一、Kafka简介
1.1 什么是kafka
kafka是一个分布式、高吞吐量、高扩展性的消息队列系统。kafka最初是由Linkedin公司开发的,后来在2010年贡献给了Apache基金会,成为了一个开源项目。主要应用在日志收集系统和消息系统,相信大家之前也听说过其他的消息队列中间件,比如RabbitMQ、AcitveMQ,其实kafka就是这么一个东西,也可以叫做KafkaMQ。总之,Kafka比其他消息队列要好一点,优点也比较多,稳定性和效率都比较高,大家都说好,那就是真的好。
1.2 Kafka中的相关概念
在理解Kafka的相关概念之前,我们先来看一张图,这张图基本上包括了Kafka所有的概念,对于我们理解Kafka十分有帮助。

上图中包含了2个Producer(生产者),一个Topic(主题),3个Partition(分区),3个Replica(副本),3个Broker(Kafka实例或节点),一个Consumer Group(消费者组),其中包含3个Consumer(消费者)。下面我们逐一介绍这些概念。
1.2.1 Producer(生产者)
生产者,顾名思义,就是生产东西的,也就是发送消息的,生产者每发送一个条消息必须有一个Topic(主题),也可以说是消息的类别,生产者源源不断的向kafka服务器发送消息。
1.2.2 Topic(主题)
每一个发送到Kafka的消息都有一个主题,也可叫做一个类别,类似我们传统数据库中的表名一样,比如说发送一个主题为order的消息,那么这个order下边就会有多条关于订单的消息,只不过kafka称之为主题,都是一样的道理。
1.2.3 Partition(分区)
生产者发送的消息数据Topic会被存储在分区中,这个分区的概念和ElasticSearch中分片的概念是一致的,都是想把数据分成多个块,好达到我们的负载均衡,合理的把消息分布在不同的分区上,分区是被分在不同的Broker上也就是服务器上,这样我们大量的消息就实现了负载均衡。每个Topic可以指定多个分区,但是至少指定一个分区。每个分区存储的数据都是有序的,不同分区间的数据不保证有序性。因为如果有了多个分区,消费数据的时候肯定是各个分区独立开始的,有的消费得慢,有的消费得快肯定就不能保证顺序了。那么当需要保证消息的顺序消费时,我们可以设置为一个分区,只要一个分区的时候就只能消费这个一个分区,那自然就保证有序了。
1.2.4 Replica(副本)
副本就是分区中数据的备份,是Kafka为了防止数据丢失或者服务器宕机采取的保护数据完整性的措施,一般的数据存储软件都应该会有这个功能。假如我们有3个分区,由于不同分区中存放的是部分数据,所以为了全部数据的完整性,我们就必须备份所有分区。这时候我们的一份副本就包括3个分区,每个分区中有一个副本,两份副本就包含6个分区,一个分区两份副本。Kafka做了副本之后同样的会把副本分区放到不同的服务器上,保证负载均衡。讲到这我们就可以看见,这根本就是传统数据库中的主从复制的功能,没错,Kafka会找一个分区作为主分区(leader)来控制消息的读写,其他的(副本)都是从分区(follower),这样的话读写可以通过leader来控制,然后同步到副本上去,保证的数据的完整性。如果有某些服务器宕机,我们可以通过副本恢复数据,也可以暂时用副本中的数据来使用。
PS:这个东西实际跟ElasticSearch中的副本是完全一致的,不愧是一个爹出的东西,思想啥的都是一样的。
1.2.5 Broker(实例或节点)
这个就好说了,意思就是Kafka的实例,启动一个Kafka就是一个Broker,多个Brokder构成一个Kafka集群,这就是分布式的体现,服务器多了自然吞吐率效率啥的都上来了。
1.2.6 Consumer Group(消费者组)和 Consumer(消费者)
Consume消费者来读取Kafka中的消息,可以消费任何Topic的数据,多个Consume组成一个消费者组,一般的一个消费者必须有一个组(Group)名,如果没有的话会被分一个默认的组名。
1.3 Kafka的架构与设计
一般的来说,一个Kafka集群包含一个或多个的Producer,一个或多个的Broker,一个或多个的Consumer Group,和一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,管理集群在运行过程中负责均衡、故障转移和恢复什么的。Producer使用Push(推送)的方式将消息发布到Broker,Consumer使用Pull(拉取)的方式从Broker获取消息,两者都是主动操作的。
1.3.1 Topic和Partition
Kafka最初设计初衷就是高吞吐率、速度快。所以在对Topic和Partition的设计中,把Topic分成一个或者多个分区,每个Partition在物理磁盘上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。当我们创建一个Topic是,同时可以指定分区数据,数目越多,吞吐量越大,但是消耗的资源也越多,当我们向Kafka发送消息时,会均衡的将消息分散存储在不同的分区中。在存储的过程中,每条消息都是被顺序写到磁盘上的。(顺序写磁盘的时候比随机写内存的想效率还高,这也是Kafka快的一个原因之一)。
下面是Kafka的写入原理图,可以看出下列消息都是顺序的,消费者消费的时候也是按着顺序来消费的。

