癸巳即将过去,总得点礼物吧,思来想去,觉得写写GOOGLE分布式数据库技术发展情况,以此作为礼物献给自己,聊以×××,由于时间有限,加之对于GOOGLE的分布式数据库理解也只能盲人摸象,难免有错误之处,敬请谅解。
GOOGLE的分布式数据库系统从BIGTABLE的正式推出后,先后对外发布了Bigtable、Dremel、 Spanner等不同的分布式数据库产品,有的是引入新的设计实现,有的是针对原有的技术进行改进和优化,用于满足不同的GOOGLE的应用场景,支持日益增加的数据量管理要求。
GOOGLE分布式数据库技术,从个人理解看,可以分为三个阶段,第一阶段以Bigtable产品为代表,实现了数据的分布式存储、行数据的事务性管理和较好的扩展性,从存储WEB页面而生,创造性提出了KEY-VALUE这种MAP数据结构,并广泛应用到GOOGLE的各种应用中,与GOOGLE的MapReduce GFS技术搭配,构成了GOOGLE分布式云计算的三架马车,对应开源社区推出HBASE产品,也在近年得到了广泛应用。
第二个阶段以Dremel产品为代表,Dremel产品采用了与Bigtable不同的数据结构,立足实时对于海量数据进行分析,据说在秒级可以完成PB级别的数据分析和处理,可以做是分布式数据库实时处理的杰作,其实时处理能力达到令人惊艳的速度。
第三阶段以Spanner数据库技术为代表,Spanner数据库在可以做到多数据表事务一致性管理,利用原子时钟(TrueTime)和Paxos协议解决了分布式数据库多表事务一致性管理的难题,打破的CAP不可三者兼得的理论神话,使得分布式数据库技术得到了革命性的进步。
严格来讲Dremel与Bigtable和Spanner解决的问题有所不同,Dremel侧重于对应海量数据的实时处理,而Bigtable和Spanner更侧重于传统的关系型数据库支持功能对齐和替换,并不是简单产品替换关系。从GOOGLE的分布式数据库技术的发展历程看,这些技术得以成功推出,有创造性的新锐视角和解决方案,更有其坚持在廉价PC服务器上面构筑海量数据处理系统的理想和情怀,更有起高超的技术实力和团队合作,这些因素的结合,使得技术难关被不断的突破,分布式数据库产品得以大成,这些产品的确值得技术人员去深入学习和体会。
为了更好的对比和分析GOOGLE的分布式数据库技术,本文从Bigtable、Dremel、Spanner数据模型、系统架构、数据查询原理、应用场景进行深入分析,最后对于其特点进行对比,从而使得读者对应GOOGLE的分布式数据库技术有一个初步的认识。
2 BIGTABLE开山壁祖
2.1 Bigtable的数据模型
2.1.1 Bigtable的Key-Value数据结构
Bigtable采用Key-Value数据结构,Key由行关键字、列关键字、时间戳组合而成,Value为对应数据内容,行关键字和列关键字都是字符串数据类型,时间戳是一个64位的长整数,精确到毫秒的时间戳,这三个属性在一个数据库中全局唯一,由Key和Value构成的KV数据结构称为一个数据项,考虑到分布式数据库的多复本的特性,数据项会按照时间戳进行排序,并对于过期的数据项进行过期回收,其数据结构如图2-1所示。
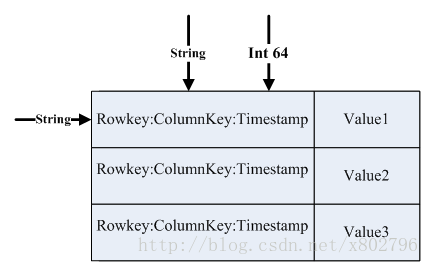
图2-1 Bigtable KV结构示意图
2.1.2 Bigtable的数据模型层次
Bigtable数据模型由下而上,主要部件可以初分为四个层面,最底层为SSTABLE,存放在GFS分布式文件系统中,为数据存储MAP结构体,第二层TABLET结构体,一个表可以由一个或者多个Tablet构成,由一系列的SSTABLE构成,第三层TABLET服务器,管理一组TABLET数据体,最上层Bigtable数据库,由多个TABLET服务器和一个Master服务器、客户端访问连接支持软件构成,最终形成了一个分布式数据库,对外提供数据库服务,层次关系如图2-2所示。
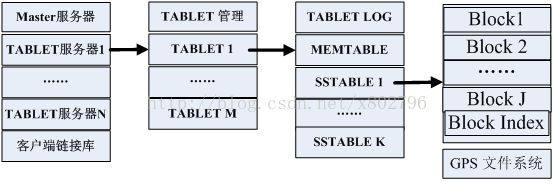
图2-2 Bigtable各级数据模型视图
