微信公众号:命运探知之魔眼
如有问题或建议,请后台留言,我会尽力解决你的问题。

前言
我是人工智障,一名程序猿。做过嵌入式、爬虫,目前在自学计算机视觉 。注册 「命运探知之魔眼」(名字取自影视作品「命运石之门」)这个公号已有些日子,真正有心将它运营起来是看到朋友狗哥运营它的公号「一个优秀的废人」之后。注册这个号的初衷是分享我的 计算机视觉 学习笔记,希望更多的人加入我的行业。
本期内容
本期的案例很有意思,是 Kaggle 上的一个项目,他们采集了当年乘坐泰坦尼克号的成员的信息,这些信息包括乘员的年龄、性别、名字、是否有配偶同坐等,而我们的任务是基于这些信息,预测他们哪些人活下来了,哪些人遇难往生。我们先看看这些数据的分布情况,下一期再来用机器学习的方法分析。下面来看看这个数据集。
Titanic数据集
这个数据集包含 train.csv 和 test.csv 两个 Excel 表格,train.csv 称为训练集,test.csv 称为测试集。
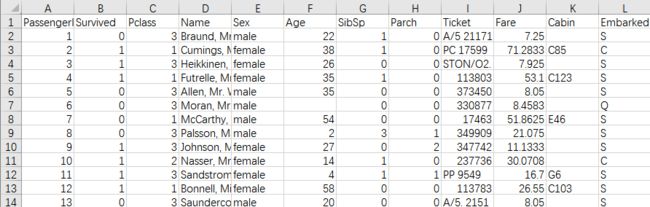

train.csv 比 test.csv 多了一列 Survived ,表示乘员最后是否活下来了。我们的任务是预测他们是否存活,因此需要训练集去训练一个分类器,训练集必须包含正确的预测结果,就像老师教学生的时候,给他们做题和对正确答案,这个“正确答案”称为标签。由于这里的 test.csv 没有标签,所以我把 train.csv 的 70% 作为真正的训练集,而在另外的 30% 上测试准确率,这 30% 也叫作验证集。
各列的意义在 Kaggle 官网上有介绍。
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
数据集处理
在 Python 中读取 csv 文件我使用的是 pandas 库。我想先用年龄和性别看看数据的分布,但是性别在 csv 中是个字符串,所以要把它们换成整数。对于年龄,csv 中的数据是有缺失的,也就是有的人的年龄未知,我的处理方法是用已知的年龄的平均值去填充。
处理的代码如下:
# coding: utf-8
'''
说明:处理Titanic数据集。
作者:rzyang
日期:2018/08/08
'''
import pandas as pd
import numpy as np
# 程序入口
def main():
# 读取csv文件
df = pd.read_csv('train.csv')
# 清洗数据
# 替换性别字符串
df = df.replace({'male':0, 'female':1})
# 年龄缺失值填充为平均年龄
mean_age = int(np.mean(df['Age']))
df['Age'] = df['Age'].fillna(mean_age).astype(np.int32)
# 分割数据集
dataset_size = df.shape[0]
train_size = int(0.7 * dataset_size)
print('dataset size = ', dataset_size)
print('train size = ', train_size)
print('val size = ', dataset_size - train_size)
train_df = df[:train_size]
val_df = df[train_size:]
# 挑选的列
cols = ['Sex', 'Age', 'Survived']
# 保存数据集
train_df.to_csv('real_train.csv', columns=cols)
val_df.to_csv('val.csv', columns=cols)
if __name__ == '__main__':
main()
