2 matplotlib.pyplot
代码来自2. Python数据可视化matplotlib.pyplot。
matplotlib.pyplot 是面向python,它不同于visdom,所以plt可以接受列表数据类型(list)进行绘图,也可以接受array类型。
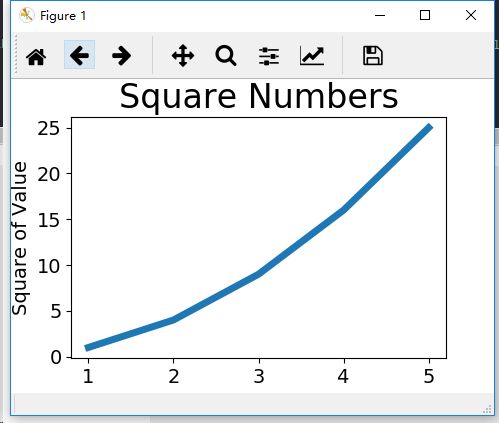
1)简单线图:
plt.plot(x,y)
import matplotlib.pyplot as plt
#图形输入值
input_values = [1,2,3,4,5]
#图形输出值,需要个数对应
squares = [1,4,9,16,25]
#plot根据列表绘制出有意义的图形,linewidth是图形线宽,可省略
plt.plot(input_values,squares,linewidth=5)
#设置图标标题
plt.title("Square Numbers",fontsize = 24)
#设置坐标轴标签
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
#设置刻度标记的大小
plt.tick_params(axis='both',labelsize = 14)
#打开matplotlib查看器,并显示绘制图形
plt.show()
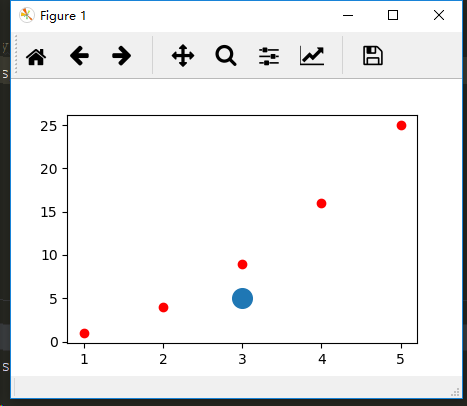
2)散点图
注意,通常在执行到plt.show时候,程序会暂停,需要关闭显示窗口之后才能执行后面的程序。
#绘制散点图(传如一对x和y坐标,在指定位置绘制一个点)
plt.scatter(input_values,squares, c = 'red')
#设置输出样式
plt.scatter(3,5,s=200)
plt.show()
#参数1指定要以什么样的文件名保存图表,保存和代码的同目录下,第二个参数表示要将多余的空白区域剪掉,要保留空白区域,可省略第二个参数
plt.savefig('squares_plot.png',bbox_inches='tight') # 注意要保存窗口图片时,一定要注释掉plt.show(),否则需要关闭窗口才能往下执行,但是手动关闭窗口之后,后面就会保存空白图片
3)显示图片(注意输入是,[h, w, c],且dtype是int,0~255之间。区别于visdom中输入[c,h,w])
a = plt.imread('tree.jpg')
plt.imshow(a)
plt.show()

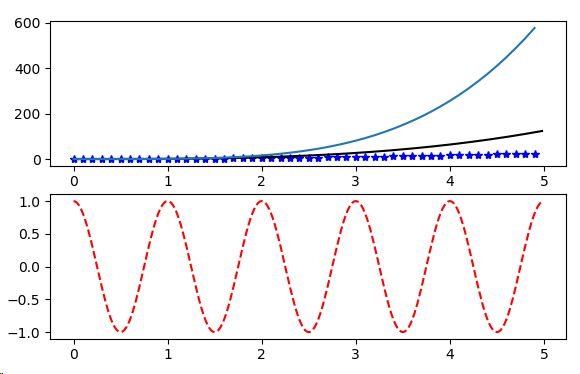
4)一个大窗口下多个小窗口显示
plt.figure(1) # 显示窗口的名称,如果不关闭这个窗口,之后所有的操作都是在这个窗口上的操作
plt.subplot(211) # 在这个窗口下开辟一个小窗,如果不开新的小窗,都是在这个小窗下的操作
plt.plot(t1, f(t1), 'bo', t2, f(t2), 'k')
plt.subplot(212) # 在 1 大窗口下开又开一个小窗,如果不开新的小窗,都是在这个小窗下的操作
plt.plot(t2, np.cos(2np.pit2), 'r--')
t1 = np.arange(0.0, 5.0, 0.1)
t2 = np.arange(0.0, 5.0, 0.02)
plt.figure(1) # 当前图片编号,确实使用 figure(1),所以只有一张图片的时候,可以不写
plt.subplot(211) # 三个数字分别为行数、列数、坐标系编号,坐标系编号 < 行数 * 列数
plt.plot(t1, t1**2, 'b*', t2, t2**3, 'k') # 也可以采用这种方式实现一个图上绘制多条线
plt.plot(t1, t1**4) # 仍然是绘制在这个窗口上
plt.subplot(212)
plt.plot(t2, np.cos(2*np.pi*t2), 'r--')
plt.show()
5)动态显示窗口
plt.pause()功能:1.显示结果,2.并持续一段时间,但是持续的这段时间,后面的代码不能执行。
【plt.show() 和plt.draw()的区别】:
【
不是很懂,查阅的资料,整体感觉plt.draw()用不大着:
plt.show(): 将显示正在处理的当前图形。可以显示图形。
会保留住窗口,只有手动关闭才能执行后面,也就是说plt.show()只有配合plt.ion()进入交互模式才能动态显示。
plt.draw(): 将重新绘制图形。这允许您以交互模式工作,并且,如果您更改了数据或格式,则允许图形本身更改。本身并不能显示图形。

这似乎表明, 在不处于交互模式的情况下,在pl .show()之前使用pl .draw()在绝大多数情况下是多余的。您可能唯一需要它的时间是在进行一些非常奇怪的修改时,这些修改不涉及使用pyplot函数。
】
plt.plot()或者plt.imshow()绘图,plt.pause()显示并保存几秒;plt.cla()清除绘制的结果; plt.show()显示最后结果。注意如果在交互模式中,plt.show()不起作用,需要关闭交互模式plt.ioff(),plt.show()才起作用 。
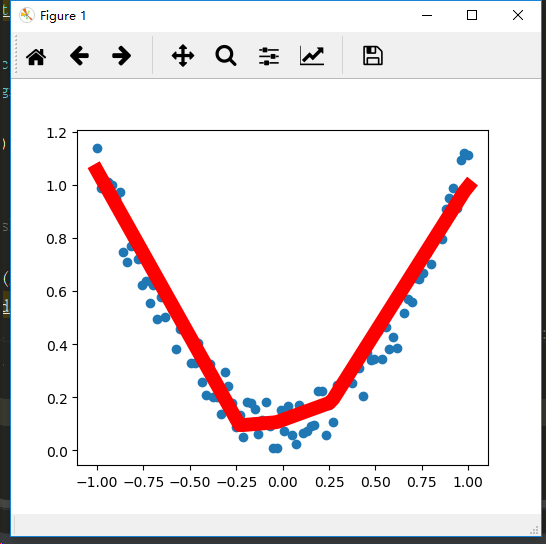
在一个窗口中动态显示例子:不断擦去以前的图,更新上新的图,最后保留住最后的图。
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1,1,100),dim = 1) # torch.unsqueeze()增加一个维度
x1 = torch.linspace(-1,1,100) # torch.linspace()产生一个一维的tensor
print(x.shape,x1.shape)
y = x.pow(2) + 0.2*torch.rand(x.size())
class Net(torch.nn.Module): # Net类要继承从torch来的一个模块,神经网络的好多功能都包含在这个模块里
def __init__(self, n_features, n_hidden, n_output): # 类似tensorflow的 tf.initialize_all_variables() 变量初始化
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1,10,1)
print(net)
optimizer = torch.optim.SGD(net.parameters(),lr = 0.5) # 每次的梯度保存在parameter中
loss_func = torch.nn.MSELoss() # mean square error 均方误差
for t in range(200):
prediction = net(x) # x在建立好的网络中前项传播得到输出
loss = loss_func(prediction,y) # 根据x的对应的真实值 计算损失
optimizer.zero_grad() # 首先梯度都是0
loss.backward() # loss 反向传播一次计算出梯度
optimizer.step() # 以学习效率0.5 优化变量的值
if t%5 == 0:
# plot and show learning process
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(), 'r-', lw=10)
plt.pause(0.1)
plt.cla()
plt.show()
先说一下matplotlib中ion()和ioff()的使用:
介绍
在使用matplotlib的过程中,发现不能像matlab一样同时开几个窗口进行比较,于是查询得知了交互模式,但是放在脚本里运行的适合却总是一闪而过,图像并不停留,遂仔细阅读和理解了一下文档,记下解决办法,问题比较简单,仅供菜鸟参考。
python可视化库matplotlib有两种显示模式:
阻塞(block)模式
交互(interactive)模式
在Python Consol命令行中,默认是交互模式。而在python脚本中,matplotlib默认是阻塞模式。
其中的区别是:
在交互模式下:
可以显示多个figure大窗口。
