对于大数据方向我还是个新手,本篇博客仅用于个人学习记录,所以大家看看就好。
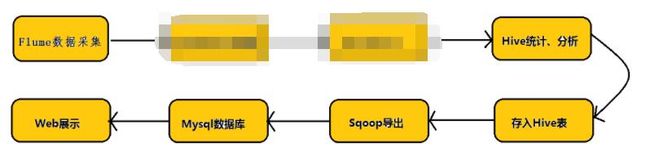
正常的Hadoop业务的开发流程应该是这样的

但是我偷了个懒,省去了MapReduce清洗并存入Hbase,以及Hbase和Hive整合的步骤,所以我的流程是这样的
本次爬取的是这条微博
flume 数据采集
首先打开 hadoop
/apps/hadoop/sbin/start-all.sh
然后切换到 flume 安装目录
cd /apps/flume/conf
新建一个 flume 配置文件
vim weibo_exec_mem_hdfs.conf
填入以下内容
agent1.sources = src
agent1.channels = ch
agent1.sinks = des
agent1.sources.src.type = exec
agent1.sources.src.command = tail -F /data/weibo/luhan.txt
agent1.channels.ch.type = memory
agent1.channels.ch.keep-alive = 30
agent1.channels.ch.capacity = 1000000
agent1.channels.ch.transactionCapacity = 100
agent1.sinks.des.type = hdfs
agent1.sinks.des.hdfs.path = hdfs://localhost:9000/myflume2/weibo_exec_mem_hdfs/%Y%m%d/
agent1.sinks.des.hdfs.useLocalTimeStamp = true
agent1.sinks.des.hdfs.inUsePrefix = _
agent1.sinks.des.hdfs.filePrefix = luhan
agent1.sinks.des.hdfs.fileType = DataStream
agent1.sinks.des.hdfs.writeFormat = Text
agent1.sinks.des.hdfs.rollInterval = 30
agent1.sinks.des.hdfs.rollSize = 1000000
agent1.sinks.des.hdfs.rollCount = 10000
agent1.sinks.des.hdfs.idleTimeout = 30
agent1.sources.src.channels = ch
agent1.sinks.des.channel = ch
保存退出,然后新建一个目录
mkdir /data/weibo
切换到目录下,新建一个爬虫
vim scrap_weibo.py
填入以下代码
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import requests
import json
import re
# source_wei_wo_url = "https://m.weibo.cn/status/4160547165300149"
def get_comment(head_url, count):
i = 1
fp = open("luhan.txt", "a", encoding="utf8")
while i <= count:
url = head_url + str(i)
resp = requests.get(url)
resp.encoding = resp.apparent_encoding
comment_json = json.loads(resp.text)
comments_list = comment_json["data"]
for commment_item in comments_list:
username = commment_item["user"]["screen_name"]
verified = commment_item["user"]["verified"]
source = commment_item["source"]
comment = commment_item["text"]
like_counts = commment_item["like_counts"]
label_filter = re.compile(r']*>', re.S)
comment = re.sub(label_filter, '', comment)
fp.write(str(username) + "\t" + str(verified) + "\t" + str(source) + "\t"
+ str(comment) + "\t" + str(like_counts) + "\n")
print(i)
i += 1
fp.close()
if __name__ == "__main__":
head_url = "https://m.weibo.cn/single/rcList?format=cards&id=4160547165300149&type=comment&hot=1&page="
get_comment(head_url, 30)
好了,现在开始运行 flume
flume-ng agent -c /apps/flume/conf/ -f /apps/flume/conf/weibo_exec_mem_hdfs.conf -n agent1 -Dflume.root.logger=DEBUG,console
新开一个窗口,运行 python 爬虫
python3 /data/weibo/vim scrap_weibo.py
这条微博下有280万评论,每页大约8条。我本来想爬30万页的,但是由于没有做异常处理,也没有添加代理什么的,估计爬虫运行不了多久。不出所料,爬到1300多页的时候就报错了,不过我也懒得改了,数据已经拿到了。
爬虫停止后,切换回 flume 窗口,按 Ctrl + c 停止数据采集。
关于 flume 采集数据我采用的方式是监听一个文件 /data/weibo/luhan.txt 。这个文件是爬虫建立的,每当爬取到新数据后就会追加到这个文件中, flume 每次都会去读取这个文件的末尾,看看有没有新数据添加进来,然后传到 hdfs 上。
现在来看一下 hdfs 上的文件
hadoop fs -ls /myflume2/weibo_exec_mem_hdfs/20171111
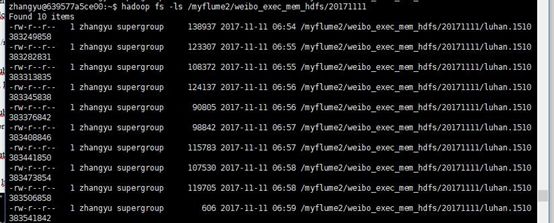
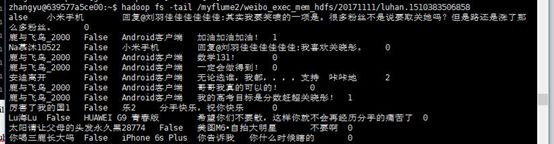
可以看到数据文件已经传进来了。先来查看一下其中一个文件
hadoop fs -tail /myflume2/weibo_exec_mem_hdfs/20171111/luhan.1510383506858
Hive存储与分析
在终端进入 hive
hive
创建一个数据库 weibo
create database weibo;
进入数据库
use weibo;
新建一个表
create table luhanweibo (username string, verified string, source string, comment string, like_counts string) row format delimited fields terminated by '\t' stored as textfile;
然后将 hdfs 上的数据加载进去
load data inpath '/myflume2/weibo_exec_mem_hdfs/20171111/*' into table luhanweibo;
现在就可以对数据进行分析了.
