**基于Kubernetes的多维度的弹性伸缩**目录:
2.1 传统弹性伸缩的困境
2.2 kubernetes 弹性伸缩布局
2.3 Node 自动扩容/缩容
2.4 pod自动扩容/缩容 (HPA)
2.5 基于CPU指标缩放
2.6 基于prometheus自定义指标缩放
2.1 传统伸缩的困境从传统意义上,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾
蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。
弹性伸缩就是要解决当实际负载增加,而集群资源容量没来得及反应的问题。
传统的理解,比如有几台web服务器,负载高了加机器,然后负载下去减机器
传统的弹性伸缩和k8s的弹性伸缩有什么区别?
从传统意义上来说,其实k8s的弹性伸缩也是大家比较关注的一个话题,但是考虑起k8s上的弹性伸缩就不得不从传统的弹性伸缩谈起,看看传统伸缩和k8s的弹性伸缩有什么不同之处,从传统来将解决的问题是容量规划与实际负载的矛盾,为什么这么讲,从上面这张图可以看出蓝色的是可用资源,红色的是实际负载,蓝色的是好比就是集群池,好比是一个web,这里有4台服务器,容量都是4c8g,一共十16c,32g,这样的一个容量,那么比如双十一来了,那么你的负载高了,那么可能需要18c,36g这样的一个负载,那么这个本身的这个资源池肯定是不够用的了,超出了可用的范围,这就是实际负载,这个时候我们就得扩容,考虑的是赶紧扩容机器,再扩容一台,或者更多,来应对实际的负载,其实弹性伸缩就是这么来的,当出现资源利用率的触发时,能够快速的响应快速的扩容,在传统的这样的一个方式下可能会有点慢,就是还没来的及反应呢,就已经超出你的负载了,因为实际负载面对一些活动的时候,都是一些比较快的突发事件,你没有做好任何准备,一下超过你的负载,说为什么矛盾,其实就是可用资源和实际负载之间,关键的挑战其实就在这,能不能快速的弹出,快速的回收,就是这个资源池能不能快速的放大,能不能在低峰期收来降低成本,这是我们考虑的,但是这个做好的确还是很难的,所以从之前考虑的弹性伸缩,能不能快速的弹出,目前就是提前增加服务器,没有一些好的办法,所以就是解决这个矛盾,像一些快速的流量能不能响应起来。
如果已知的活动,那么提前扩容这个服务器,基本都是这么来的,包括双十一了,淘宝京东都是,像阿里,他们本身就有一个庞大的资源池,他们双十一会将他们大量的业务,都会放在这个池子里,并且预留很多的资源,然后给这个集群去使用,像我们一般都是提前去加服务器,包括云上也是。
其实放在k8s中也不是解决这个矛盾,弹性伸缩就是解决容量规划与实际负载的矛盾,但真正的没有快速的弹出快速的回收,但是弹性伸缩还是停留在至此,但是有了k8s之后,在k8s与这种传统的又有一种区别了,没有特别好的方案去解决,现在呢在k8s也能按原来的思路去走,具有有两方面的考虑,之前的弹性伸缩是基于什么样的方式去扩展呢?如果放我们传统的资源池已经超出我们原本的容量,怎么判断要自动的加机器呢,即使弹出的时间比较慢,也得做这个事,不可能说有效的去响应这个资源池,那就不去弹出,那么还是有个策略,这个策略是怎么做的,根据怎么样的预值去做,一般就是根据cpu和内存,一般都是根据这些去做云主机的弹性伸缩,除了这些也没有什么好方法,像公有云aws,像阿里云也都是这种形式,就是你设置一个预值,如果整体的资源超出了这个预值,就加机器,但是一般服务器都有一定的预留,一般也不会一下都把它打满了,除非有一些异常,大多数情况下这个集群池都有一些预留,根据之前访问的一个趋势,做一个20%和30%的预留,给你一个缓冲的时间,一下来个20%的访问量就打垮了,这样也不太行,所以增加这些预留,要保证集群的可用性。
在k8s中去这种传统的部署就是基于cpu利用率的百分比来讲,可能就不太现实。
1、Kubernetes中弹性伸缩存在的问题
常规的做法是给集群资源预留保障集群可用,通常20%左右。这种方式看似没什么问题,但放到Kubernetes中,就会发现如下2个问题。
1. 机器规格不统一造成机器利用率百分比碎片化
在一个Kubernetes集群中,通常不只包含一种规格的机器,假设集群中存在4C8G与16C32G两种规格的机器,对于10%的资源预留,这两种规格代表的意义是完全不同的。
像一些传统的web,服务器的规格基本都是一样的,一般使用轮询,很少去用最小连接数,轮训的话,要是规格不一样,服务器就是浪费,有一台是4核8g,有一台是16核32g,要是轮询的大的那一个就是在浪费钱,基本在权重值都一样。
要是上云的话,基本上配置都是统一的,扩容也是,像idc可能会有一些规格不一样的,为了把这些资源都利用上,但是在k8s中,加的这些机器没必要统一,甚至拿一些高配的服务器堆起来一个k8s机器,因为k8s本身就是给你拿一个大的资源池来用了,也就是逻辑上将他们作为一个资源池来用了,k8s统一的去调度,他会判断这个资源能不能去调度,根据你这个实际的利用率,而不是根据轮询来了,这样的话,就会保证你每个节点,你的利用率都是比较高的,所以这就是一个大的资源池,所以不同规格的机器来说,都没有太大的影响,但是对于弹性伸缩来说,它就有影响。
比如有三台服务器,一个4c 8g , 一个16c 64g.,一个8c 16g,要是你还是基于之前的cpu,内存的方式去弹性伸缩,说白了就是扩容,缩容,
比如都是利用率都是80%,这肯定是不一样的,因为规格的不同,它的百分比也不同,要是按这种的node的扩容,这显然也是不行的,
行是可以,按照缩容来说,有三台机器,负载下来了,所以说要评估出哪个节点,再找空闲的节点去缩容,正好这三台机器都空闲一点,判断的肯定是以cpu和内存,如果都是80%,缩小的是配置低的,那么缩容没有太多的意义了,但是你缩容大规格的,那可能会导致,我一下很缩容很大,整体的集群利用率就会下降很多,所以就面对这些问题,也主要是缩容面对的问题。特别是在缩容的场景下,为了保证缩容后集群稳定性,我们一般会一个节点一个节点从集群中摘除,那么如何判断节点是否可以摘除其利用率百分比就是重要的指标。此时如果大规则机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢。如果优先缩容小规则机器,则可能造成缩容后资源的大量冗余。
2. 机器利用率不单纯依靠宿主机计算
在大部分生产环境中,资源利用率都不会保持一个高的水位,但从调度来讲,调度应该保持一个比较高的水位,这样才能保障集群稳定性,又不过多浪费资源。
像k8s申请规格的话,一般就根据两点,第一个就是request,项目参考的预值,第二个就是limit的最大资源的限制,一般缩容扩容会根据request去考虑,比如申请的规格是2c2g,那么缩容肯定要考虑pod的,申请多少的规格就要预留这些规格,并不是我申请了2c2g,但是我没考虑什么负载,那么不可能说我缩容的时候把这个考虑在内,我就按实际的负载来算,肯定不行,我要算这个集群中2c2g来算,集群资源部单纯靠宿主机来算,一共两个维度,一个pod,一个request,就好比之前单纯看节点增加了一个维度,所以做这个弹性伸缩就要把这个考虑进去,并不是说我申请了request2c2g,用不到2c2g,去伸缩的时候,你要把它按实际的负载用,那到时候你缩容之后,万一你申请的request的资源利用率上来了,那么你剩余的节点上是不是不够了,到时候会造成pod的争抢,再争抢你增加节点的时候会受一定影响,所以这就是第二个存在的问题
怎么解决这些问题?
第一个就是机器规格不统一利用率的百分比,其实最好的形式就是,就从概念去看,把配置做成一样,但是这种情况不太现实,,因为公司采购的服务器,包括遗留的这些机器,都是为了合理利用上,来做这个集群池,但是你拿一些新的机器可以将这些都搞成一样的,但是规格不一样就不太行了。
第二个就是机器部单纯依靠宿主机计算,这一块考虑缩容,即使要参考node的利用率,还要参考整个集群中pod请求的request,必须把request这个规格实际的负载计算进去,不能按实际的负载,这些呢都是一些手段了。
现在一般来说都是一些成本的节省和可用之间的矛盾,既然业务已经多元化了,解决这个问题就可以将这些业务进行分类
2、弹性伸缩概念的延伸
不是所有的业务都存在峰值流量,越来越细分的业务形态带来更多成本节省和可用性之间的跳转。
1. 在线负载型:微服务、网站、API
2. 离线任务型:离线计算、机器学习
3. 定时任务型:定时批量计算不同类型的负载对于弹性伸缩的要求有所不同,在线负载对弹出时间敏感,离线任务对价格敏感,定时任务对调度敏感。
像传统的负载型的就可以使用这个在线负载型的,然后就是离线型的,离线计算,机器学习,这些都是周期性的,可能定时性的并不是实时在线的,这一类比较关心的是,比较敏感,这一类的就是当我工作的时候消耗是比较多的,比在线负载型的消耗真的很多,比如大数据的处理,机器的学习,这一块呢就是某一刻的时间比较高,所以要考虑这个成本,所以不能说,它都是离线任务,偶尔大,然后机器又是峰值的配值规格,那种价格规格会高很多,第三种就是这种定时任务型的,定时批量计算,比如调度了,定时的去做一些事了,然后备份了这一块了,这一块可能对调度比较敏感一些,然后任务比较多的时候,会有一个全局调度系统,然后调度的去分配,所以它对调度比较敏感一些,所以弹性伸缩的概念延伸到了业务去合理的区分,比如在线负载型的考虑的是还是按之前的那种方式,考虑弹出时间的,就是扩容的敏感,像微服务,网站,API,如果负载比较到的话,能不能增加机器,离线任务就是对某一刻时间段的敏感,能不能用的时候提供足够的资源,不用的时候能不能回收掉,让其他的资源去用,这样的话,就可以去省一些开销,定时任务的也是。
接下来就是怎么在k8s中去布局,这就是我们去考虑的了,不能按照宿主机的利用率了,多了一个维度,所以在k8s的生态中,针对上面不同形态的业务,弹性伸缩的形式也有很多的组件,以及各种各样的场景
大致分为了三种弹性伸缩
2.2 kubernetes 弹性伸缩布局
在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。
有三种弹性伸缩:
• CA(Cluster Autoscaler):Node级别自动扩/缩容
cluster-autoscaler组件
• HPA(Horizontal Pod Autoscaler):Pod个数自动扩/缩容
• VPA(Vertical Pod Autoscaler):Pod配置自动扩/缩容,主要是CPU、内存
addon-resizer组件如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
就像创建新的pod,一个等待状态,就不会去给你调度了,资源没给你调度,pod如果超出request的规格,而且我的资源池,是不是稳定,就像在线负载型的,就是能允许等待时间增加新的节点,所以request在限制的情况下,如果request都打满,但是这个集群已经不能分配新的pod了,这个集群还是稳定状态,因为它还有一个最大的限制limit如果超出这个限制的话这个集群就会出现不稳定的状态,那么就需要去扩容node节点了,所以node就提供了这种自动的扩容,提供了这个组件,CA (cluster autoscaler)来实现node级别的自动扩缩容,这个组件目前主要对接的是公有云,比如阿里云,微软云,aws之类的他们的组件,你可以实现,调度他们的云主机,来实现自己的扩容缩容,当然也可以自己去研究类似得组件,来实现自动的扩容缩容,第二种就是基于这个pod的,其实它主要是针对你现有的资源池的,如果你现有的资源池是比较充裕的,那么我再调度新的pod,是没问题的,也能去调度出来,也就是本身你的应用10个副本,即使request跑满,10个并发是1万,现在的负载不够了,现在要扩容副本,扩容20个副本那么我的并发就是2万了,但我集群池的资源够,所以就能应对我现在的业务的负载,所以在针对k8s的扩容的时候,一般将就针对两个维度进行扩容缩容,一个就是node,一个就是pod,然后第三个维度,这个不经常用,上面两个都是按水平进行考量的,第三个是pod的横向扩展,横向是指limit这个规格,帮你加这个配额,目前这个还比较少,目前就是node和pod的这个用的比较多,如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
2.3 Node 自动扩容/缩容
1、Cluster AutoScaler
扩容:Cluster AutoScaler 定期检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。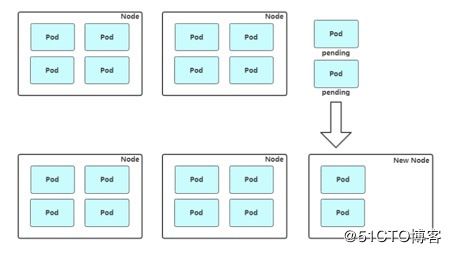
缩容:Cluster AutoScaler 也会定期监测 Node 的资源使用情况,当一个 Node 长时间资源利用率都很低时(低于 50%)自动将其所在虚拟机从云服务商中删除。此时,原来的 Pod 会自动调度到其他 Node 上面。
支持的云提供商:
要是使用它们云厂商的就可以使用它们的的组件解决去用,一般他们都对接完成了。
• 阿里云:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
• AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
• Azure: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
3.2 Ansible扩容Node
第三种就是我们人工干预的去进行扩容缩容了,这是普遍自建采用的一种手段,
1. 触发新增Node
2. 调用Ansible脚本部署组件
3. 检查服务是否可用
4. 调用API将新Node加入集群或者启用Node自动加入
5. 观察新Node状态
6. 完成Node扩容,接收新Pod未完待续