在阻塞模式下:
无法同时显示多个大窗口,需要先进入交互模式,最后
打开一个窗口以后必须关掉才能打开下一个新的窗口。这种情况下,默认是不能像Matlab一样同时开很多窗口进行对比的。
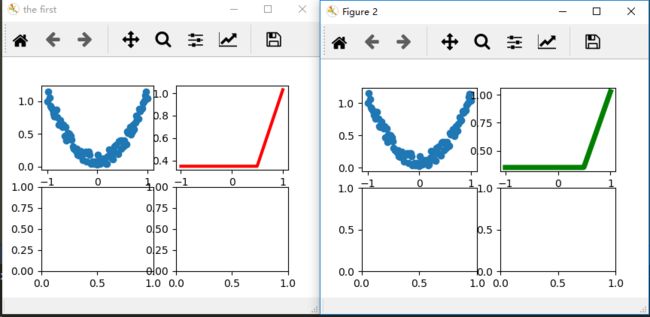
6)多个大窗口中多个小窗口动态显示
import torch
import time
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # torch.unsqueeze()增加一个维度
x1 = torch.linspace(-1, 1, 100) # torch.linspace()产生一个一维的tensor
print(x.shape, x1.shape)
y = x.pow(2) + 0.2 * torch.rand(x.size())
class Net(torch.nn.Module): # Net类要继承从torch来的一个模块,神经网络的好多功能都包含在这个模块里
def __init__(self, n_features, n_hidden, n_output): # 类似tensorflow的 tf.initialize_all_variables() 变量初始化
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1, 10, 1)
optimizer = torch.optim.SGD(net.parameters(), lr=0.5) # 每次的梯度保存在parameter中
loss_func = torch.nn.MSELoss() # mean square error 均方误差
plt.ion() # 设置绘图为动态的过程,如果不加,可能会出现部分窗口图画不出来,不知为什么
'''
fig1, axes1 = plt.subplots(nrows=2, ncols=2)
ax1_0 = axes1[0,0]
ax1_1 = axes1[0,1]
ax1_2 = axes1[1,0]
ax1_3 = axes1[1,1]
'''
# 两种方式产生多窗口
fig1 = plt.figure('the first')
ax1_0 = fig1.add_subplot(221)
ax1_1 = fig1.add_subplot(222)
ax1_2 = fig1.add_subplot(223)
ax1_3 = fig1.add_subplot(224)
fig2, axes2 = plt.subplots(nrows=2, ncols=2)
ax2_0 = axes2[0, 0]
ax2_1 = axes2[0, 1]
ax2_2 = axes2[1, 0]
ax2_3 = axes2[1, 1]
for t in range(200):
prediction = net(x) # x在建立好的网络中前项传播得到输出
loss = loss_func(prediction, y) # 根据x的对应的真实值 计算损失
optimizer.zero_grad() # 首先梯度都是0
loss.backward() # loss 反向传播一次计算出梯度
optimizer.step() # 以学习效率0.5 优化变量的值
if t % 5 == 0:
ax1_0.cla()
ax1_0.scatter(x.data.numpy(), y.data.numpy())
plt.pause(0.05)
ax1_1.cla()
ax1_1.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=3)
plt.pause(0.05)
ax2_0.cla()
ax2_0.scatter(x.data.numpy(), y.data.numpy())
plt.pause(0.05)
ax2_1.cla()
ax2_1.plot(x.data.numpy(), prediction.data.numpy(), 'g-', lw=5)
plt.pause(0.05)
plt.ioff()
plt.show()