简介
ElasticSearch是什么
ElasticSearch(ES)是一个基于Lucene构建的开源的、分布式、Restful接口全文搜索引擎。
不过,ES不仅仅是Lucene和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化和非结构化数据
Lucene
Lucene是Apache软件基金会中一个开放源代码的全文搜索引擎工具包,是一个全文搜索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
例子
下面用一个例子来介绍该结构及相应的生成算法
假设有两篇文章1和2
文章1的内容为:
Tom lives in Guangzhou, I live in Guangzhou too.
文章2的内容为:
He once lived in Shanghai.
- 取得关键词
取得关键词前要做分词处理,去除无意义的词,不同时态的词等
- 分词
- 过滤掉无意义的词(in once too 中文:的 是)
- 通过He也能找出he HE,需要统一大小写
- 通过live能找到lived lives,需要还原
- 过滤标点符号
Live为例,在文章1中出现了两次,文章2中出现了1次,出现位置在2.5.2
-
建立倒排索引
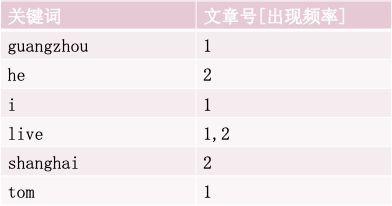 图-倒排索引关键词文章号对应关系示例
图-倒排索引关键词文章号对应关系示例
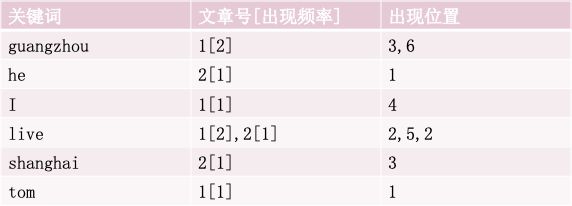
实现
实现时,Lucene将上面三列分别作为词典文件(Term Dictionary)
频率文件(frequencies)、位置文件(positions)保存。其中词典文件不仅保存了每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键词的频率信息和位置信息。压缩算法
为了减小索引文件的大小,Lucene对索引还使用了压缩技术。此处具体不再详细描述,有兴趣的可以自行百度。应用场景
对索引的查询流程-》
假设要查询单词“live”,Lucene先对词典二元查找,找到该词,通过指向频率文件的指针读出所有的文章号,然后返回结果。词典通常非常小,因此整个过程的时间是毫秒级的。
而普通的顺序匹配算法,不建索引,而是对文章内容进行字符串匹配,这个过程会相当缓慢,当文章数目很大时,时间往往是无法忍受的。
基本概念
索引词(term)
在ES中索引词是一个能够被索引的精确值。索引词可以通过term查询进行精确搜索
集群(cluster)
集群由一个节点或多个节点组成,一个集群有一个唯一的默认:ElasticSearch
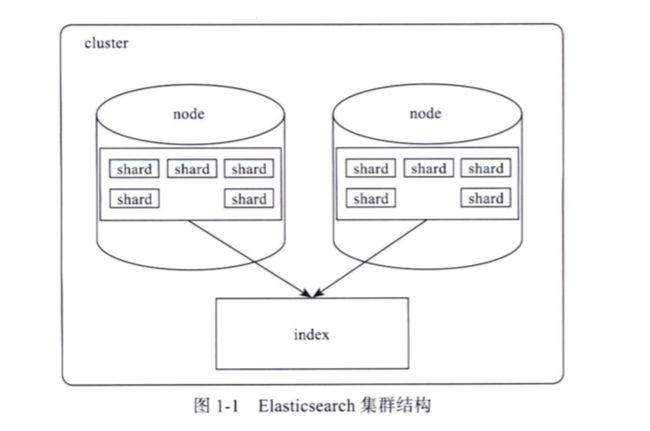
节点(node)
一个节点是一个逻辑上独立的服务,它是集群的一部分,可以存储数据,并参与集群的索引和搜索功能。
分片(shard)
分片是单个Lucene实例,索引是指向主分片和副本分片的逻辑空间。
主分片(primary shard)
每个文档都存储在一个分片中,当存储一个文档时,系统会首先存储在主分片上,然后复制到不同的副本分片。默认一个索引有5个主分片。
副本分片(replica shard)
副本分片主要是主分片的复制
索引(index)
索引是具有相同结构的文档集合
类型(type)
在索引中可以定义一个或多个类型,类型是索引的逻辑分区。
文档(document)
文档是存储在ES中的一个JSON格式的字符串,它就像是关系型数据库中表的一行。
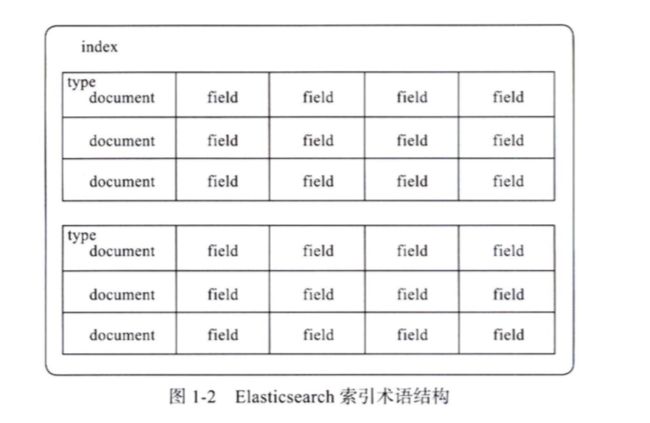
映射(mapping)
映射像关系型数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。
字段(field)
文档中包含一个或多个字段,字段可以是一个简单的值(字符串、整数
日期等),也可以是一个数组或对象的嵌套结构。
主键(ID)
ID是一个文件的唯一标识
对外接口
ElasticSearch对外提供的API是http协议的形式,通过JSON格式以REST约定对外提供。
Java接口
https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/index.html