数据项基于一种叫做SSTABLE的数据格式,SSTABLE是一种持久化、排序的、不可更改的MAP数据结构,每一个SSTABLE由一系列数据块构成,在每一个SSTABLE的最后存储着块索引,SSTABLE使用这些索引来定位数据块,在每一个SSTABLE被打开时,块索引会自动加载到内存中。SSTABLE提供了二种数据访问方式,第一种方式,使用二分法查找内存中的块索引,根据对应的块索引把对应的数据块读取到内存中,此种方式只会发起一次磁盘寻址,第二种方式是把整个SSTABLE都整体加载到内存中。SSTABLE基于GOOGLE GFS全局文件系统基础上,实现对应文件系统层面的负载均衡和IO能力分担,
从特点看,BIGTABLE不直接支持对应数据的修改操作,通过时间戳方式来间接支持数据修改。数据读取方式,提供了二种不同的机制,二分法的块索引定位加载,类似于ORACLE提供的索引访问方式;SSTABLE的全部加载,类似于ORACLE提供的全表扫描机制,从技术角度看,不管分布式数据库技术本身如何发展,对小粒度数据精确加载和整体数据加载的场景,从这点看,所有的数据库存储结构应该都是殊途同归。
一个TABLET由TABLET Log存储TABLET的提交数据的Redo 记录数据,MEMTABLE是内存缓存,存储最近访问的记录数据,数据持久化到一组SSTABLE文件中。
最上层Bigtable数据库服务层,对外提供Bigtable的数据库服务功能,为Bigtable的最顶层结构。
2.2 Bigtable的系统架构
Bigtable由客户端连接库、Master服务器、TABLET服务器组构成,客户端链接库提供数据库客户端访问功能,提供服务端访问,比如对于数据寻址的缓存信息; Master服务器负责TABLET服务器组的管理,根据负载情况,可以动态的增加和删除TABLET服务器,维护TABLET服务器组;TABLET服务器管理该服务器上面的TABLET集合,完成TABLET数据读取和写入操作,当TABLET太大时,对TABLET进行拆分,在一个Bigtable中只能有一个Master服务器,通过Chubby保证Master服务器的唯一性;Chubby服务提供了TABLET根信息服务、系统Master管理和TABLET服务出错的善后处理任务,保存Bigtable数据库Schema信息。Bigtable整个系统架构如图2-3所示。
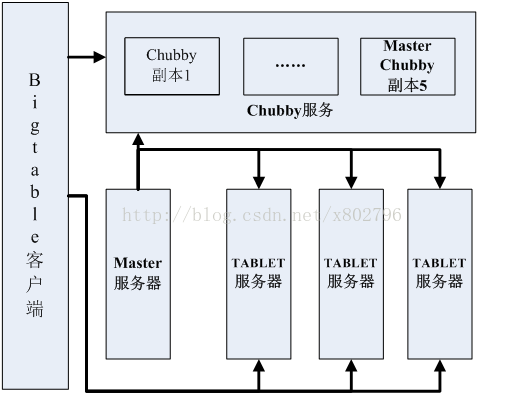
图2-3 Bigtable系统架构图
2.3 Bigtable的数据查询
2.3.1 Bigtable的数据定位
Bigtable数据查询,首先是对于数据所在tablet进行定位,Bigtable的位置定位,分为三个步骤。
第一步,客户端程序在缓存中查找tablet位置是否在缓存中存在,如果在缓存中存在就直接读取,如果不存在,通过Chubby服务器查询tablet的根节点,取到Bigtable根节点tablet信息;
第二步,根据Bigtable根节点的tablet信息,找到数据对应METADATA的数据表,该数据表中存储着所有的用户数据tablet的位置信息;
第三步,根据METADATA的数据表存储的用户数据tablet信息,找到数据对应tablet信息,根据该位置信息,读取到tablet数据到客户端。
2.3.2 Bigtable的数据读取
Bigtable数据读取时以Tablet为单位,必须读取到构成该Tablet所有涉及到SSTABLE,发起读取操作时,首先要对操作完整性和权限做检查,检查通过后,首先在Tablet服务器所在的缓存里面查找,Bigtable提供二级缓存缓存,一种是以Key-Value形式的一级数据缓存,如果在这种级别中的缓存中无法找到,访问二级数据缓存,二级数据是SSTABLE的BLOCK数据缓存,对于热点局部性数据来讲,这种BLOCK环境命中率很高,对于系统性能改善更加有效。
在数据缓存中如果没有找到对应的读取数据,启动数据定位的三个步骤,完成对于TABLET的位置信息读取,TABLET信息读取转换为对应SSTABLE数据,根据SSTABLE数据是否进行了压缩,对于涉及到该TABLET的SSTABLE进行解压操作,完成读取后返回到客户端。
2.3.3 Bigtable的数据写入
Bigtable数据写入时,首先是坚持该操作数据格式是否正确,并判断该操作发起者是否有该操作的权限,权限判断是通过存储在Chubby服务器上面的权限控制表来判断。判断操作发起者具备该操作的权限后,会发起具体写入数据动作,该动作是一个事务操作,操作必须保证对于Tablet中数据写入成功,否则不会写入TABLET,如果写入成功后,会把提交该操作修改到Tablet对应的Redo日志中,同时该写入内容会插入到MEMTABLE中。
