排序算法在算法界是一个怎么样的存在?就好像在学术界中数学的地位,说直接用好像用不上,可是不会做起事情来总会捉襟见肘,左支右绌。找工作的时候,有的面试官甚至会让我们手写排序算法。既然排序算法如此重要,就让我们一起去夯实基础,切切实实得掌握它吧。
前言
先讲两个重要的概念。
1.所谓稳定排序就是指数组中相等的元素在排序过后前后顺序不变。
2.排序算法的平均复杂度是有下限的,为nlog(n)。所以大家不要再想着能发明什么牛逼的算法可以达到线性增长的。至于这个定理的证明,比较复杂,我会在下篇文章中专门讲述。
二分查找法
def binary_search(l, item):
low = 0
high = len(l)-1
while low <= high:
mid = (low + high)//2
mid_data = l[mid]
if mid_data > item:
high = mid - 1
elif mid_data < item:
low = mid + 1
else:
return mid
return None
L = [2, 6, 4 ,5, 7]
index = binary_search(L, 9)
冒泡算法
运动前总要热身,防止拉伤,深入研究排序算法前,先给大家介绍一个最常见,算法思想最简单最粗暴的排序算法——冒泡排序。
重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
def bubble_sort(l):
length = len(l)
for i in range(1, length):
for j in range(0, length-i):
if l[j] > l[j+1]:
l[j], l[j+1] = l[j+1], l[j]
return l