安装
安装命令
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.zip
unzip elasticsearch-6.3.2.zip
cd elasticsearch-6.3.2/
启动
./bin/elasticsearch
重启
sh elasticsearch -d
kill ES
ps -ef | grep elastic

官网安装操作
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/zip-targz.html
插件
Head插件安装
https://www.jianshu.com/p/47a123703fcd
索引
新建/删除/获取索引
创建索引
创建索引的时候通过number_of_shards和number_of_replicas参数的数量来修改分片和副本的数量,默认分片数量:5,副本数量:1
请求:PUT http://localhost:9200/secisland
参数:
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}
修改副本数量
请求:PUT http://localhost:9200/secisland/_settings/
参数:
{
"number_of_replicas": 1
}
创建自定义字段类型
请求:PUT http://localhost:9200/secisland/
参数:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"secilog": {
"properties": {
"logType": {
"type": "text",
"index": "not_analyzed"
}
}
}
}
}
删除索引
删除索引可以使用逗号分隔符,或者使用_all或*号删除全部索引
请求:DELETE http://localhost:9200/secisland/
参数:
{}
打开/关闭索引
可以打开或关闭全部索引,使用_all或使用通配符表示全部(如:*)
打开索引
POST http://localhost:9200/secisland/_open/
{}
关闭索引
POST http://localhost:9200/secisland/_close/
{}

索引别名
通过别名可以查询到一个或多个索引的内容。可以对别名编写过滤器或路由,在系统中别名不能重复,也不能和索引名重复。
添加别名
索引别名关联一个索引:
POST http://localhost:9200/_aliases/
{
"actions": [
{
"add": {
"index": "secisland",
"alias": "s1"
}
}
]
}
一个别名关联多个索引
POST http://localhost:9200/_aliases/
{
"actions": [
{
"add": {
"index": "secisland",
"alias": "s1"
}
},{
"add": {
"index": "school",
"alias": "s1"
}
]
}
删除别名
POST http://localhost:9200/_aliases/
{
"actions": [
{
"remove": {
"index": "secisland",
"alias": "s1"
}
}
]
}
或
DELETE http://localhost:9200/_aliases/s1
重建索引
通过向源添加一个类型或一个查询语句来限制文档的数量
{
"source": {
"index": "megcorp",
"type": "employee",
"query": {
"range": {
"age": {
"gt": 0
}
}
}
},
"dest": {
"index": "new_megcorp"
}
}
_reindex支持使用脚本来修改文档
映射
映射是定义存储和索引的文档类型以及字段的过程。索引中每个字段都有一个类型,每种类型都有它自己的映射。一个映射定义了文档结构内每个字段的数据类型。
动态映射
字段和映射类型在使用前不需要事先定义。依靠动态映射,通过索引文档,新的映射类型和字段名会自动添加。新的字段可以添加到顶级映射类型或者映射内部的对象和嵌入字段。