2.4 应用场景
2.4.1 应用场景
Bigtable从数据存储特点看,属于行式数据库存储模型,虽然Bigtable具备把列分配到不同的SSTABLE,形成不同的列簇的情况。由于Bigtable采用按照行存储模型,因此对于数据表中的一行可以实现事务性操作,实现数据单表上的事务控制,虽然Bigtable提供了批量数据的访问接口,但是还不支持跨行的事务操作。
而Bigtable采用的KV结构,可以按照Key中的行关键字和列关键字,对于海量数据进行列维度和行维度的切片管理,分别到同步到TABLET服务器上面。在一个BIGTABLE系统中,TABLET服务器的数量可以根据负载要求,做动态的调整,对于TABLET服务器数量无上限,这样就可以支持对于数据库负载的水平扩展,根据GOOGLE提供的数据,单TABLET服务器在BLOCK为64KB时,KEY-VALUE中的VALUE为1K的长度是,可以支持1200次请求,一个TABLET服务器可以处理75M数据读取,当TABLET服务器数量增加后,其读取数据的能力可以提升,当并不会严格的遵循线性关系,可以从GOOGLE在BIGTABLE中提供的测试数据看出,TABLET服务器增加和整体系统吞吐能力提升的关系,参见图2-4。
可以看出对于TABLET的扫描和在TABLET中内存中的随机读,提升效率最为明显,这是由于在TABLET服务器增加过程中,此类操作都是在内存中进行,因此服务器越多,支持吞吐量就会更大。顺序读、随机写、顺序写提升比率低于前两种操作,顺序读由于读取SSTABLE到TABLET服务器时,一个BLOCK被读取时,SSTABLE中相邻接的BOLCK会被加载到BLOCK缓存中,后续会在缓存中被读取到该BLOCK,不在需要在从SSTABLE中读取。随机写和序列写在采用了批量提交的方式,通过数据流的方式来进行处理,此种操作方式随TABLET的增加,提升效果还是比较明显。谁TABLET服务器提升效果最低的为随机读,原因是随机读取时,为了访问KEY-VALUE值中,VALUE为1K的数据时,会同步把整个SSTABLE中一个BLOCK都读取出来,当随机读取请求数量增加时,整个网络带宽会急剧上升,导致每个TABLET服务器吞吐能力下降,整个系统能够处理的随机请求数量变少。

图2-4 tablet 服务器与系统IO吞吐量关系图
2.4.2 应用场景下技术难题
从Bigtable应用场景看,BIGTABLE系统设计需要解决下面的核心技术
技术难题一系统鲁棒性
对于分布式环境,对于网络受损、内存数据损坏、时间误差,机器硬件损坏这这种常见的问题出现后,系统的容错处理能力,要求Bigtable系统具有较强的鲁棒性和容错性。
技术难题二 系统容错和负载与效率的平衡
TABLET副本数量增加会增加系统容错能力,但是会增加系统管理代价和同步成本,效率就会相应的下降;系统负载和效率增加,有限制了数据副本数量、副本数量下降会导致系统容错性减低,GOOGLE具体处理算法,这些在GOOGLE对外公布的论文中没有进行详细的描述,在开源产品HBASE遇到问题看,这些都是一些技术难点。
技术难题三 不同查询特点的应对
由于系统不同查询特点,数据特点,对于BIGTABLE中的各种关键配置参数的配置方式,比如SSTABLE中BLOCK大小的选择、缓存算法设计细节。
上面的这些技术难题相信已经被GOOGLE很好的解决,不过这些解决经验和具体技术细节GOOGLE并没有进行公开。
2.4.3 BIGTABLE后续发展
Bigtable做为GOOGLE公布的第一代分布式数据库技术,结合下层的GFS文件系统,上结合MAP-REDUCE框架完成数据的分片计算,构成了GOOGLE的分布式计算体系。而BIGTABLE目前只有在一个系统只支持一个Master服务器,同时对于多表事务性无法支持,这些都是Bigtable后续要解决的技术问题。对于不同特点数据库查询请求,不同特点存放数据,BIGTABLE的关键参数应该如何配置,是否有一种完美的配置参数,可以完全满足各种不同特点的查询场景,从目前来看,还不能做到的,还必须根据数据特点,对BIGTABLE的参数做相应定制,包括一些BIGTABLE要使用的GFS文件配置参数、网络配置参数,这些都成为使用Bigtable数据库过程中一些较为复杂问题,整个Bigtable数据库使用技术门槛仍然比较高。
--未完,后续抓紧写,争取马年前写完。