print(bubble_sort([2, 4, 1, 4]))
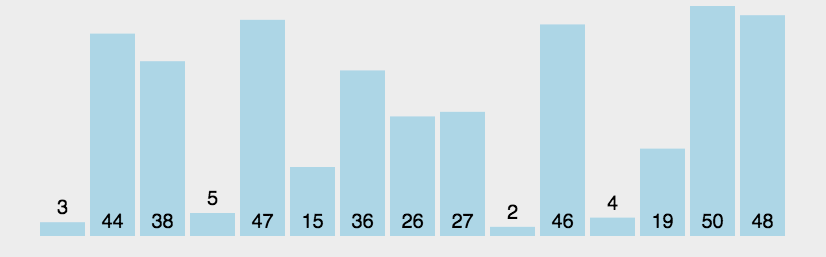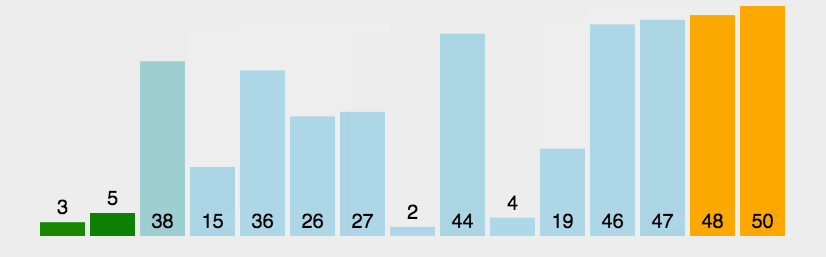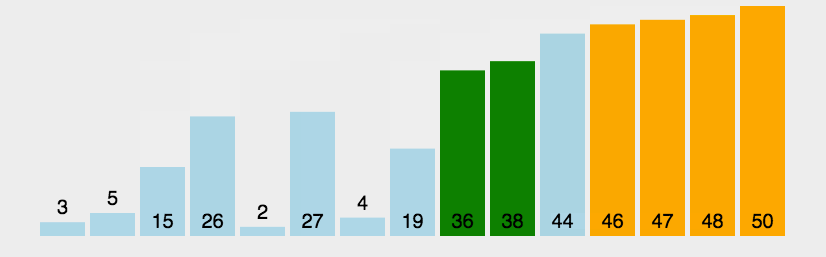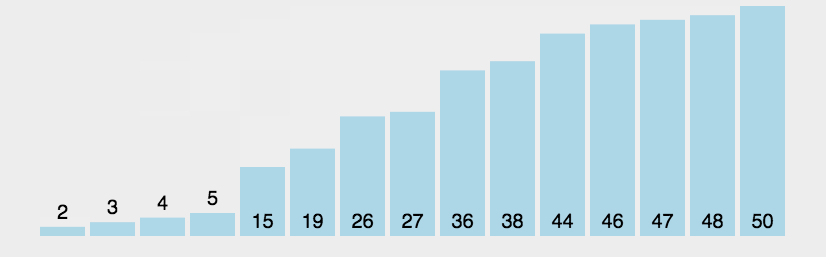
对该算法进行复杂性分析。我首先取了100个数组,数组规模从1到1000个元素均匀递增,数组中每个数的大小在(1,10000),得到下图。横坐标是排序的数组规模大小,纵坐标是排序所用时间,单位为秒。以后的图纵横坐标都是如此。
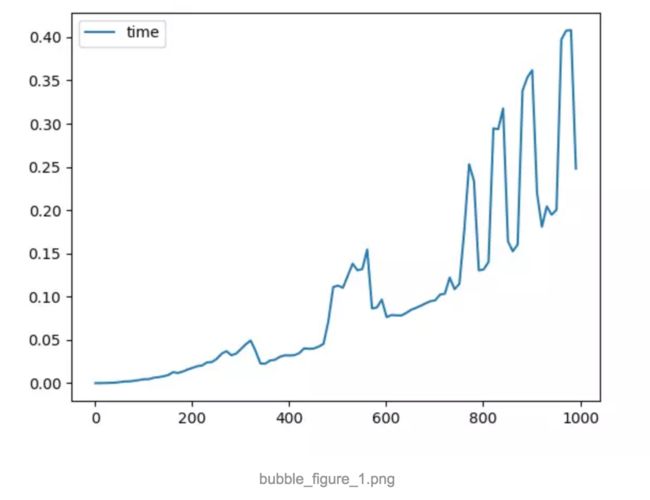
能够看出来,随着数组元素规模越来越大,所耗费时间呈现螺旋式上升的趋势。不过波动较大,我们也看不太清楚它是个怎么样的曲线。为此我扩大了样本规模,请看下图。
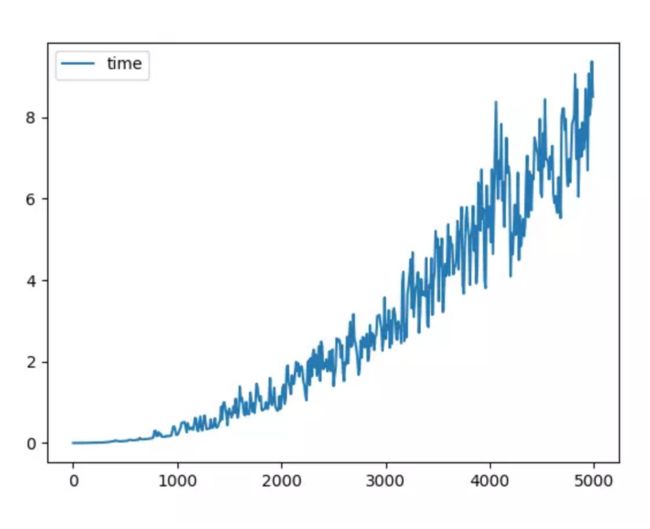
从这张图中我们可以很清晰明了的看出,这是个二次曲线。这也符合实际情况,冒泡排序的算法复杂度是数组规模的平方。
冒泡排序可以说是最经典的,最稳定的一个算法,上算法课的同学们一定会接触它。因为它似乎是一把打开算法大门的钥匙,有了它,我们开始知道何为算法。但是,在实际应用中,我们并不用它。
插入排序
大家都有一个经验,打扑克的时候,我们都喜欢按大小顺序来摆放扑克牌,其实我们每次打一把扑克都在进行一次插入排序。
显而易见,扑克牌在我们手中,我们将牌插来插去非常简单。可是这种操作在计算机内存空间中就相当费时。可以去想象,每当我们插入一个数据,比它大的数据元素将整体往后挪动以来达到给它空出内存空间的目的。(python中没有指针,暂时不考虑链表,这也是python的劣势之一)由此我们可以得出一个结论,插入排序适用于数据量较少,而且当大部分数据是有序的情况下。