动态映射可以配置自定义映射用于新类型或新字段。
增加/获取映射
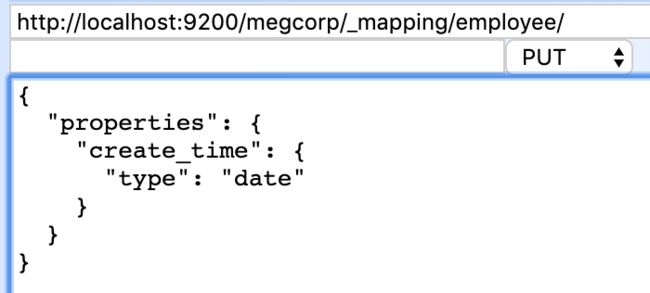
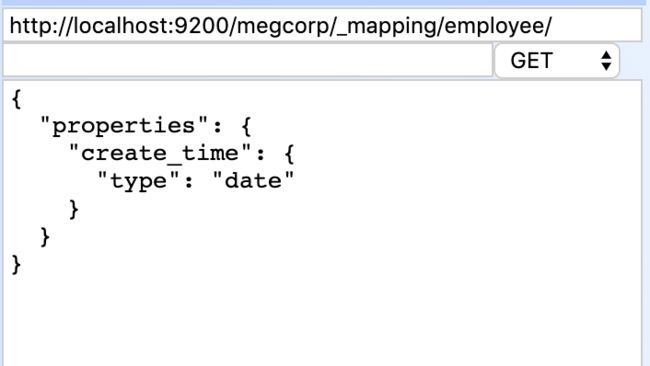
往已存在索引(index)名megcorp和文档类型(type)employee中新增字段(field):create_time,其中:
- 若文档类型存在,则只新增字段create_time
-
若文档类型不存在,则新建文档类型,并新增字段create_time
 图
图
其中index和type都不存在,添加字段时,直接使用PUT http://localhost:9200/newindextest/_mapping/typetest会报错
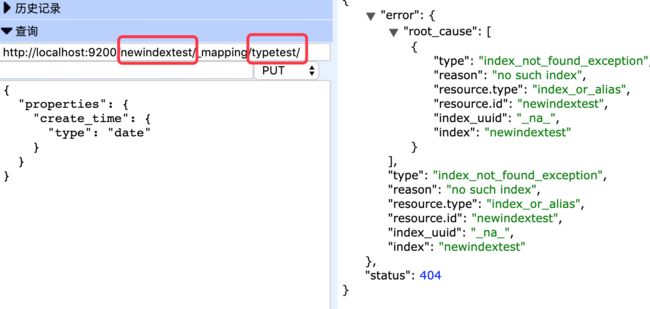
正确写法
{"mappings": {
"typetest": {
"properties": {
"create_time": {
"type": "date"}}}}}
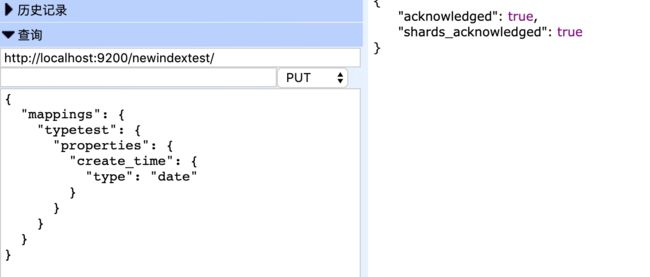
查看映射
更新映射
ES并不支持修改映射字段类型
为什么不能修改一个字段的type?
原因是一个字段的类型修改以后,那么该字段的所有数据都需要重新索引。Elasticsearch底层使用的是lucene库,字段类型修改以后索引和搜索要涉及分词方式等操作,不允许修改类型在我看来是符合lucene机制的。
更新映射字段报错
将字段create_time原date字段类型更新为string类型,报错——》
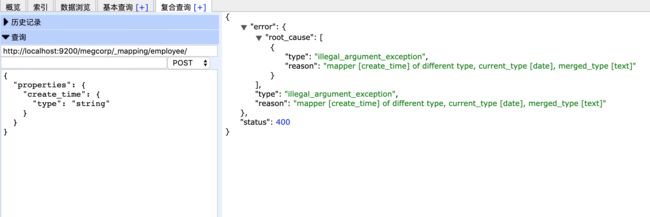
更新映射字段参数
如字段create_time,添加date字段类型的format
POST http://localhost:9200/megcorp/_mapping/employee/
{
"properties": {
"create_time": {
"type": "date",
"format": "epoch_second"
}
}
}
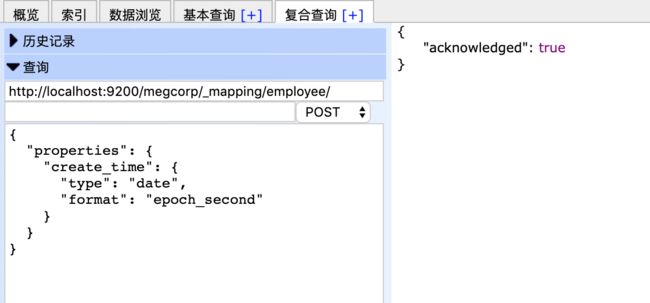
字段数据类型
ES支持一系列不同的数据类型来定义文档字段,分为核心数据、复杂数据、地理数据、专门数据类型
核心数据类型包括:
- 字符串数据类型:string(es5.x以上,只支持text和keyword类型)
- 数字型数据类型:long,integer,short,byte,double,float,half_float, scaled_float
- 日期型数据类型:date
- 布尔型数据类型:boolean
- 二进制数据类型:binary
- 范围数据类型:integer_range, float_range, long_range, double_range, date_range
复杂数据类型包括: - 数组数据类型:不需要专门的类型来定义数组
- 对象数据类型:object,单独的json对象
- 嵌套数据类型:nested,关于json对象的数组
地理数据类型包括: - 地理点数据类型:geo_point,经纬点
- 地理形状数据类型:geo_shape,多边形的复杂地理形状
专门数据类型包括: - IPV4数据类型:IP协议为IPV4的地址
- 完成数据类型:completion,提供自动补全的建议
- 单词计数数据类型:token_count,统计字段串中的单词数量
核心数据类型
字符串数据类型
string数据类型在ES5.x以上,不再支持,仅支持text和keyword数据类型
text数据类型
text数据类型,通常用于基于文本的相关性搜索,支持分词。text字段不用于排序并且很少用于聚合keyword数据类型
如果需要索引结构化内容,如电子邮箱地址,主机名,状态值,或者标签等,可以使用keword字段类型-
字段参数
 图
图 -
关注
index
设置是否可以被用户搜索,值包含以下三种中的一个:
 图
图
数字型数据类型

注意:
在ES5.x后,新增了half_float和scaled_float两种类型
half_float:16位半精度浮点数
scaled_float:A floating point that is backed by a long and a fixed scaling factor
