来决定B是否是失败的事务,并且清除掉lock。
为了确保确实是B crash了,并不是因为和A产生了竞争而清除了B的锁。为了确保正确性,我们为每一个事务选取一个cell,并将它上面的锁成为primary lock。A和B都知道事务主锁的位置(因为同一个事务其他cell的lock会记录主锁的位置),所有cleanup或者commit操作都必须从primary lock开始,而且bigtable默认的行锁粒度能够保证不会有多个client同时操作同一行,只会有一个cleanup或者commit操作能提交成功。
尤其是:当B进行commit时,必须检查目前它是否还拥有primary lock。同样在A清理B的lock的时候,必须检查B是否已经commit,也就是primary lock是否已经清除,如果primary lock还在,说明事务还未提交,此时A可以清理B的lock。
当一个事务已经提交,还未执行完,client挂了,就会有一部分lock依然存在,这时就需要进行补救,首先判断primary lock是否存在,如果存在,说明事务没有提交成功,那直接清空lock即可,若primary lock不存在,说明事务已经提交,那么将lock清除,并在write列中补上对应的信息,更新最新可读取的数据的timestamp。
补充:假如事务执行时发现数据已经上锁了,那么如何判断加锁的事务是否依然在健康的执行,还是事务已经失败,锁仅仅是残留下来的?
答案是:通过primary lock可以判断出来,因为bigtable是支持行级事务的,也就是说,假如事务B发现它需要访问的记录已经被事务A上锁,但是不确定事务A是否还在正常运行,那么B可以通过slave锁信息来找到事务A primary锁的行,如果primary锁所在的行能够访问,说明该行没有被上锁,事务A已经挂掉了,此时清空锁信息。如果primary锁对应的记录无法访问,那说明此时事务A正在执行事务,还没有释放primary锁所在记录的行级锁。