在前面的博客当我们讨论性能测试时,我们在说什么?中有聊过性能测试的目的和本质。性能测试过程中,监控分析和调优是最核心也是占比最大的一部分。
性能分析的目的是找出系统性能存在的瓶颈与风险,性能调优就是尽可能用更少的资源提供更好的服务。而其关键点,就是生成负载、监控相关指标。
性能测试前期的需求调研、开始前的准备工作,都是为了保证后期的监控分析调优能顺利且高效进行。那么,一个完整的监控体系,需要包含哪些?
这篇博客,聊聊我在工作实践中如何监控,以及比较完善的监控体系,都包含哪些指标和工具。。。
在讲述监控分级体系之前,有必要了解下面的概念:
APM(Application Performance Management):对应用程序性能和可用性的监控管理。
狭义上的APM单指应用程序的监控,如应用的各接口性能和错误监控,分布式调用链路跟踪,以及其他各类用于诊断(内存,线程等)的监控信息等。
广义上的APM, 除了应用层的监控以外,还包括手机App端监控,页面端监控,容器、服务器监控,以及其他平台组件如中间件容器,数据库等层面的监控。
APM监控的目的:主要包含如下两方面:
1、事前:及时预警发现故障;
2、事后:提供详实的数据用于追查定位问题。
监控分级体系