日期型数据类型
JSON中没有日期型数据类型,所以在ES中,日期可以是:
- 包含格式化日期的字符串,例如:"2015-01-01"或者"2015/01/01 18:00:00"
- 代表时间毫秒数的长整型数字
- 代表时间秒数的整数
如果没有指定格式,则使用默认值:
"strict_date_optional_time||epoch_millis",这意味着接受任意时间戳的日期值
多日期格式
可以使用||分隔,可以指定多个日期格式
{
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
可选,了解即可,使用时再查询
日期型数字的字段参数
 图
图
布尔数据类型
布尔字段接受true或false值,也可以接受代表真假的字符串和数字
- 假值:false,“false”,“off”,“no”,“0”,“”(空字符串),0,0.0
- 真值:其他任何非假的值
二进制数据类型
二进制数据类型接受Base64编码字符串的二进制值。字段不以默认方式存储而且不能搜索
复杂数据类型
数组数据类型
在ES中,没有专门的数组类型。每个字段默认可以包含零个或更多的值,然而,数组中所有的值都必须是相同的数据类型,例如:
- 字符串数组:["one","two"]
- 整数数组:[1,2]
- 由数组组成的数组:[1,[3,4]]
- 对象数组:[{"name":"Mary","age":13},{"name":"Dave","age":18}]
无法对数组中的每一个对象进行单独的查询,如果想要查询的话,需要用nested数据类型替换对象数据类型
对象数据类型
JSON对象是天然分层的:文档可以包含内部对象。同样,内部对象也可以包含内部对象
对象数据类型参数
 图
图
嵌套数据类型
嵌套数据类型是关于对象数据类型一个专门的版本,用来使一组对象被单独地索引和查询。

下面内容不常用,了解即可
地理数据类型
- 地理点数据类型
地理点数据类型字段接受经纬度对,可用于:
- 查找一定范围内的地理点
- 通过地理位置或者相对与中心点的距离聚合文档
- 整合距离到文档的相关性评分
- 通过距离对文档进行排序
- 地理形状数据类型
地理形状数据类型有利于索引和搜索任意数据形状,例如矩形和多边形。
专门数据类型
这里也不再详细说明,感兴趣的可以查看官网介绍https://www.elastic.co/guide/en/elasticsearch/reference/5.5/ip.html
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/token-count.html
元字段
每个文档都有与之关联的元数据,元字段是为了保证系统正常运转的内置字段。
_all
_all是一个特殊的包含全部内容的字段,在一个大字符串中关联所有其他字段的值,使用空格作为分隔符。可以内分析和索引但不会被存储。
使用_all字段可以对文档的值进行搜索而不必知道包含所需值的字段名
POST http://localhost:9200/megcorp/employee/ _search
{
"query": {
"bool": {
"must": {
"match": {
"_all": "Smith"
}
}
}
}
}
_field_names
_field_names字段索引文档中所有包含非空值的字段名称。_field_names字段用于存在查询和缺失查询的情况下,查找指定字段拥有非空值的文档是否存在。
_id
每个被索引的文档都关联一个_type字段和一个_id字段,_id没有索引,它的值可以从_uid字段中自动生成。
_id字段的值可以在查询以及脚本中访问,但在聚合或排序的时候,要使用_uid字段,而不能用_id。
POST http://localhost:9200/megcorp/employee/_search
{
"query": {
"bool": {
"must": {
"terms": {
"_id": ["1","2"]
}
}
}
}
}
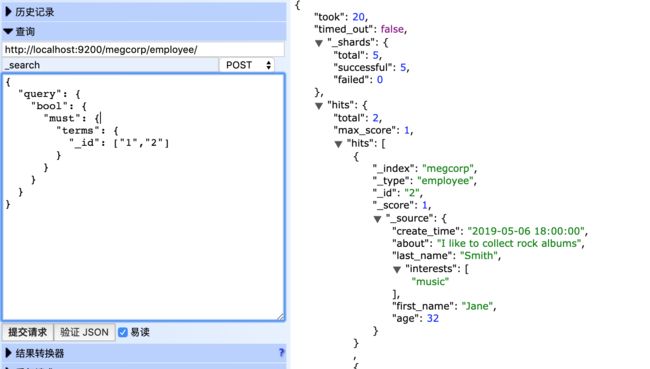
_index
在多个索引中执行查询时,有时候需要添加查询子句来关联特定的索引文档。_index字段可以匹配包含某个文档的索引。在term或terms查询、聚合、脚本以及排序的时候,可以访问_index字段的值。