处理完以后会在当前目录生成 real_train.csv 和 val.csv 两个文件,分别是原来 train.csv 的 70% 和 30% 的数据。
数据分析
根据以往看灾难片的经验,通常发生事故的时候都会有个人跑出来喊一句“妇女和小孩先走!”,因此我会认为性别和年龄是两个很重要的特征。
那就来看看 real_train.csv 中的存活情况怎么样。
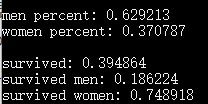
在这个数据集中,男女比例大约是 6:4,整体的存活率是 0.4 左右,虽然男性比女性要多,但是男性的存活率只有 0.186,而女性则有 0.75 左右。所以也许当时真的采用了“妇女先走”的撤离原则。
再来看看年龄的分布怎么样,这里我列出了存活的年龄分布、死亡的年龄分布、存活的男性的年龄分布、存活的女性的年龄分布、死亡的男性的年龄分布以及死亡的女性的年龄分布。
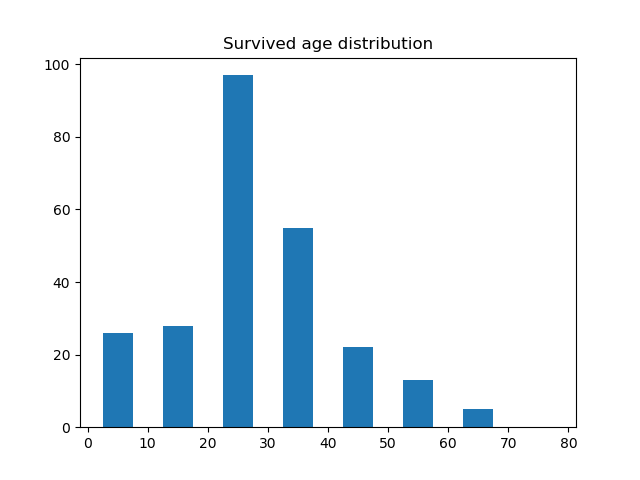
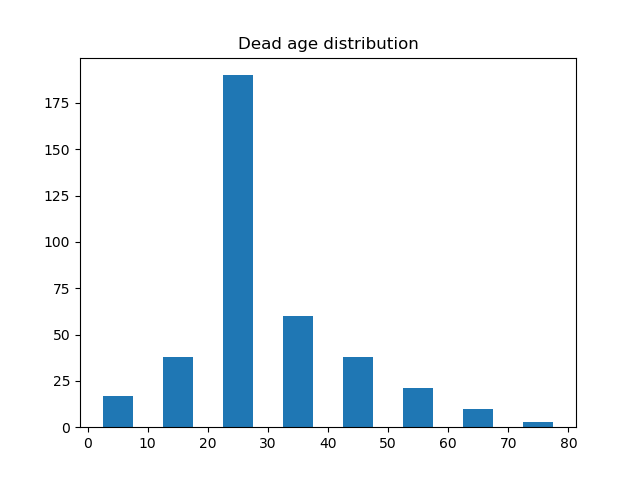
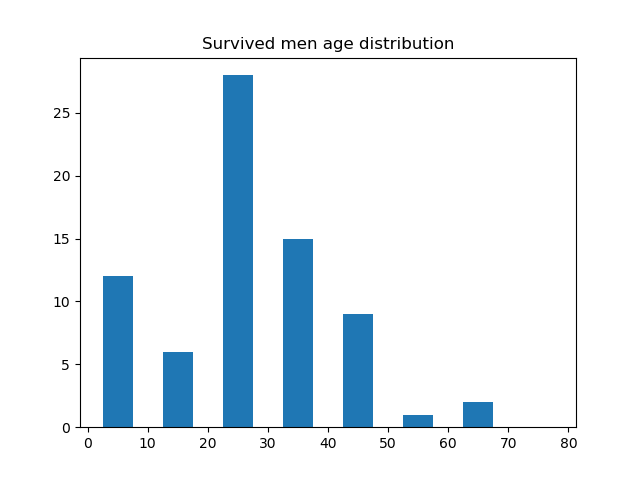
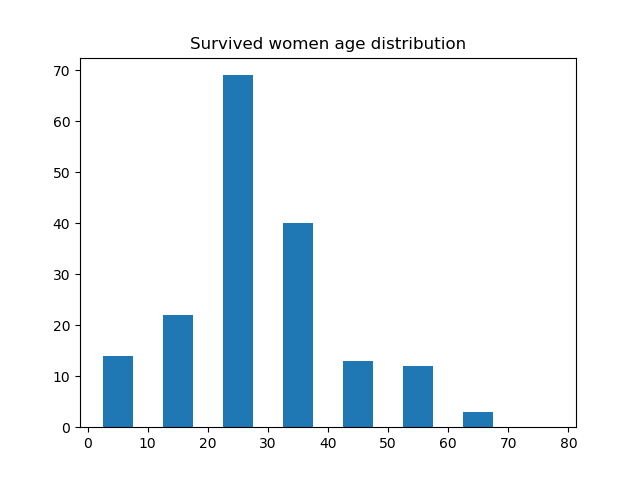
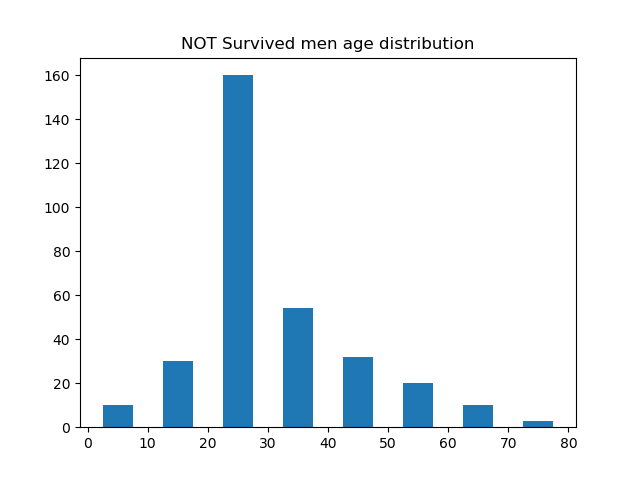

除了以上这些关系,你还可以自己找一些关系画图分析。从上面的图来看,20-30 岁的年轻男女应该是乘员的主体,年龄在 20 - 30岁的死亡的人中,男性的比例又占了绝大部分,这并不符合常理,因为这个时期的男性应该正值壮年,可能说明了这一部分年龄的很多男性都做出了自我牺牲。
在这里我只分析了年龄和性别的分布,也许你还能找出其他数据的关系,如从他们乘坐的船舱的种类分析,富人能坐头等舱,也许坐上救生艇的概率更大。本次分析年龄性别分布的代码如下:
# coding: utf-8
'''
说明:分析Titanic数据分布。
作者:rzyang
日期:2018/08/08
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
'''
函数名称: split_df
说明: 把数据集分为特征和标签
输入:
df pandas.DataFrame
输出:
(features, labels)
'''
def split_df(df):
sex = df['Sex'].values
age = df['Age'].values
labels = df['Survived'].values
features = np.array([sex, age]).T
return (features, labels)
# 程序入口
def main():
# 读取csv文件
train_df = pd.read_csv('real_train.csv')
val_df = pd.read_csv('val.csv')
# 分离DataFrame
sex = 0
age = 1
male = 0
female = 1
features, labels = split_df(train_df)
people_num = features.shape[0]
men_num = np.sum(features[:,sex] == male)
women_num = people_num - men_num
print('\nmen percent: %f' % (men_num / people_num))
print('women percent: %f' % (women_num / people_num))
survived = features[labels == 1]
survived_men = survived[survived[:,sex] == male]