当数据大部分有序的情况下,复杂度近似于O(n),这非常了不起了。


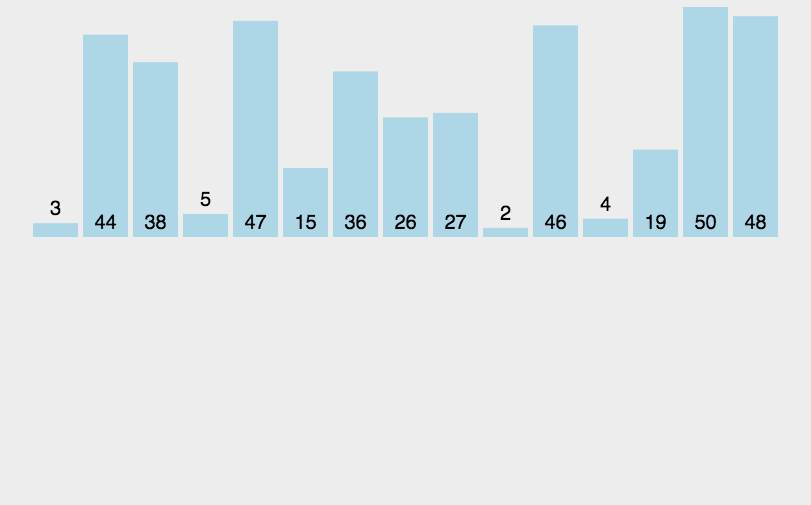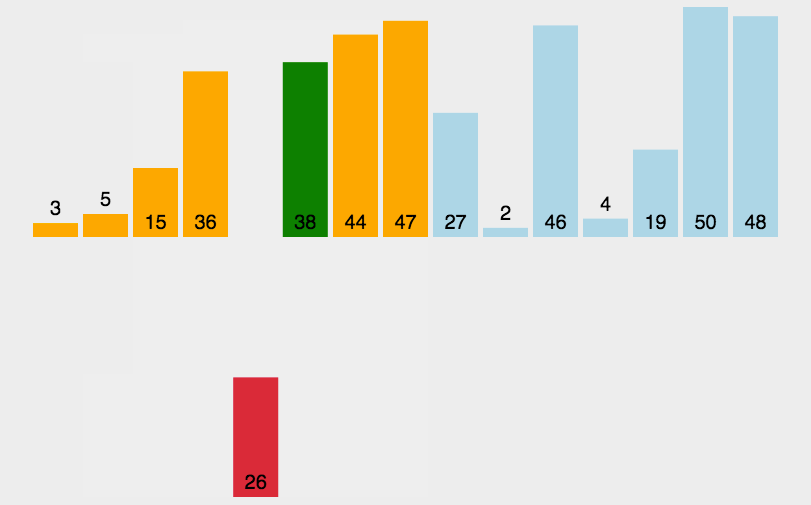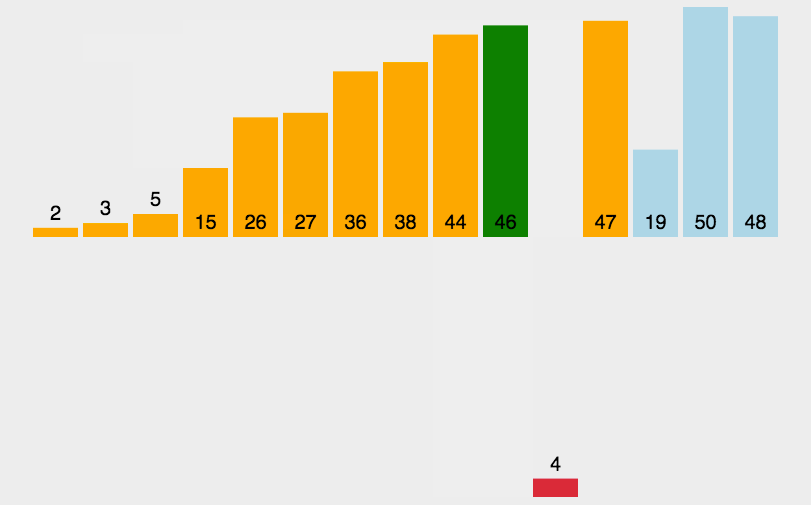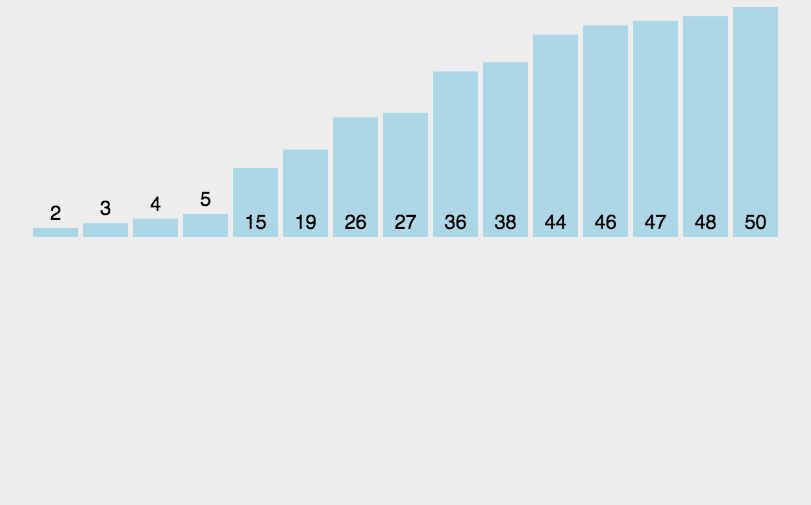
def insert_sort(l):
length = len(l)
for i in range(1, length):
for j in range(i-1, -1, -1):
if l[j] >l[j+1]:
l[j], l[j+1] = l[j+1], l[j]
return l
L = [1, 3, 5, 7, 19, 32, 5]
print(insert_sort(L))
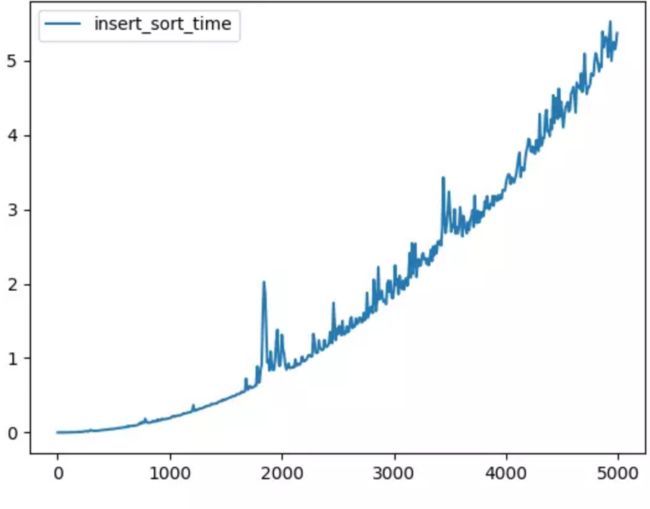
如图,表现在二次曲线周围上下波动。
希尔排序
希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因D.L.Shell于1959年提出而得名。
该排序算法也是个很有纪念意义的算法,它首次突破了当时排序算法复杂度的下线O(n2)。
def shell_sort(original_array):
L=len(original_array)
gap = (int)(L/2)
while(gap>=1):
for i in range(gap, L):
for x in range(i-gap, -1, -gap):
if original_array[x]>original_array[x+gap]:
original_array[x], original_array[x+gap] = original_array[x+gap], original_array[x]
gap = (int)(gap/2)

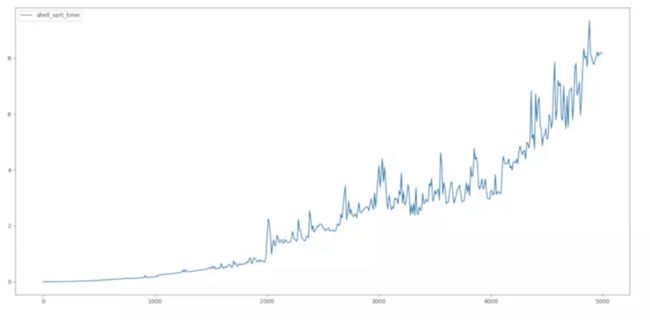
为了是大家相信,我连续跑了两次,显而易见,它并不像上面两个算法一样如此优美得符合二次曲线。其实它在N上的常系数是1.3。
简单选择排序
简单选择排序在本章描述的算法中是最慢,即使在最好的情况下(数组已经完全有序)他的时间复杂度依然需要二次方时间。可以说,它是个“很笨”的算法,从每一次遍历迭代中都不会学到什么。
def select_sort(original_array):
L = len(original_array)
for i in range(0, len(original_array)):
minimum = original_array[i]
for x in range(i+1, L):
if original_array[x] < minimum:
original_array[x], minimum = minimum, original_array[x]
original_array[i] = minimum

对于该算法不再阐述过多细节,因为没有什么好说的。
堆排序
现在我们看看堆排序,这个算法展示了如何高效地应用选择排序背后隐藏的原理。
世界杯将要来临,我们都知道世界杯有小组赛,淘汰赛。小组赛需要和小组内每个队伍比一场,而淘汰赛则是输了就回家。我想没有什么比这两种赛制更形象得来表述简单选择排序和堆排序的区别了。
当进入世界杯淘汰赛(32支队伍),每一只队伍都必须连续赢得六场比赛才可以进军决赛。而很巧的是,log(32)=5,这让我们联想到了什么?