_routing
文档在索引中路由到特定的分片,公式如下:
share_num = hash(_routing) % num_primary_shards
其中:
_routing字段默认值使用的是文档_id字段,如果存在父文档,则使用文档的_parent编号
_routing字段可以在查询、聚合脚本以及排序的时候使用
-
利用自定义路由进行搜索
自定义路由可以降低搜索压力。搜索请求可以仅仅发送到匹配指定路由值的分片而不是广播到所有分片。
GET http://localhost:9200/megcorp/_search?routing=1,2
 图
图 -
使路由值成为必选项
可以设置_routing字段,使自定义路由值成为所有CRUD操作的必选项
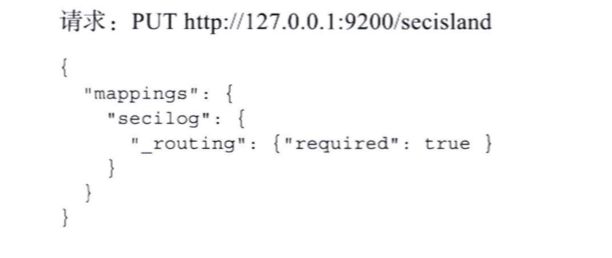 图
图
_type
每个索引的文档都包含_type和_id字段,索引_type的目的是通过类型名加快搜索进度

_uid
_uid字段值={_type}#{_id}
如:employee#1
数据
文档管理
新增记录
在ElasticSearch索引中,对应于CRUD中的“创建”和“更新” - 如果对具有给定类型的文档进行索引,并且要插入原先不存在的ID。 如果具有相同类型和ID的文档已存在,则会被覆盖。
要索引第一个JSON对象,我们对REST API创建一个PUT请求到一个由索引名称,类型名称和ID组成的URL。 也就是:http://localhost:9200/
索引和类型是必需的,而id部分是可选的。如果不指定ID,ElasticSearch会为我们生成一个ID。 但是,如果不指定id,应该使用HTTP的POST而不是PUT请求。
索引名称是任意的。如果服务器上没有此名称的索引,则将使用默认配置来创建一个索引。
至于类型名称,它也是任意的。 它有几个用途,包括:
- 每种类型都有自己的ID空间。
- 不同类型具有不同的映射(“模式”,定义属性/字段应如何编制索引)。
- 搜索多种类型是可以的,并且也很常见,但很容易搜索一种或多种指定类型。
eg:要创建一个索引,索引名称:movies,索引类型:movie,id:1
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}'
执行结果
{
"_index":"movies",
"_type":"movie",
"_id":"1",
"_version":1,
"result":"created",
"_shards":{
"total":2,
"successful":1,
"failed":0},
"created":true
}
弄明白返回结果json对象各字段含义;total为何是2
更新记录
eg:在上面已添加的记录中再新增一个类型列表。要做到这一点,只需使用相同的ID索引它。使用与之前完全相同的索引请求,但类型扩展了JSON对象
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
执行结果:
{
"_index":"movies",
"_type":"movie",
"_id":"1",
"_version":2,
"result":"updated",
"_shards":{
"total":2,
"successful":1,
"failed":0},
"created":false
}
ElasticSearch的响应结果与前面的大体上一样,但有一点区别,结果对象中的_version属性的值为2,而不是1。
版本号(_version)可用于跟踪文档已编入索引的次数。它的主要目的是允许乐观的并发控制,因为可以在索引请求中提供一个版本,如果提供的版本高于索引中的版本,ElasticSearch将只覆盖文档内容,ID值不变,版本号自动添加。
查看记录
curl -XGET "http://localhost:9200/movies/movie/1"
Elastic返回结果:
{"_index":"movies","_type":"movie","_id":"1","_version":2,"found":true,"_source":
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}}