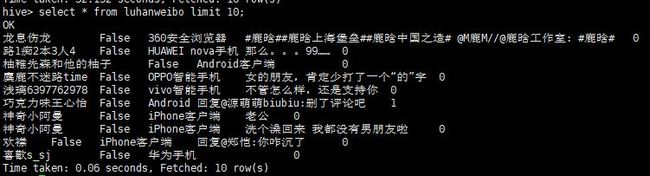
先查看一下数据吧
select * from luhanweibo limit 10;
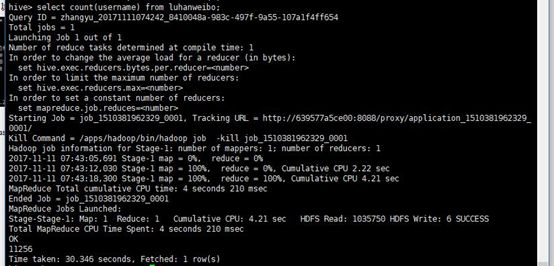
然后看一下我们爬了多少条评论
select count(username) from luhanweibo;
我先查了一下点赞数最多的十条评论
select comment, like_counts from luhanweibo order by like_counts desc limit 10;
但是评论内容我看了后发现有点不和谐,所以这里就不贴图了。
然后查看了一下评论家们都使用什么武器
select source, count(source) as num from luhanweibo group by source order by num desc limit 10;

然后看一下评论最多的前十位用户都是谁
select username,count(username) as num from luhanweibo group by username order by num desc limit 10;
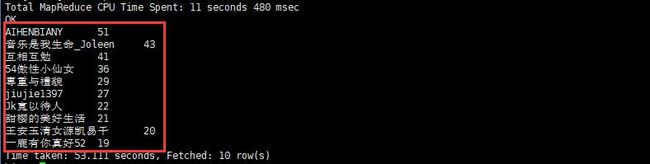
哇,光我这点样本里面,就有发 50 条评论的,我很好奇他们发的都是什么。
先来看看排第一的
select username, comment from luhanweibo where username = 'AIHENBIANY';
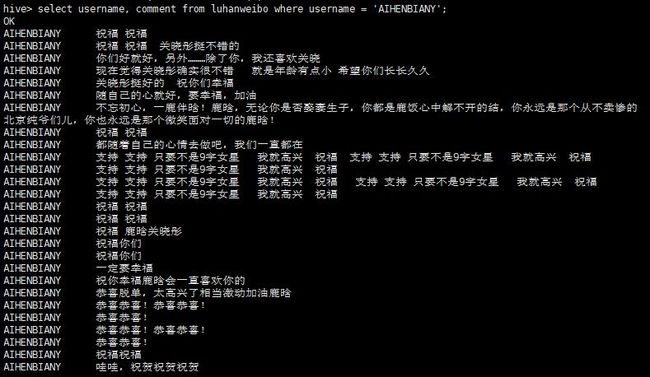
嗯~~应该是个中规中矩的粉丝
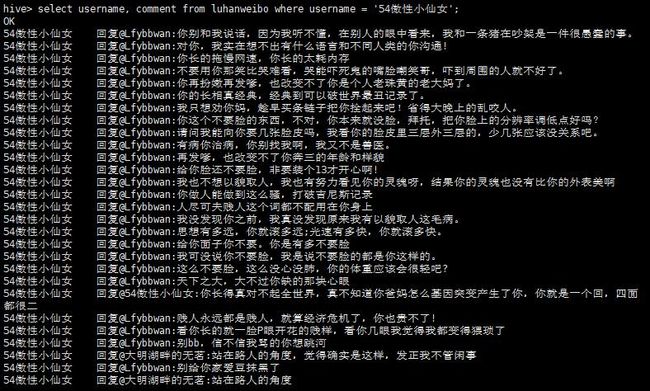
再来看看排第四的那个54傲性小仙女发了些啥
select username, comment from luhanweibo where username = '54傲性小仙女';

Sqoop 导出数据到 mysql
首先打开mysql
mysql -u root -p
然后输入密码
新建一个数据库
create database weibo;
新建一个婊
create table luhanweibo (username varchar(100), verified varchar(100), source varchar(100), comment varchar(100), like_counts int);
按照正常的步骤,现在应该用 sqoop 导出了,但是事情并没有我想象的那么简单,当我敲下如下命令后
sqoop export --connect jdbc:mysql://localhost:3306/weibo?characterEncoding=UTF-8 --username root --password strongs --table luhanweibo --export-dir /user/hive/warehouse/weibo.db/luhanweibo/* --input-fields-terminated-by '\t'
控制台报了错
Caused by: java.io.IOException: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\xAD\xF0\x9F...' for column 'comment' at row 9
at org.apache.sqoop.mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:233)
at org.apache.sqoop.mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:46)