一、中间件监控
中间件监控,主要包含如下两个方面:
1、缓存
IOPS:一般指用于计算机存储设备性能测试的计量方式,可以视为每秒的读写次数。
命中率:缓存的命中率是一个很重要的性能监控指标,它指的是应用服务从缓存读取数据的百分比,命中率越高,服务的延时越低,性能越好。
连接数:指的是请求缓存所创建的http连接数,以Redis来说,最大连接数为10000。监控连接数的目的在于防止缓存负载过高导致雪崩。
2、消息队列
Topic:在消息队列中间件(kafka、MQ)中,topic指的是一种消息类型。采用发布订阅模式,由消费者来订阅该类消息并处理。
QPS:即每秒请求数,在性能测试中,QPS主要用来衡量应用服务单位时间内承受的负载请求量。
消息总量:消息队列通过异步处理消息的模式,来达到削峰填谷,提升性能的目的。但其本身的消息持有量是有限的。因此监控消息总量防止消息积压,也是监控中必不可少的一环。
二、压测数据监控
1、指标
TPS:每秒事务数。在性能测试中,主要用来衡量服务端单位时间内对请求的处理能力。
ART:平均响应时间,用来衡量服务端在一个时间段内,处理请求的平均耗时,这也是衡量系统性能的关键指标。
99RT:意指99%的请求响应时间在某个范围内。由于很多因素的影响,请求耗时的分布是不均的,因此99%RT可以从另一个维度衡量系统性能的可用性。
Error%:错误率。当然对应的有请求成功率,业务成功率,通过这些指标,可以直观的衡量系统各维度的性能表现。
2、工具
jmeter:java开源的性能测试工具,其本身提供了较为丰富的监控组件,支持二次开发,是现在业内使用比较广泛的负载工具。
loadrunner:商业收费的性能测试工具。
三、链路监控
链路监控的重要性不言而喻,搭建基于时间序列数据库的监控报警系统,满足业务监控需求,可以更好的辅助大家定位系统问题,甚至自动(提早)发现问题。
1、指标
JVM
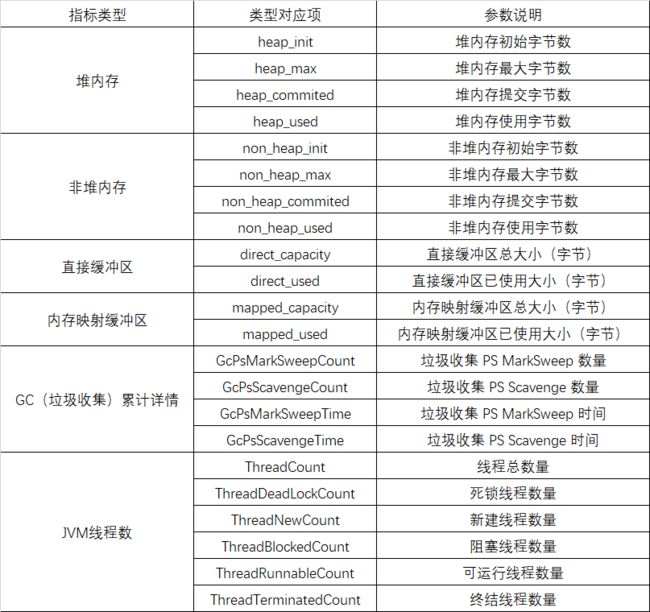
2、工具
CAT
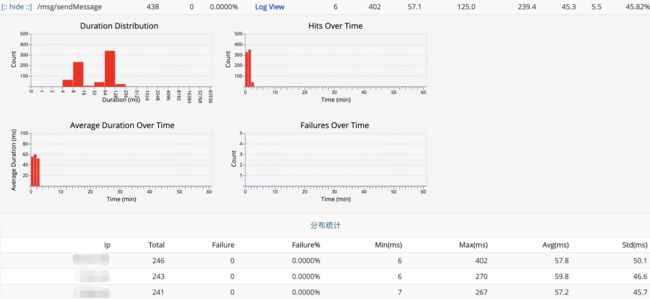
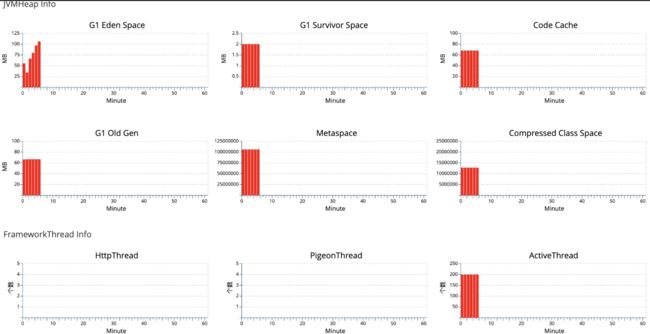
其他类似的工具还有:Zipkin、pinpoint、skywalking。
四、DB监控
数据库的监控,在性能测试过程中,主要监控如下指标:
CPU:CPU资源耗用,是很重要的一项指标,如果DB挂了,那么整体的所有服务,也就无法为用户提供服务。
慢sql:即当前正在执行的耗时比较长的SQL语句,这些是影响DB性能的重要因素。
最大连接数:即DB可支持的同时保持请求连接的数量。
五、日志监控
日志的重要性不言而喻,基本上绝大多数的监控系统都是基于日志来进行聚合展示,排查问题的。最常见的日志监控系统,就是所谓的ELK。
现在公有云服务基本都提供日志服务,比如阿里云的logstore。
六、安全监控
一般性能测试过程中,涉及安全的部分比较少,但数据信息的安全是很重要的。对于中小型企业而言,安全监控,一般都是利用专业的三方厂商工具来进行。
PS:一般安全部门为了更好的监控,会在防火墙和网关之间搭建一层WAF来更好的保障安全,但WAF层会有一定的延时,性能测试,有时候需要关注这一层。
七、API监控
性能测试过程中,无论是前期的流量模型评估还是压测过程中的实时监控,对于API层的监控,都是很重要的。且很多时候,压测报错,都是API的各种问题。
可用性:API能否像它所承诺的提供正常的服务(处理能力)。
正确性:API对用户请求的正确处理表现。
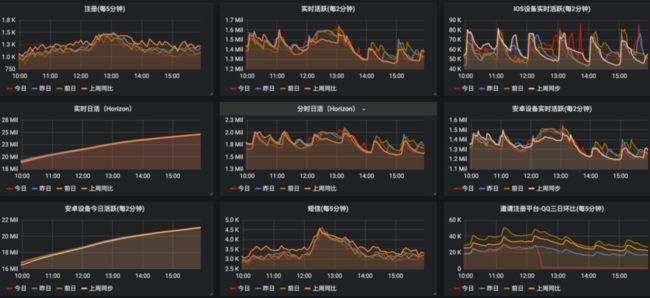
八、业务监控
业务监控的重要性不言而喻,无论是对于数据分析还是服务可用性评级,都是很重要的。以电商系统而言,常见的监控指标有:PV、DAU、每分钟订单量/支付量。
九、客户端监控
这里为什么要提到客户端监控,因为用户端可用才是真正的可用!!!(所谓的可用性,一定是业务/用户可用)
客户端监控主要关注这几项指标:
页面打开速度(测速)
页面稳定性(JS Erro)
外部服务调用成功率(API)
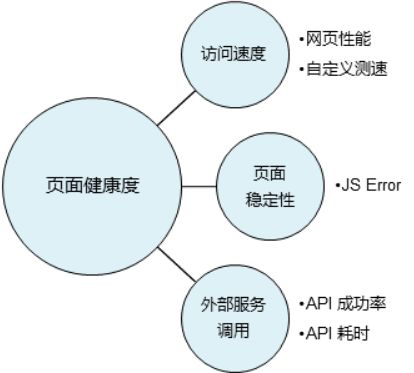
可以通过监控大盘的方式,来多维度的展示相关的监控指标,比如:

十、服务资源监控
服务资源监控,作为性能测试和运维体系中最基本的监控,目的是对系统不间断实时监控,实时反馈系统当前状态,保证服务可用性安全性,保证业务持续稳定运行。
监控主要关注如下指标:
CPU:Total%、Sys%、User%、每个CPU%;
磁盘:读写吞吐率(MBps)、读写次数(次/s);
内存:Menery%、free-memory、SWAP%;
网络:网卡出/入带宽(kbps)、网卡出/入包量(个/s)、TCP连接状态;
进程:进程端口、Run queue;
Point:上下文切换、运行队列;

本篇博客的主要目的是建立一个较为完善的监控知识体系,文中的示意图都是基于grafana搭建的,内容仅供参考。。。