结果对象包含与索引时所看到的类似的元数据,如索引,类型和版本信息。 最后最重要的是,它有一个名称为“_source”的属性,它包含实际获取的文档信息
删除文档
为了通过ID从索引中删除单个指定的文档,使用与获取索引文档相同的URL,只是这里将HTTP方法更改为DELETE
curl -XDELETE "http://localhost:9200/movies/movie/1"
执行结果:
{
"found":true,
"_index":"movies",
"_type":"movie",
"_id":"1",
"_version":3,
"result":"deleted",
"_shards":{
"total":2,
"successful":1,
"failed":0}
}
响应对象包含元数据方面的一些常见数据字段,以及名为“_found”的属性,表示文档确实已找到并且操作成功。
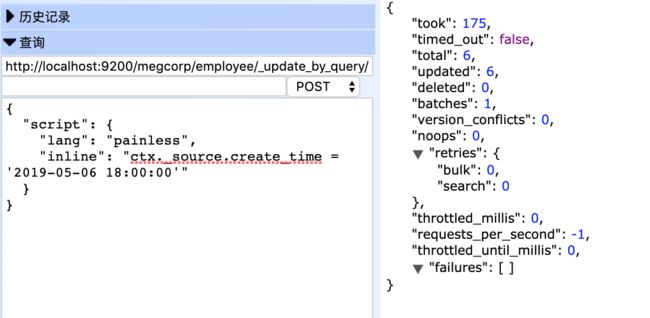
批量更新全部文档的某个字段
POST http://localhost:9200/megcorp/employee/_update_by_query/
{
"script": {
"lang": "painless",
"inline": "ctx._source.create_time = '2019-05-06 18:00:00'"
}
}
全部更新和局部更新
ES全部更新
ES可以使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作。
注意:
es执行更新操作的时候,ES首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,ES会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
ES局部更新
局部更新,可以添加新字段或者更新已有字段(必须使用POST),只更新某个字段
多文档操作
搜索
搜索方式及其相关内容
- 通过url参数进行搜索
GET http://localhost:9200/megcorp/employee/_search?q=music
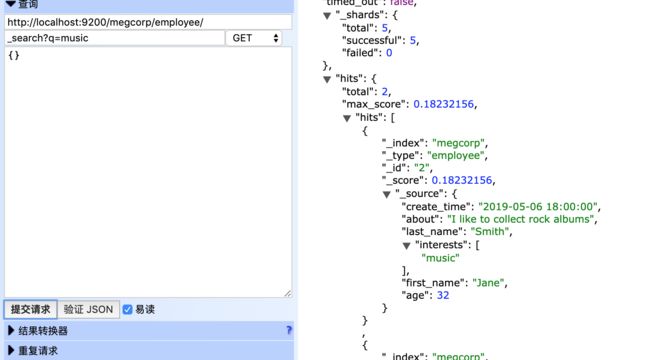 图
图
其中:q为参数,多个参数之间用&隔开
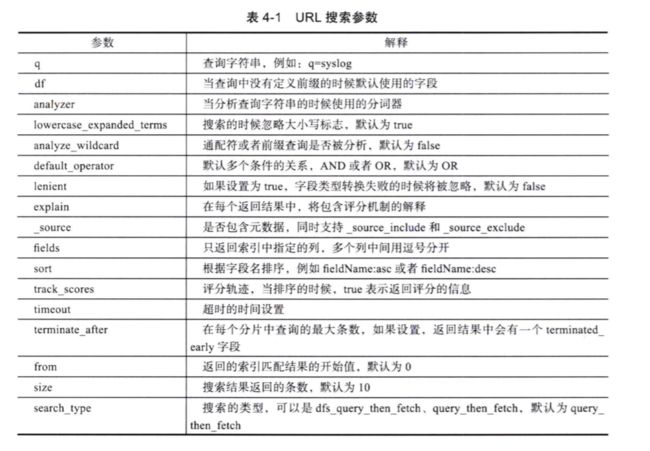
url搜索参数解释见下表
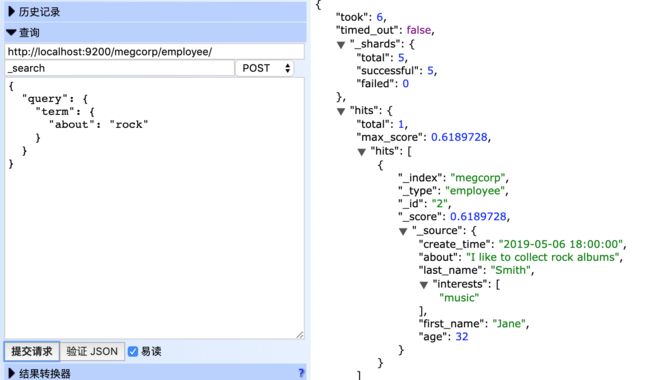
- post请求参数进行搜索
POST http://localhost:9200/megcorp/employee/_search
{
"query": {
"term": {
"about": "rock"
}
}
}
3.排序sort
当搜索的字段有多个时,可以对指定的字段排序
{
"query": {
"bool": {
"filter": [{
"range": {"age": {"gt": 25}}
}]}},
"sort": {
"age": {
"order": "desc"
}
}
}
- 数据列过滤
数据列过滤允许在查询的时候不显示原始数据,或者显示部分原始字段。
POST http://localhost:9200/megcorp/employee/_search
{
"_source": false,
"query": {
"term": {
"about": "rock"
}
}
}

5.脚本支持
搜索是支持脚本的
这里type字段类型还是keyword,text的字段类型会报错
POST http://localhost:9200/megcorp/employee/_search
{
"query": {
"term": {
"type": "12"
}
},
"script_fields": {
"test1": {
"script": {
"lang": "painless",
"inline": "doc['type'].value + '34'"
}
}
}
}

结构化查询Query DSL
见https://www.jianshu.com/p/3cda7996f4c3
聚合
聚合是一种基于搜索的数据汇总,通过组合可以完成复杂的操作。聚合可以对文档中的数据进行统计汇总,分组等。对一个聚合进行操作可以看作在一组文档中分析数据。