at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:658)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.write(WrappedMapper.java:112)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:84)
百度了一下,原因是 mysql 的 UTF-8 编码不支持 emoji 表情,我按照网上给的解决方法将 UTF-8 换成 uef8mb4 编码后,仍旧导出失败。
在我还没有找到解决方法之前,就先写到这里吧
Web可视化

11月13日更新
老师给了我几条建议,配置 flume 的 sink 的时候,下面这几个配置应该删掉,因为这样会在 hdfs 上生成大量小文件,而 hadoop 最不擅长的就是处理大量的小文件
agent1.sinks.des.hdfs.rollInterval = 30
agent1.sinks.des.hdfs.rollSize = 1000000
agent1.sinks.des.hdfs.rollCount = 10000
agent1.sinks.des.hdfs.idleTimeout = 30
我觉得很有道理,但是我没改,准备有时间把项目再重新做一遍,,至于现在这个项目,将错就错吧
继续回到昨天翻车的地方
Sqoop 导出数据到 mysql
在尝试修改数据库编码失败后,我将 sqoop 导出语句的编码做了修改
sqoop export --connect jdbc:mysql://localhost:3306/weibo?characterEncoding=GBK --username root --password strongs --table luhanweibo --export-dir /user/hive/warehouse/weibo.db/luhanweibo/* --input-fields-terminated-by '\t'
将导出编码设置成了 GBK , 最终导出成功,但是 emoji 表情的部分就丢了,不过也好歹算是完成了需求
因为接下来来要做可视化,但是我的可视化环境在本地,所以要把服务器中 mysql 的数据导出到本地来,这又涉及到了数据库的导入导出
服务器端输入命令,将表结构和数据转化成 sql 文件。
mysqldump -u root -p weibo luhanweibo > /data/weibo/luhanweibo.sql
然后下载到本地
本地命令行输入mysql -u root -p 进入 mysql
切换到 bistu 数据库 use bistu;
然后输入source E:/luhanweibo.sql 执行数据库的导入,接下来就是可视化部分。
Web可视化
可视化的具体步骤我就不写了,可以参考我之前写的一篇博客利用ECharts可视化mysql数据库中的数据
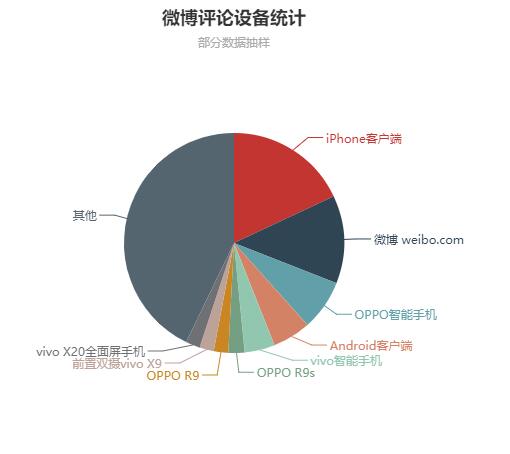
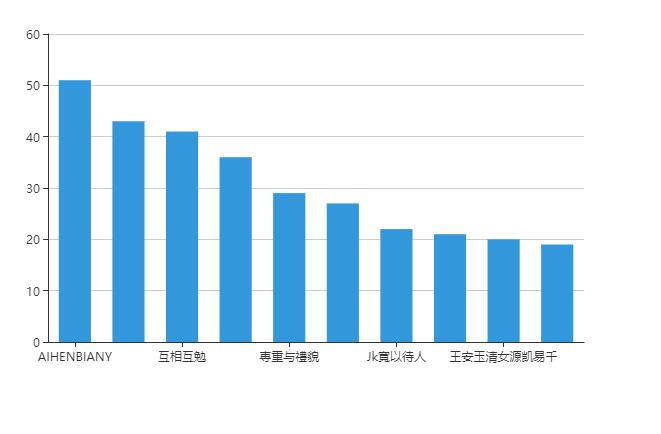
因为爬取的字段比较少,只做了两个图。
一个是统计用户都用什么设备参与评论
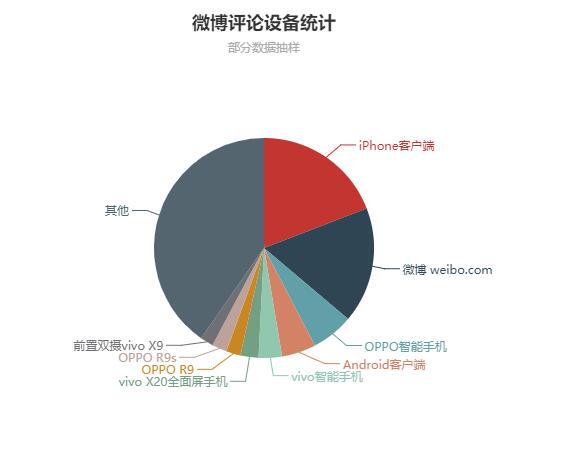
还有一个是评论数量最多的前十位用户

因为在用 sqoop 向 mysql 导出数据的时候将编码设为了 GBK,所以数据可能有偏差,导致 mysql 查询出来的结果与 hive 查出来的结果有出入,不过用 hadoop 做项目大体就是这么一个流程
11月14日更新
Sqoop 导出数据到 mysql
上次的 sqoop 导出编码问题,我一直耿耿于怀,因为数据的偏差实在太大了