survived_women = survived[survived[:,sex] == female]
not_survived = features[labels == 0]
not_survived_men = not_survived[not_survived[:,sex] == male]
not_survived_women = not_survived[not_survived[:,sex] == female]
survived_num = survived.shape[0]
survived_men_num = survived_men.shape[0]
survived_women_num = survived_num - survived_men_num
print('\nsurvived: %f' % (survived_num / people_num))
print('survived men: %f' % (survived_men_num / men_num))
print('survived women: %f' % (survived_women_num / women_num))
# plt.plot(t_features[:,0], t_features[:,1], 'ro')
# plt.plot(f_features[:,0], f_features[:,1], 'bo')
# plt.show()
plt.title('Survived age distribution')
plt.hist(survived[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
plt.title('Dead age distribution')
plt.hist(not_survived[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
plt.title('Survived men age distribution')
plt.hist(survived_men[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
plt.title('Survived women age distribution')
plt.hist(survived_women[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
plt.title('NOT Survived men age distribution')
plt.hist(not_survived_men[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
plt.title('NOT Survived women age distribution')
plt.hist(not_survived_women[:,age], bins=8, range=(0,80), rwidth=0.5)
plt.show()
if __name__ == '__main__':
main()
篇幅限制(其实是懒),本期先到这里,下一期将会引入 Logistic 分类器,继而引入神经网络。
后语
我不是大神,不是什么牛人,于 计算机视觉 领域来说,我是菜鸡,但谁刚开始接触一个领域的时候不是菜鸡呢。 写这个号的目的是为了记录我自学 计算机视觉 的笔记。
如果本文对你哪怕有一丁点帮助请右下角点赞,否则忽略就好。平时工作也是在做计算机视觉,希望大家多多指教。
我一直认为学习不能有所见即所得的想法,一看就会,一做就错。千万不要偷懒,所谓大神都是一个一个坑踩过来的。
最后,如果对 计算机视觉 感兴趣请长按二维码关注一波,我会努力带给你们价值,赞赏就不必了,能力没到,受之有愧。