聚合的分类
通常聚合分为三大类
- 度量聚合:在一组文档中对某一个数字型字段进行计算得出指标值
- 分组聚合:创建多个分组,每个分组都关联一个关键字和相关文档标准
- 管道聚合:这一类聚合的数据源是其他聚合的输出,然后进行相关指标的计算
聚合操作的基本结构
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}
其中:
aggregations:为聚合关键字,可以简化为aggs
aggregation_name:用户自定义的逻辑名,用来唯一标识响应里面的聚合结果
aggregation_type:聚合的特定类型
实例
度量聚合
- 平均值聚合
计算从聚合的文档中提取的数字型值的平均值,这些值可以是文档中的数字型字段中提取,也可以通过脚本生成。
下面的例子就是从文档的数字型字段中提取的
POST http://localhost:9200/megcorp/employee/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
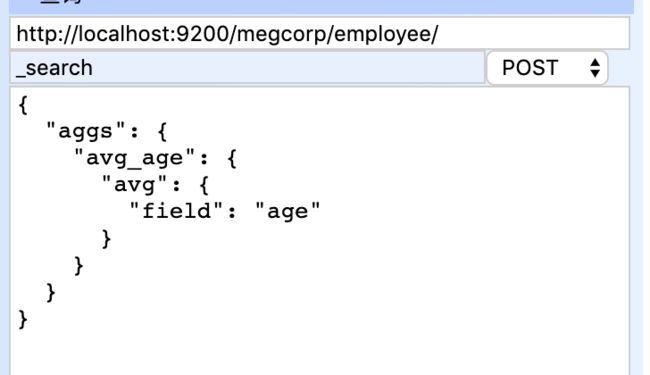
聚合执行结果底部则会有age平均值结果返回

脚本
基于脚本计算平均值
{
"aggs": {
"avg_age": {
"avg": {
"script": "doc['grage'].value"
}
}
}
}
默认值
Missing字段定义了文档缺失时应该如何处理。默认情况下这些文档会被忽略,也可以设置一个默认值
下面例子里设置missing默认值是10,没有值时系统会使用默认值10来作为计算的值。
"aggs": {
"avg_age": {
"avg": {
"field": "age",
"missing": 10
}
}
}
}
- 基数聚合
这是一个单值度量聚合,计算不同值的近似计数。值可以从文档的特定字段中提取,也可以通过脚本生成。
关键字:cardinality
{
"aggs": {
"name_count": {
"cardinality": {
"field": "type"
}
}
}
}
最大值聚合
最大值聚合是一个单值度量聚合,记录和返回从聚合的文档中提取出的数字型值中的最大值
关键字:max最小值聚合
最小值聚合是一个单值度量聚合,记录和返回从聚合的文档中提取出的数字型值中的最小值
关键字:min和聚合
和聚合是一个单值度量聚合,对聚合的文档中提取出的数字型值进行求和
关键字:sum值计数聚合
值计数聚合是一个单值度量聚合,对聚合的文档中提取出的值进行计数
关键字:value_count-
统计聚合
统计聚合是一个多值度量聚合,对聚合的文档中提取的数字型值进行统计计算,统计聚合包括:最小值,最大值,和,计数和平均数聚合
关键字:stats
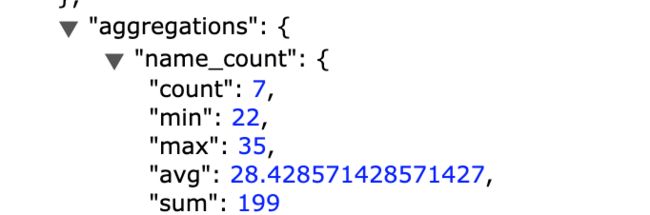 图
图
-
百分比聚合
百分比聚合是一个多值度量聚合,对聚合文档中提取的数字型值计算一个或多个百分比。如:95百分比对应的值表示这个值大于95%的所有值。
关键字:percentiles
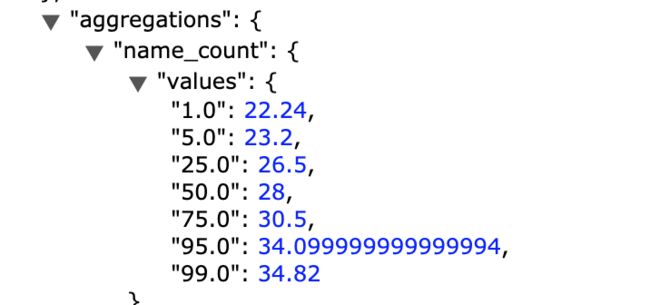 图
图
其中:
percents参数:不必填,用来指定百分比进行计算
- 百分比分级聚合
百分比聚合是一个多值度量聚合,对聚合文档中提取的数字型值计算一个或多个百分比。百分比等级表示测试值低于某一特定值的百分比。如:一个值大于或等于所有测试值的95%,就表示这个值在第95百分比等级
关键字:percentile_ranks
{
"aggs" : {
"load_time_outlier" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [15, 30]
}
}
}
}
分组聚合
分组聚合不想度量聚合那样通过字段进行计算,而是根据文档创建分组。每个聚合都关联一个标准(取决于聚合的类型),决定了一个文档在当前的条件下是否会“划入”分组中。
- 子聚合
关键字:_parent
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/search-aggregations-bucket-children-aggregation.html
