20180521晚 天气不错 先慢慢写,随时会补全
20180608下午,工作机在运行蚂蚁比赛的grid search寻找最优参数的算法,空出来几个小时可以用来完善这个笔记。今天主要补全LFM算法,参考了harry huang的博客使用LFM(Latent factor model)隐语义模型进行Top-N推荐,里面的语句通俗易懂,推荐。
今天继续学习和理解《推荐系统实践》的第二章内容。这章介绍了主流的基于用户行为数据的协同过滤算法,主要可以分为根据统计学得到的算法,比如基于用户的协同过滤算法,基于物品的协同过滤算法;以及具有良好的学习理论基础的隐语义LFM模型和基于图模型的算法。这些算法都需要使用用户的数据。
利用用户行为数据的前提是:认为用户的行为不是随机的,二是蕴含很多的模式,这些模式并不能直接得到,需要我们去挖掘这些规律,从而为产品的设计提供指导,提高用户体验。对于上述这个最好的例子就是啤酒喝尿布的例子,通过研究用户的购买规律,发现购买尿布的人有很大的概率购买啤酒。这两个风马牛不相及商品就这么联系在一起了,通过将两者放在同一个购物架上,可以明显提高两者的销售量。
用户的数据介绍
在介绍这些算法之前,文章先对用户的数据进行了介绍。在互联网推荐中,常见的行为可以分为显示行为和隐性行为,我们当然希望可以获得尽可能多的显性行为,毕竟打分之类的用户行为数据多么直接了当,但是遗憾的是,大部分的行为都是隐性的行为。上下文也是用户数据的重点,比如当前的时间和地点,之前浏览的信息等等,但是这类信息也不容易掌控。
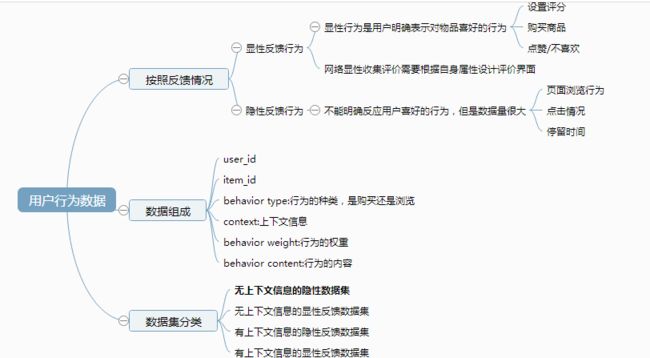
通过对用户行为的分析,我们发现
1. 互联网上很多的数据都符合长尾分布,1)热门物品占据了用户大部分的注意力,2)热门用户占用了大部分的流量。
2. 越是活跃的用户越是倾向于浏览冷门物品。
评价指标

下面依次介绍这些算法,首先是基于邻域的算法
一、基于邻域的方法
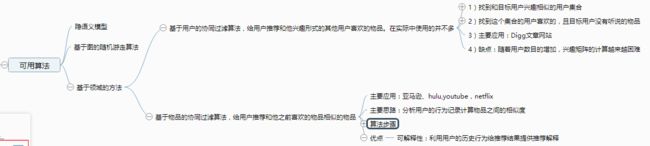
1. 基于用户的协同过滤算法的主要思想

下面是UserCF算法的具体操作,之所以先建立每个物品对应的用户的倒排表,而不是直接计算两个用户之间的相似度,是因为在大数据的环境下,很多用户之间并没有对相同的物品进行过行为,大部分的N[u]&&N[v]=0,时间复杂度是O(U*U),浪费时间。