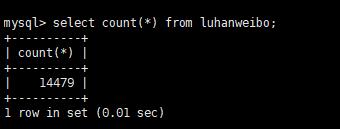
今晚花了很多精力,终于把它解决了。
首先是参照了这篇博客,修改了 mysql 的配置文件 my.cnf ,改为使用 utf8mb4 数据类型
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
然后重启数据库
接着我修改了 sqoop 导出语句
sqoop export --connect jdbc:mysql://localhost:3306/weibo --username root --password strongs --table luhanweibo --export-dir /user/hive/warehouse/weibo.db/luhanweibo/* --input-fields-terminated-by '\t'
其实就是去掉了 characterEncoding=GBK 这一个参数
然后执行导出
数据虽然导入了 mysql ,但结果还和昨天一样,比 hive 多了 3000 多条。刹那间,我在控制台发现了一个异常
Caused by: com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long for column 'comment' at row 74
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4188)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4122)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2570)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2731)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2818)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2157)
at com.mysql.jdbc.PreparedStatement.execute(PreparedStatement.java:1379)
at org.apache.sqoop.mapreduce.AsyncSqlOutputFormat$AsyncSqlExecThread.run(AsyncSqlOutputFormat.java:233
然后谷歌了一下,在 stackoverflow找到了解决方法,原来是 mysql 的 varchar 类型有长度限制,于是乎将它改成了 LONGTEXT
本来想骂街,谁这么无聊,发个微博评论还这么多字,后来一想,可能这位粉丝实在情绪太激动了,嗨,娱乐圈的事,我不太懂
完整的建表语句
create table luhanweibo (username varchar(100), verified varchar(100), source varchar(100), comment longtext, like_counts int) default charset utf8mb4;
然后修改了 mysql 的配置
SET @@global.sql_mode= 'NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
重启 mysql ,开始导出,最终结果
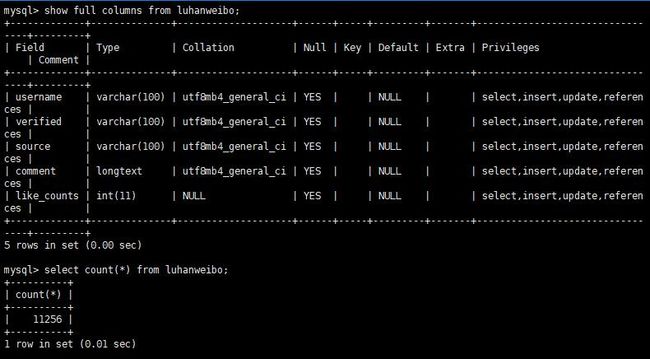
Web可视化
哈哈,这次的图可没问题了,perfect!
生活从不眷顾因循守旧、满足现状者,从不等待不思进取、坐享其成者,而是将更多机遇留给善于和勇于创新的人们,共勉。