AWS机器学习初探(1):Comprehend - 自然语言处理服务
1. Comprehend 服务简介
1.1 功能
Amazon Comprehend 服务利用自然语言处理(NLP)来分析文本。其使用非常简单。
- 输入:任意 UTF-8 格式的文本
- 输出:Comprehend 输出一组实体(Entity)、若干关键词(Key phrase)、哪种语言(Language)、什么情绪(Sentiment,包括 positive,negative,neutual,mixed等几种)和针对每个单词的语法分析(Syntax)
- 形式:支持同步的单文档返回,异步的多文档处理和批处理
- 支持的语言:语言判断API支持上百种语言,其余API 只支持英语和西班牙语。
- 是否需要预处理:不需要。AWS 自己会持续训练处理模型,来不断提高处理精度,这对用户来说是透明的。
典型的异步批处理过程:
- 将文档保存在 AWS S3 中
- 开启一个或者多个 Comprehend job 来处理这些文档
- 监控这些 job 的状态
- 从另一个 S3 bucket 中获取分析结果
1.2 示例

该图中,左侧为一段作为输入的文字,右侧为Comprehend API 的输出,分别是实体、关键词、情绪和语言。
在界面上做测试的例子:
在 Comprehend 界面上输入美国总统川普最新的一条推特消息,它认为其是负面的:

利用CLI 做测试的例子:
aws comprehend detect-dominant-language --region us-east-1 --text "hello world" { "Languages": [ { "LanguageCode": "en", "Score": 0.9750663042068481 } ] }
2. 一个示例应用场景
2.1 应用场景说明
部署架构图:

架构说明:
- 在某个 AWS 区域,利用该区域中的 Comprehend API
- 有一个该区域中的 VPC,它有两个 Public Subnet,其中一个中有一个EC2 实例,安装了 phpmyadmin,用于连接和管理私有子网中的 Aurora 实例
- 有一个私有子网,其中创建了一个 Aurora 实例,它只能在 VPC 范围内被访问
- VPC 中有一个 Lambda 函数。因为该函数需要直接访问 Aurora 实例,因此它必须在 VPC 之中。
- 因为 Lambda 函数需要访问 Comprehen API ,而 AWS 目前未提供内部访问该 API 的端点,因此需要有一个 NAT 网关。 Lambda 函数通过该网关访问 Comprehend API。
操作过程:
- 用户通过 phpmyadmin 来使用 Aurora 数据库。数据库中有一个名为 ReviewInfo 的表,每行代表一个文本信息,三列分别保存了文本信息的 ReviewID,message,sentiment,分别是记录的ID,消息内容和情绪。
- 每当用户插入一条消息(图中的1和2),Lambda 函数会自动被触发(图中的3),它调用 Comprehend API(图中的4),获取该信息的 sentiment,然后写回 Aurora 中的该条记录的 sentiment 字段(图中的5)。
- 用户从 phpmyadmin 中查询该条记录的 sentiment。
2.2 实现
(1)按照部署图,创建所需的各个AWS 服务实例,包括EC2 实例、NAT 实例、VPC、安装phpmyadmin 等。过程省略。在VPC 中创建一个 Aurora 实例,配置 phpmyadmin 指向该实例。在 VPC 中创建一个 python 2.7 Lambda 函数。函数内容如下:
import pymysql
import json
import boto3
import os
def lambda_handler(event, context):
comprehend = boto3.client(service_name='comprehend') jsonresponse= json.dumps(comprehend.detect_sentiment(Text=event['ReviewText'], LanguageCode='en'), sort_keys=True, indent=4) json_object = json.loads(jsonresponse) sentiment=json_object["Sentiment"] db = pymysql.connect(host=os.environ['host'],user=os.environ['user'],passwd=os.environ['password'],db=os.environ['db'], autocommit=True) add_order = ("UPDATE ReviewInfo SET Sentiment=%s WHERE ReviewId=%s;") db.cursor().execute(add_order, (sentiment,event['ReviewId'])) db.commit() db.close()
该函数非常简单。简单说明如下:
- 通过环境变量传入 host,user,password,db 等数据库连接信息。
- 首选通过 boto3 库创建一个 comprehend 客户端
- 从传入的 event 中获取消息内容
- 调用 comprehend 服务的 detect_sentiment 函数,获取该消息的sentiment
- 通过 pymysql 库链接到数据库
- 更新该消息对应的记录的 Sentiment 列
(2)通过 phpmyadmin 在 Aurora 实例中创建一个数据库 comprehend_demo。
(3)在 phpmyadmin 中执行下面的 SQL 语句在该数据库中创建一个数据表 ReviewInfo。它有三个字段。
CREATE TABLE comprehend_demo.ReviewInfo( ReviewId NUMERIC PRIMARY KEY , ReviewText TEXT NOT NULL , sentiment VARCHAR( 30 ) NOT NULL)
(4)在 phpmyadmin 中执行下面的 SQL 语句在数据库comprehend_demo中创建一个名为Aurora_To_Lambda的存储过程。注意需将其中的 COMPREHEND_LAMBDA_ARN 替换为步骤(1)中创建的Lambda 函数的 ARN。该存储过程会调用由 arn 指定的 Lambda 函数,并且传入 ReviewID 和 ReviewText 参数值。
DROP PROCEDURE IF EXISTS comprehend_demo.Aurora_To_Lambda; DELIMITER ;; CREATE PROCEDURE comprehend_demo.Aurora_To_Lambda (IN ReviewId NUMERIC, IN ReviewText TEXT) LANGUAGE SQL BEGIN CALL mysql.lambda_async('<COMPREHEND_LAMBDA_ARN>', CONCAT('{ "ReviewId" : "', ReviewId, '", "ReviewText" : "', ReviewText,'"}') ); END;; DELIMITER ;
结果:

(5)在 phpmyadmin 中执行下面的 SQL 语句在该数据库中创建一个触发器。每当 ReviewInfo 表中有新行被插入时,该触发器会被调用。它会获取该行的 ReviewID 和 ReviewText 字段,然后调用第(4)步中创建的触发器,触发器会调用 Lambda 函数。
CREATE TRIGGER `TR_Lambda` AFTER INSERT ON `ReviewInfo` FOR EACH ROW BEGIN SELECT NEW.ReviewId , NEW.ReviewText INTO @ReviewId , @ReviewText; CALL comprehend_demo.Aurora_To_Lambda(@ReviewId , @ReviewText); END
(6)因为Aurora 需要调用 Lambda 函数,因此需要配置 Aurora 的 IAM Role,使之具有调用 Lambda 函数的权限。
首先在 IAM 界面上,创建一个 IAM Policy,它包含 InvokeFunction 权限。

再创建一个 IAM Role,包含该 policy。

在 Aurora 界面上,创建一个新的 DB Cluster parameter group:
![]()
修改其 aws_default_lambda_role 为前面创建的 IAM role 的 arn,比如:
![]()
将 group2 设置为 Aurora 实例的group。此时需要重启实例,使得修改得以生效。
然后在下面界面中设置 Aurora 的 IAM role 为上述 role:

(7)做个简单测试,插入一条数据,如果出现下面的错误,则意味着 Aurora 成功地调用了 Lambda 函数,但是 Lambda 函数无法连接到 Comprhend 服务。此时需要检查从 Lambda 函数经过 NAT 网关访问 Comprehend API 的路径,主要是 VPC 的路由表。

(8)在网络路径确认无误后,如果出现下面的错误,则表示 Lambda 函数还无权调用 Comprehend API。
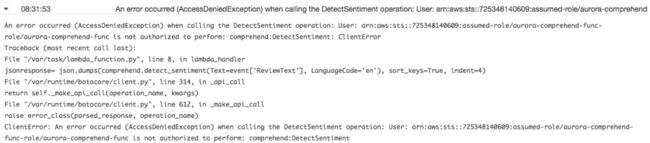
(9)配置 Lambda 函数调用 Comprehend API 的权限。
首先需要在 IAM 创建一条 policy,它有 Comprhend API 的完全权限。当然,可以只授予 sentiment API 权限。
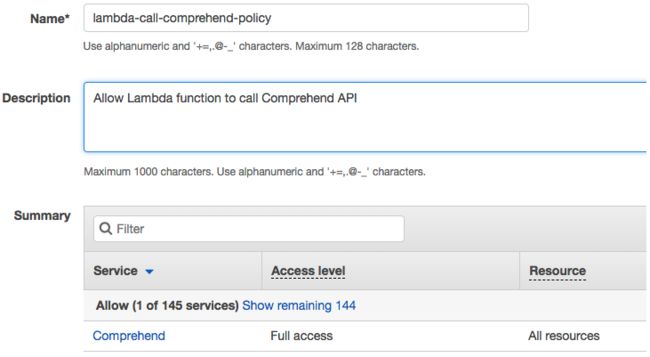
然后创建一个 IAM role,关联该 policy。再将该 role 配置给 Lambda 函数,作为其 Execution Role。

(11)到现在为止,整个路径才算全部打通了。当你在 phpmyadmin 中通过 SQL 语句向 ReveiwInfo 表中插入一行时,Lambda 函数会自动在改行内更新 sentiment 字段。

参考文档:
- https://aws.amazon.com/cn/blogs/machine-learning/building-text-analytics-solutions-with-amazon-comprehend-and-amazon-relational-database-service/
欢迎大家关注我的个人公众号:
