牛顿方法
之前我们在最大化对数似然函数l(θ)时用到了梯度上升法,现在我们介绍另一种方法。
我们先来看下如何用牛顿方法(Newton's Method)求解θ使得f(θ)=0。如下图所示,首先我们选取一个初始点,比如说令θ=4.5,然后作出f(θ)在该点的切线,这条切线与x轴相交的点θ=2.8作为下一次迭代的点。下右图又一次重复了一轮迭代,f(θ)在θ=2.8处的切线与x轴相交于θ=1.8处,然后再次迭代到θ=1.3处。

以此类推,我们得到迭代规则如下:
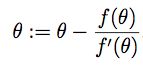
牛顿方法可以找到θ使得f(θ)=0,那么如何把它应用到最大化l(θ)上呢?当l(θ)达到最大点时,其导数为0,因此问题转化为找到θ使得l'(θ)=0。所以,令f(θ)=l'(θ),我们推导出迭代规则:

上式中的θ是参数为实数的情况,当θ为向量时,我们可以推导出更通用的公式:
其中∇θl(θ)是指l(θ)的梯度,H是一个n * n的矩阵,被称为海森矩阵(Hessian Matrix)。

和梯度下降法相比,牛顿方法收敛的速度更快,迭代的次数也更少。但是牛顿方法每次迭代的计算量更大,因为每次都要计算一个n阶矩阵的逆。总体而言,当n不是很大时牛顿方法计算的速度更快。当牛顿方法用来求解最大化对数似然函数l(θ)时,这个方法也被称为Fisher Scoring。
指数分布族
到目前为止,我们分别学习了分类(classification)和回归(regression)两类问题。在回归问题里,我们假设p(y|x;θ)服从高斯分布N(0,σ2);在分类问题里,我们假设p(y|x;θ)服从伯努利分布B(φ)。后面我们会看到,这两类问题可以被统一到一个更通用的模型,这个模型被称为广义线性模型(Generalized Linear Models, GLM)。在介绍GLM前,我们先引入一个概念:指数分布族(exponential family)。
指数分布族是指一类可以被表示为如下形式的概率分布:
其中η被称为分布的自然参数(natural parameter),或者是标准参数(canonical parameter);T(y)是充分统计量(sufficient statistic),通常T(y)=y;a(η)是对数分割函数(log partition function)。e-a(η)通常起着归一化的作用,使得整个分布的总和/积分为1。
如果固定参数T, a, b,就定义了一个以η为参数的函数族。当η取不同的值,我们就得到一个不同的分布函数。
现在我们来证明高斯分布(Gaussian distribution)和伯努利分布(Bernoulli distribution)都属于指数分布族。
对于伯努利分布B(φ),其y值为0或1,因而有p(y=1;φ)=φ; p(y=0;φ)=1-φ 。所以可推导p(y;φ)如下:
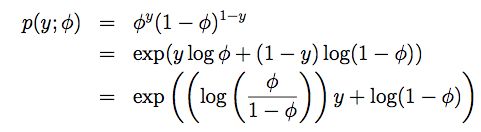
对比指数分布族的定义,可得η=log(φ/(1-φ)),进而可得φ=1/(1+e-η),而这正是sigmoid函数的定义。同样对比其他参数,可得:
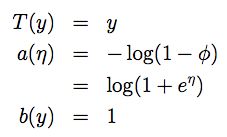
综上可得,伯努利分布属于指数分布族,且φ的形式与sigmoid函数一致。
接下来我们继续来看高斯分布N(μ,σ2)。回忆下之前推导线性回归的时候,σ2的值与θ和hθ(x)无关,因此为了简化证明,我们令σ2=1,所以可推导p(y;μ)如下:
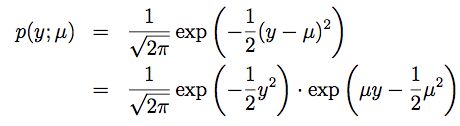
对比指数分布族的定义,进而可得:
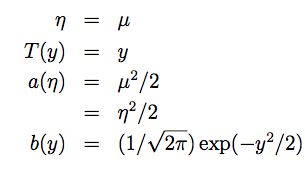
因而我们证明了高斯分布也属于指数分布族。事实上,大多数概率分布都属于指数分布族,我们列举一些如下:
- 多项式分布(Multinomial distribution):对有k个离散结果的事件建模
- 泊松分布(Poisson distribution):描述单位时间内独立事件发生次数的概率
- 伽马分布(Gamma distribution)与指数分布(Exponential distribution):描述独立事件的时间间隔的概率
- β分布(Beta distribution):在(0,1)区间的连续概率分布
- Dirichlet分布(Dirichlet distribution):分布的分布(for distributions over probabilities)
广义线性模型
介绍完指数分布族后,我们开始正式介绍广义线性模型(GLM)。对回归或者分类问题来说,我们都可以借助于广义线性模型进行预测。广义线性模型基于如下三个假设:
- 假设1: p(y|x;θ) 服从以η为参数的指数分布族中的某个分布
- 假设2: 给定x,我们的目标是预测T(y)的期望值,大多数情况下T(y)=y,所以假设函数可以写为h(x)=E[T(y)|x]
- 假设3: η与x是线性相关的,即η=θTx
依据这三个假设,我们可以推导出一个非常优雅的学习算法,也就是GLM。接下来我们分别看几个通过GLM推导出来的算法。
最小二乘法
假设p(y|x;θ)服从高斯分布N(μ,σ2),我们可以推导如下:
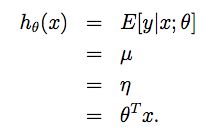
上式中第一个等号来自假设2,第二个等号是高斯分布的特性,第三个等号
来自上一节中我们已经证明了η=μ,第四个等号来自假设3。
逻辑回归
假设p(y|x;θ)服从伯努利分布B(φ),我们可以推导如下:
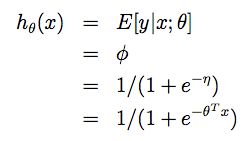
上式中第一个等号来自假设2,第二个等号是伯努利分布的特性,第三个等号
来自上一节中我们已经证明了φ=1/(1+e-η),第四个等号来自假设3。
这里多介绍一些术语:将η与原始概率分布中的参数联系起来的函数g(即g(η)=E[T(y);η])称为标准响应函数(canonical response function),它的逆函数g-1称为标准关联函数(canonical link function)。
Softmax回归
接下来我们来看一个更复杂的模型。在分类问题上,我们不止预测0和1两个值,假设我们预测的值有k个,即y∈{1,2,…,k}。那么我们就不能再使用伯努利分布了,我们考虑用多项式分布(Multinomial distribution)建模。
我们用φ1, φ2, ... ,φk表示每个结果出现的概率,即P(y=k)=φk。由于所有结果概率之和为1,所以实际上k个参数中有1个是多余的,即:
为了使多项式分布能表示成指数分布族的形式,我们定义T(y)如下:

和我们之前的例子不一样,T(y)这次不等于y,而是一个k-1维的向量。我们用(T(y))i表示T(y)的第i个元素。
接下来我们引入指示函数(indicator function):1{·}。如果参数表达式为真,则指示函数取值为1;表达式为假,指示函数取值为0,即1{True} = 1, 1{False} = 0。基于上述定义,我们可以得到:(T(y))i = 1{y = i},进一步可得:
现在我们可以证明多项式分布也属于指数分布族,证明如下:
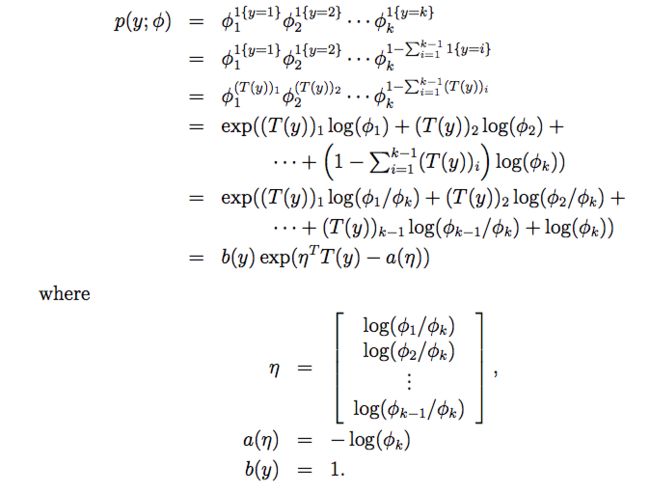
由η的表达式,我们可以得到η和φ的对应关系:
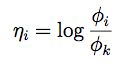

这个从η和φ的映射函数被称为softmax函数(softmax function)。有了softmax函数并结合假设3,我们可以求出p(y|x;θ)为:
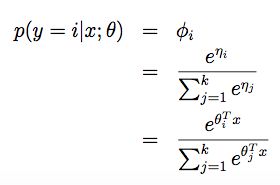
这个k分类问题的算法被称为softmax回归(softmax regression),它是逻辑回归更一般化的形式。
最后我们可以求出假设函数:
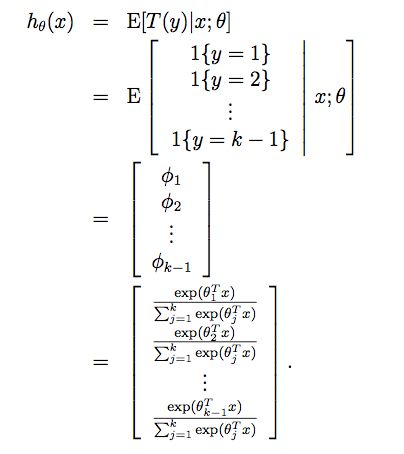
如果要求解参数θ,我们可以先求出它的对数似然函数l(θ),然后用梯度上升或牛顿方法进行迭代。
总结
- 梯度上升和牛顿方法都能用于求解最大化l(θ)的问题,区别是牛顿方法收敛速度更快,但是它每次迭代的计算量也更大,当数据规模不大时总体上性能更优
- 指数分布族描述了一大类我们常见的概率分布,高斯分布、伯努利分布、多项式分布等都属于指数分布族
- 广义线性模型(GLM)描述了一种更通用的学习模型,最小二乘法和逻辑回归都可以从GLM推导出来
- k分类问题可以用softmax回归建模,逻辑回归可以看作是softmax回归的特例(k=2)
参考资料
- 斯坦福大学机器学习课CS229讲义 pdf
- 网易公开课:机器学习课程 双语字幕视频