
作者 | 肖长军(穹谷)阿里云智能事业群技术专家
导读:随着云原生系统的演进,如何保障系统的稳定性受到很大的挑战,混沌工程通过反脆弱思想,对系统注入故障,提前发现系统问题,提升系统的容错能力。ChaosBlade 工具可以通过声明式配置执行混沌实验,简单高效。本文将会重点介绍 ChaosBlade 以及云原生相关的实验场景实践。
ChaosBlade 介绍
ChaosBlade 是阿里巴巴开源的一款遵循混沌实验模型的混沌实验执行工具,具有场景丰富度高、简单易用等特点,而且可以很方便的扩展实验场景,开源后不久就被加入到 CNCF Landspace 中,成为主流的一款混沌工具。
实验场景
目前支持的实验场景如下:
-
基础资源场景:CPU 负载、内存占用、磁盘 IO 负载、磁盘占用、网络延迟、网络丢包、网络屏蔽、域名不可访问、shell 脚本篡改、杀进程、进程 Hang、机器重启等;
-
应用服务场景:支持 Java 应用和 C++ 应用内的实验场景。Java 的场景组件丰富,例如支持 Dubbo、RocketMQ、HttpClient、Servlet、Druid等,而且支持编写 Java 或 Groovy 脚本实现复杂的实验场景;
- 容器服务场景:支持 Kubernetes 和 Docker 服务,包含 node、pod 和 container 三种资源的实验场景,例如 Pod 网络延迟、丢包等。
混沌实验模型
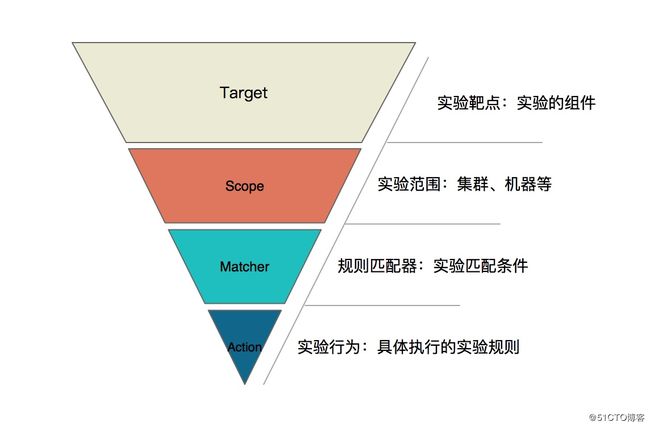
以上所有的实验场景都遵循混沌实验模型,此模型共分为四层,包含:
- Target:实验靶点。指实验发生的组件,如容器、应用框架(Dubbo、Redis)等;
- Scope:实验实施的范围。指具体触发实验的机器或者集群等;
- Matcher:实验规则匹配器。根据所配置的 Target,定义相关的实验匹配规则,可以配置多个。由于每个 Target 可能有各自特殊的匹配条件,比如 RPC 领域的 Dubbo,可以根据服务提供者提供的服务和服务消费者调用的服务进行匹配,缓存领域的 Redis,可以根据 set、get 操作进行匹配;
- Action:指实验模拟的具体场景,Target 不同,实施的场景也不一样,比如磁盘,可以演练磁盘满,磁盘 IO 读写高等。如果是应用,可以抽象出延迟、异常、返回指定值(错误码、大对象等)、参数篡改、重复调用等实验场景。
比如一台 IP 是 10.0.0.1 机器上的应用,调用 com.example.HelloService[@1.0.0 ]() Dubbo 服务延迟 3s,基于此模型可以描述为对 Dubbo 组件(Target)进行实验,实验实施的范围是 10.0.0.1 主机(Scope),调用 com.example.HelloService[@1.0.0 ]() (Matcher)服务延迟 3s(Action),对应的 chaosblade 命令为:
blade create dubbo delay --time 3000 --service com.example.HelloService --version 1.0.0所以此模型很简单清晰的表达出实验场景,易于理解。下文中的云原生实验场景也基于此模型定义。
面向云原生的实验场景
实现方案
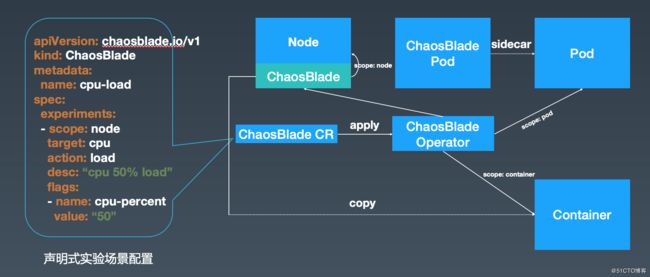
将混沌实验场景按照上述的实验模型,定义为 Kubernetes 中的资源,并通过自定义控制器来管理,可以通过 Yaml 配置或者直接执行 blade 命令执行。
ChaosBlade Operator 定义了资源控制器,并且会以 daemonset 的方式,在每个节点上部署一个 chaosblade-tool pod 来执行混沌实验。不同的实验场景内部实现方式不同,比如 Node 实验场景,其上面部署的 chaosblade-tool 内部执行即可,而 Container 内的实验场景,控制器会将 chaosblade 包拷贝到目标 Container 中执行。
使用方式
安装必要组件
安装 ChaosBlade Operator,可通过地址下载 chaosblade-operator-0.0.1.tgz,使用以下命令安装:
helm install --namespace kube-system --name chaosblade-operator chaosblade-operator-0.0.1.tgz安装在 kube-system 命令空间下。ChaosBlade Operator 启动后会在每个节点部署 chaosblade-tool Pod 和一个 chaosblade-operator Pod。可通过以下命令查看安装结果:
kubectl get pod -n kube-system -o wide | grep chaosblade
执行实验
执行方式有两种:
- 一种是通过配置 yaml 方式,使用 kubectl 执行;
- 另一种是直接使用 chaosblade 包中的 blade 命令执行。
下面以指定一台节点,做 CPU 负载 80% 实验举例。
yaml 配置方式
apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: cpu-load
spec:
experiments:
- scope: node
target: cpu
action: fullload
desc: "increase node cpu load by names"
matchers:
- name: names
value:
- "cn-hangzhou.192.168.0.205"
- name: cpu-percent
value:
- "80"如上所示,配置好文件后,保存为 chaosblade_cpu_load.yaml,使用以下命令执行实验场景:
kubectl apply -f chaosblade_cpu_load.yaml可通过以下命令查看每个实验的执行状态:
kubectl get blade cpu-load -o json查看更多实验场景配置事例。
blade 命令执行方式
下载 chaosblade 工具包,解压即可使用。还是上述例子,使用 blade 命令执行如下:
blade create k8s node-cpu fullload --names cn-hangzhou.192.168.0.205 --cpu-percent 80 --kubeconfig ~/.kube/config使用 blade 命令执行,会返回实验的执行结果。
修改实验
yaml 配置文件的方式支持场景动态修改,比如将上述的 cpu 负载调整为 60%,则只需将上述 value 的值从 80 改为 60 即可,例如:
apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: cpu-load
spec:
experiments:
- scope: node
target: cpu
action: load
desc: "cpu load"
flags:
- name: cpu-percent
value: "60"
- name: ip
value: 192.168.0.34然后使用 kubeclt apply -f chaosblade_cpu_load.yaml 命令执行更新即可。
停止实验
可以通过以下三种方式停止实验:
根据实验资源名停止
比如上述 cpu-load 场景,可以执行以下命令停止实验:
kubectl delete chaosblade cpu-load通过 yaml 配置文件停止
指定上述创建好的 yaml 文件进行删除,命令如下:
kubectl delete -f chaosblade_cpu_load.yaml通过 blade 命令停止
此方式仅限使用 blade 创建的实验,使用以下命令停止:
blade destroy 是执行 blade create 命令返回的结果,如果忘记,可使用 blade status --type create 命令查询。
卸载 chaosblade operator
执行 helm del --purge chaosblade-operator 卸载即可,将会停止全部实验,删除所有创建的资源。
总结
ChaosBlade 基于混沌实验模型,友好地将 Kubernetes 资源控制结合,部署简单而且使用简洁,实验可控。除此之外 ChaosBlade 基于实验模型实现了很多领域场景执行器,可以很方便的扩展实验场景,可详见附录中的项目列表。
社区共建
ChaosBlade 自开源以来,共有近 30 多位贡献者加入和很多企业×××常感谢各位。同时非常欢迎更多的人参与进来,使 ChaosBlade 变的更加强大,覆盖更多的场景,成为各个企业稳定的、通用的混沌工程工具。
贡献的形式可以是提 bug、提交代码、编写文档、补充单元测试、参与问题讨论等等。ChaosBlade 相信:开源世界中,任何帮助都是贡献。
附录
项目列表如下:
- ChaosBlade CLI(调用入口)
- ChaosBlade 实验模型定义
- 基础资源场景执行器
- Docker 场景执行器
- Kubernetes 场景执行器
- Java 应用场景执行器
- C++ 应用场景执行器
“ 阿里巴巴云×××icloudnative×××erverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发×××