没错,就是二叉树。
该算法由1991年的计算机先驱奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd)和威廉姆斯(J.Williams)在1964年共同发明。
步骤有三步。
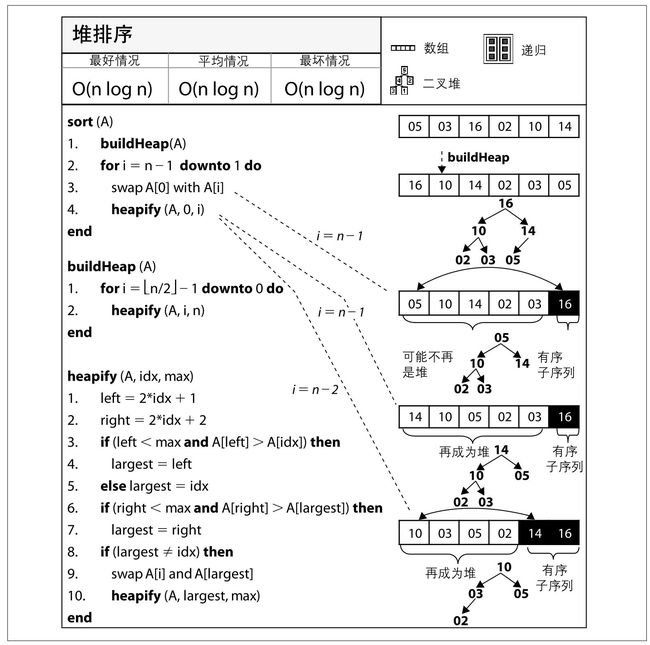
1.以原始数组为基础,建立最大堆(每个根节点上的值都不小于其左右子节点上的值)
2.经过第一步之后,该二叉树的根节点已经是为该数组的最大值了。将该根节点与二叉树末端子节点置换,然后将置换的该子节点从该二叉树中删除,这样最大值拍到了最后。
3.得到已经删除最末端子节点的二叉树,重复步骤2,直至二叉树仅仅剩下根节点,也就是最小值。
需要注意的是,数组是从0开始索引,因此该算法实现时容易在索引上出错
def adjust_max_heap(original_array, L, i):
left = 2*i + 1
right = 2*i + 2
largest = i
if (leftoriginal_array[largest]):
largest = left
if (rightoriginal_array[largest]):
largest = right
if (largest!=i):
original_array[i], original_array[largest] = original_array[largest], original_array[i]
adjust_max_heap(original_array, L, largest)
def build_max_heap(original_array):
L= len(original_array)
for x in range((int)((L-2)/2), -1, -1):
adjust_max_heap(original_array, L, x)
#堆排序
def heap_sort(original_array):
flag = 1
build_max_heap(original_array)
L = len(original_array)
for i in range(L-1, -1, -1):
flag = flag + 1
original_array[0], original_array[i] = original_array[i], original_array[0]
adjust_max_heap(original_array, i, 0)
i = i - 1
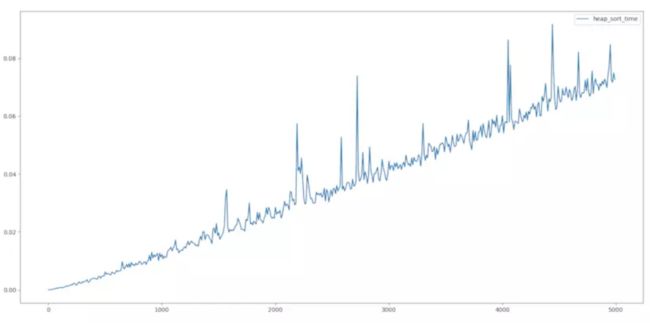
可以看出来,速度非常快,而且几乎是线性的。当然,它不是线性的,它是O(nlogn)。
快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是,通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
def quick_sort(original_array, start, end):
if start < end:
i,j,pivot = start, end, original_array[start]
while(i= pivot):
j = j - 1
if(i 
在最坏情况下,其时间复杂度退化成二次方,但在平均情况下,其效果和堆排序一样好。
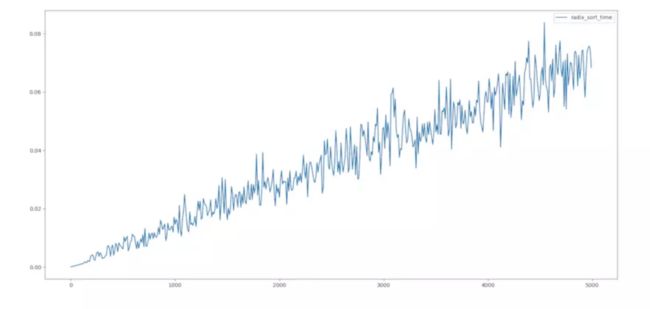
基数排序
给大家介绍一种比较巧妙的排序。看图便知其思路,独辟蹊径。