-直方图聚合
关键字:histogram
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/search-aggregations-bucket-histogram-aggregation.html
- 时间范围聚合
时间范围聚合是一个专门用于时间型数据的范围聚合。
from和to参数值可以使用日期数学表达式,也可以指定返回的响应中from和to字段的日期格式
关键字:date_range
{
"aggs": {
"range": {
"date_range": {
"field": "create_time",
"format": "MM-yyyy",
"ranges": [
{
"to": "now-10M/M"
},
{
"from": "now-10M/M"
}
]
}
}
}
}
上面例子里,创建了两个分组,第一会包含日期在10个月之前的所有文件,第二个会包含日期在10个月前至今的所有文件
执行结果如下
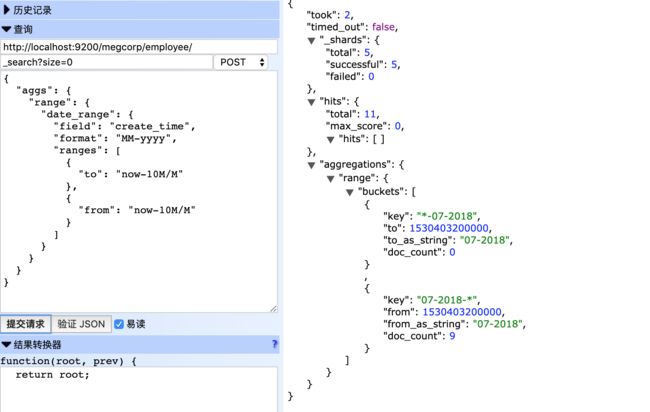
- 范围聚合
范围聚合是一个基于多组值来源的聚合,可以让用户定义一系列范围,每个范围代表一个分组。
注意:
范围聚合的每个范围内包含from值但是排除to值
关键字:range
{
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{"to": 25},
{"from": 26,"to": 30}
]
}
}
}
}

- 过滤聚合
过滤聚合是一个单分组聚合,包含当前文档集中所有匹配指定的过滤条件的文档
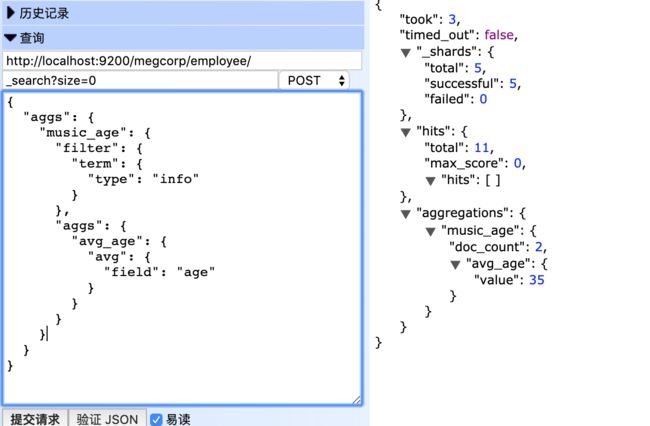
关键词:filter
POST http://localhost:9200/megcorp/employee/_search?size=0
{
"aggs": {
"music_age": {
"filter": {
"term": {
"type": "info"
}
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
执行结果:
- 多重过滤聚合
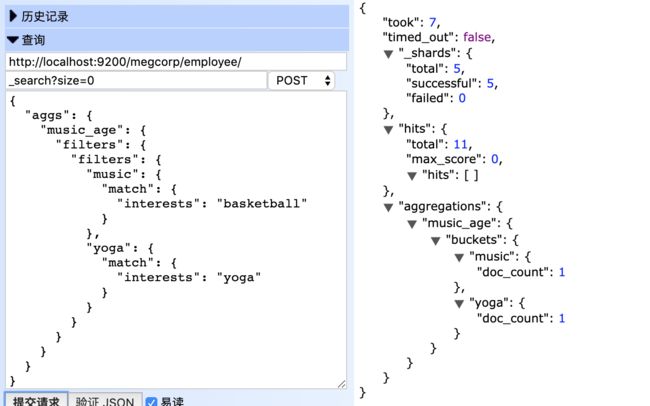
多重过滤聚合是定义一个多分组聚合,每个分组关联一个过滤条件,并收集所有满足自身过滤条件的文档
关键字:filters
POST http://localhost:9200/megcorp/employee/_search?size=0
{
"aggs": {
"music_age": {
"filters": {
"filters": {
"music": {
"match": {
"interests": "basketball"
}
},
"yoga": {
"match": {
"interests": "yoga"
}
}
}
}
}
}
}
-
空值聚合
空值聚合是一个基于字段数据的单分组聚合,在当前文档集中对所有缺失字段值为空或被设置为null的文档创建一个分组。
关键字:missing
 图
图
管道聚合
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/search-aggregations-pipeline.html
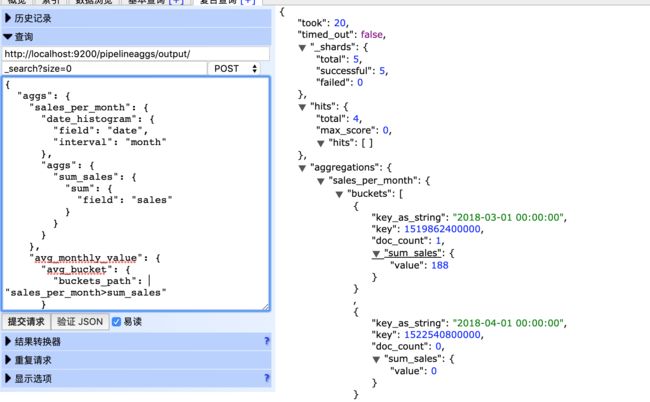
管道集合工作于其他聚合产出的输出结而不是文档集,用于向输出树添加信息
{
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"sum_sales": {
"sum": {
"field": "sales"
}
}
}
},
"avg_monthly_value": {
"avg_bucket": {
"buckets_path": "sales_per_month>sum_sales"
}
}
}
}
其中:
buckets_path:输入聚合通过buckets_path参数定义,格式如下:
- 聚合分隔符:>
- 指标分隔符:.
- 聚合名为<聚合的名称>
- 指标为<指标的名称(如果是多值度量聚合)>
-
路径为<聚合名>[<聚合分隔符><聚合名>]*[<指标分隔符><指标>]
 图
图