对于传统的MQ而言,一般经过消费后的消息都会被删除,而Kafka却不会被删除,始终保留着所有的消息,只记录一个消费者消费消息的offset(偏移量)作为标记,可以允许消费者可以自己设置这个offset,从而可以重复消费一些消息。但不删除肯定不行,日积月累,消息势必会越来越多,占用空间也越来越大。Kafka提供了两种策略来删除消息:一是基于时间,二是基于Partition文件的大小,可以通过配置来决定用那种方式。不过现在磁盘那么廉价,空间也很大,隔个一年半载删除一次也不为过。
1.3.2 Producer
生产者发送消息时,会根据Partition的策略来决定存到那个Partition中,一般的默认的策略是Kafka提供的均衡分布的策略,即实现了我们所要的负载均衡。一般的,当我们的消息对顺序没有要求的话那就多设置几个分区,这样就能很好地负载均衡增加吞吐量了。分区的个数可以手动配置,也可以在创建Topic的时候就事先指定。发送消息的时候,需要指定消息的key值,Producer会根据这个key值和Partition的数量来决定这个消息发到哪个分区,可能里边就是一个hash算法。
1.3.3 Consumer Group 和 Consumer
我们知道传统的消息队列有两种传播消息的方式,一种是单播,类似队列的方式,一个消息只被消费一次,消费过了,其他消费者就不能消费了;另一种是多播,类似发布-订阅的模式,一个消息可以被多个消费者同时消费。Kafka通过消费者组的方式来实现这两种方式,在一个Consumer Group中,每一个Topic中的消息只能被这个组中的一个Consumer消费,所以对于设置了多分区的Topic来说,分区的个数和消费者的个数应该是一样的,一个消费者消费一个分区,这样每个消费者就成了单播形式,类似队列的消费形式。所以说,一个消费者组里边的消费者不能多于Topic的分区数,一旦多于,多出来的消费者就不能消费到消息。另外,不同的消费者组可以同时消费一个消息,这样就实现了多播,类似发布-订阅的模式。我们可以设置每个组中一个消费者的方式来实现发布-订阅的模式。当我们有多个程序都要对消息进行处理时,我们就可以把他们设置到不同的消费者组中,来实现不同的功能。
好了,以上我们已经对Kafka有了一个初步的认识,接下来就可以来使用了。
二、Kafka的安装与使用
使用Kafka需要先安装jdk,1.7以上的版本,配置好环境变量,这一步就不啰嗦了!!
2.1 下载Kafka
下载地址:http://kafka.apache.org/downloads,找到下边的Binary Downloads就行了,版本随意选择,不过最好选择比较旧一点了,以防新的版本有新的改动啥的,导致我们踩坑,我选了下边这个版本:
下载之后直接解压就行了,压缩包格式是在linux上用的,不过一般的我们学习一个东西都可以先从windows上开始, 操作起来比较简单,由于这种高级东西运行起来都是命令行,所以对于linux和windows就没啥区别的了,到linux也是命令直接复制粘贴就行了。

2.2 启动Kakfa
2.2.1 启动Zookeeper
因为Kafka依赖Zookeeper,所以要先启动它,如下图,定位到Kafka的目录,我的是 F:\Dev\kafka_2.11-2.1.0。

在地址栏中输出cmd,然后敲回车,瞬间打开一个命令行,然后输入:.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties,注意. 代表当前目录,使用这个bat启动Zookeeper并且使用后边的配置。
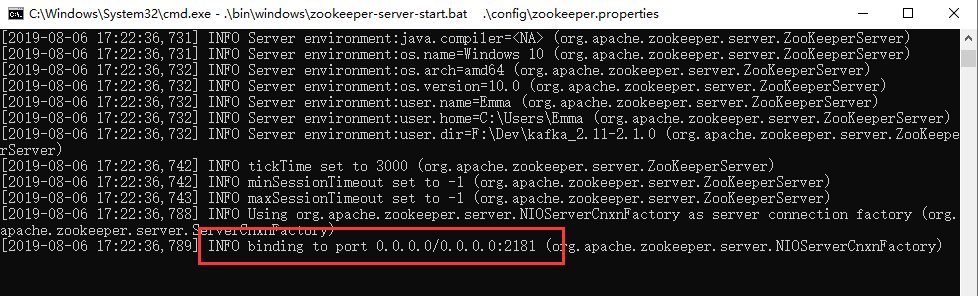
发现上边那句话,并且没报错什么的,表示Zookeeper启动成功。
2.2.2 启动Kafka
同样,在地址栏中输出cmd,瞬间启动一个命令行,然后输入:.\bin\windows\kafka-server-start.bat .\config\server.properties

发现上边那句话,并且没报错什么的,表示Kafka启动成功。
2.2.3 创建Topic
同样,进入到F:\Dev\kafka_2.11-2.1.0\bin\windows,在地址栏中输出cmd,瞬间启动一个命令行,然后输入:kafka-topics.bat –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test,创建一个主题test。

发现上边那句话,并且没报错什么的,表示主题Topic创建成功。
2.2.4 创建Producer
同样,进入到F:\Dev\kafka_2.11-2.1.0\bin\windows,在地址栏中输出cmd,瞬间启动一个命令行,然后输入:kafka-console-producer.bat –broker-list localhost:9092 –topic test,创建一个Producer,准备生产主题为test的消息。

出现一个光标,表示等待生产消息,一会我们可以输入消息。
2.2.5 创建Consumer
同样,进入到F:\Dev\kafka_2.11-2.1.0\bin\windows,在地址栏中输出cmd,瞬间启动一个命令行,然后输入:kafka-console-consumer.bat –bootstrap-server localhost:9092 –topic test –from-beginning,创建一个Consumer,准备消费主题为test的消息。

也会出现一个光标,等待显示消息。
2.2.6 测试生产和消费
在Producer控制台输入消息,会在Consumer控制台看见消息:

以上就是Kafka的搭建和使用,也不是那么的复杂。我们在开发中肯定使用的是各类语言封装过的驱动,java、.net的都差不多,先理解了原理,用起来就方便多了。
三、Kafka客户端驱动的使用
下面我们使用.net的Kafka驱动Confluent.Kafka,来看看是如果使用Kafka的,其他语言的小伙伴可以自行搜索相关的驱动。
3.1 创建应用
如下图,创建一个解决方案,添加两个控制台项目,一个作为生产者,一个作为消费者。

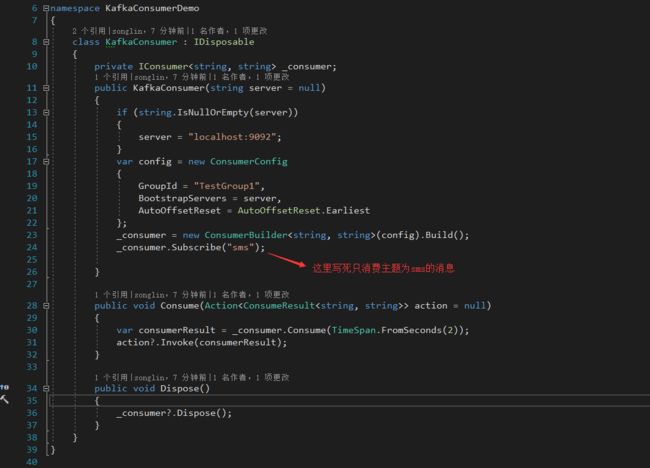
3.2 添加Producer和Consumer类
添加Producer类和Consumer类,配置中的server写死为默认的Kafka服务器的地址,如下图所示:

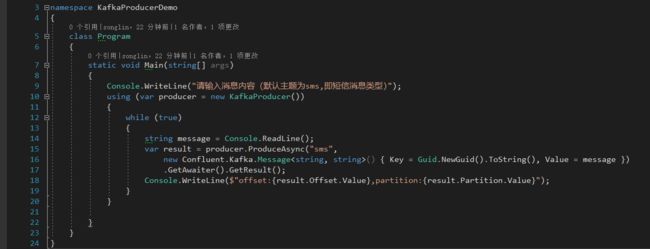
3.3 添加Program.cs中的启动代码
添加Producer的代码:
添加Consumer的代码:
3.4 启动Kafka服务
按照步骤2.2.1和2.2.2 启动Zookeeper和Kafka,消费者和生产者就不用启动了,我们用控制台代替。
3.4 启动实例
分别启动Producer实例和Consumer实例,在Producer控制台下输入消息,可以发现Consumer控制台下显示消息,和前边我们所做的是一致的。

好了,以上就是Kafka的初步使用,有了这些基础,我们就可以搭建一个消息队列开始处理消息了。
参考文章:https://www.cnblogs.com/xxinwen/p/10683416.html,https://www.cnblogs.com/qingyunzong/p/9004593.html
代码托管到github,地址:https://github.com/EmmaCCC/KafkaStudy.git
四、总结
到此为止,我们已经基本掌握了Kafka的使用,至于详细的配置啥的等到我们用的时候再去研究,假如没机会用到,那就不用去学了,不过用到用不到学了总是有用的,因为到时候简历上又可以写上一项技能了:熟练使用Kafka搭建高并发分布式消息队列系统,承载千万级别的消息并发,之后的怎么喷就看你自己了。
原文地址