def radix_sort_nums(L):
maxNum = L[0]
for x in L:
if maxNum < x:
maxNum = x
times = 0
while (maxNum > 0):
maxNum = (int)(maxNum/10)
times = times+1
return times
def get_num_pos(num,pos):
return ((int)(num/(10**(pos-1))))%10
def radix_sort(L):
count = 10*[None]
bucket = len(L)*[None]
for pos in range(1,radix_sort_nums(L)+1):
for x in range(0,10):
count[x] = 0
for x in range(0,len(L)):
j = get_num_pos(int(L[x]),pos)
count[j] = count[j]+1
for x in range(1,10):
count[x] = count[x] + count[x-1]
for x in range(len(L)-1,-1,-1):
j = get_num_pos(L[x],pos)
bucket[count[j]-1] = L[x]
count[j] = count[j]-1
for x in range(0,len(L)):
L[x] = bucket[x]
归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。

def mergearray(L,first,mid,last,temp):
i,j,k = first,mid+1,0
while (i <= mid) and (j <= last):
if L[i] <= L[j]:
temp[k] = L[i]
i = i+1
k = k+1
else:
temp[k] = L[j]
j = j+1
k = k+1
while (i <= mid):
temp[k] = L[i]
i = i+1
k = k+1
while (j <= last):
temp[k] = L[j]
j = j+1
k = k+1
for x in range(0,k):
L[first+x] = temp[x]
def merge_sort(L,first,last,temp):
if first < last:
mid = (int)((first + last) / 2)
merge_sort(L,first,mid,temp)
merge_sort(L,mid+1,last,temp)
mergearray(L,first,mid,last,temp)
def merge_sort_array(L):
temp = len(L)*[None]
merge_sort(L,0,len(L)-1,temp)
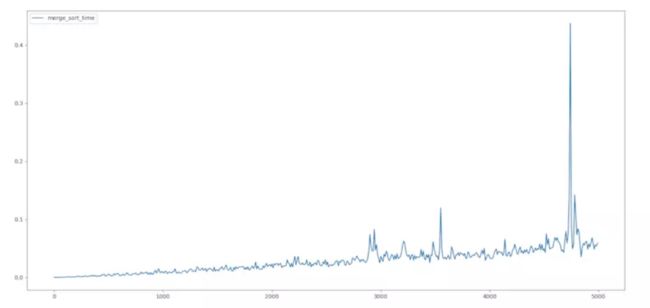
总结

从算法复杂性分析的图得知,当数据量较大时,快速排序、堆排序、归并排序、基数排序的速度都很快。其中快速排序无疑是速度最快的,当然它存在一个问题,当迭代次数再次扩大许多时,它的递归便存在问题,这涉及到快速排序的深度优化,以后会给大家讲解。
而当数据量较小,尤其是原始数组大部分情况下本来就是有序的情况下,插入排序是最佳选择。
转自: https://www.jianshu.com/p/18e81f6484db
如有侵权,请告之删除,谢谢。仅供学习