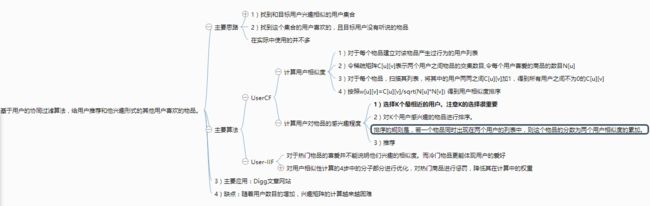
2.基于物品的协同过滤算法
并不会去根据内容计算物品之间的相似度,主要是通过分析用户的行为来计算物品之间的相似度。默认的假设是,物品A和物品B具有很大的相似度是因为喜欢物品B的人也喜欢物品A。
两个物品的相似度高是因为他们被很多用户同时喜爱。还有一个默认假设是每个用户只会关注有限个领域,因此如果两个物品同时属于很多用户的兴趣列表,那么表明这两个物品很可能属于同一个领域(不需要人工进行领域划分,厉害)
ItemCF的思路和UserCF类似,先建立用户-物品的倒排表,然后将倒排表中的两两物品的共现矩阵+1,然后利用相似度计算公式得到物品之间的相似度。最后按照推荐公式将最相似的物品推荐给用户。
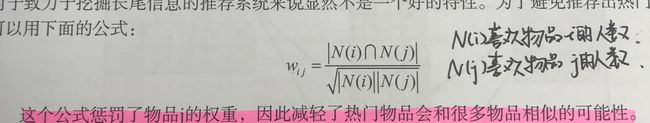


ItemCF算法的优势是提供推荐的解释,即利用用户历史上喜欢的物品为现在的推荐结果进行解释。
K值是在步骤2的第一小节中,用于选择与物品j最相似的K个物品的。K值的选择对推荐算法的结果很重要,会影响精度(准确率、召回率)、流行度和覆盖率。K值和精度(准确率、召回率)、流行度的关系不是线性关系,因此需要不停尝试得到最佳K值;K值和覆盖率成反比。
和UserCF-IIF类似的,活跃用户也需要被惩罚。因为在ItemCF中,每个用户的兴趣列表都为物品的相似度做出贡献,但是活跃用户的贡献应该被减小(Item-IUF算法):

但是总是存在一些异常活跃的用户,对于这样的用户,在计算相似度的时候直接将其删除即可。
UserCF和ItemCF的比较和优缺点介绍
二、隐语义模型
相比较UserCF和ItemCF,近年来,隐语义模型最早在文本挖掘领域崭露头角,用于找到文本的隐含语义分类。核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。对于某个用户,首先得到他的隐含兴趣分类,然后从兴趣分类中挑选他可能喜欢的物品。
对于用户来说,我们可能有不同的兴趣,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawei Han等人的著作。那我们在推荐的时候,肯定是向用户推荐他感兴趣的类别下的图书。那么前提是我们要对所有item(图书)进行分类。分类标准这个东西是因人而异的,每个用户的想法都不一样。拿B用户来说,他喜欢的三个类别其实都可以算作是计算机方面的书籍,也就是说B的分类粒度要比A小;拿离散数学来讲,他既可以算作数学,也可当做计算机方面的类别,也就是说有些item不能简单的将其划归到确定的单一类别;拿C用户来说,他倾向的是书的作者,只看某几个特定作者的书,那么跟A,B相比它的分类角度就完全不同了。显然我们不能靠由单个人(编辑)或team的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。
因此需要解决的问题:
1. 如何给物品进行分类
2. 如何确定用户对哪些物品感兴趣已经感兴趣的程度
3. 如何确定用户所有类别的兴趣程度
4.对于给定的类,如何选择应该推荐的物品,如何确定这些物品在这个类中的权重。
解决方案
隐含语义分析技术(LVA)解决第一、二、三个问题。核心思想是采用基于用户行为的自动聚类。发展到今天,这个技术有很多注明的模型和方法,比如pLSA,LDA,隐含类型模型,隐含主题模型,矩阵分解。这些技术和方法都可以用在个性化推荐系统。这里介绍LFM

K值是我们手工指定的隐类,通过最优化的算法(梯度下降法),最终对于有U个用户,K个隐类。每个用户的puk大小含义这个用户对隐类标签为k的类别的喜爱程度。qik表示物品i和隐类k的相关程度。表示了P是一个U*K矩阵,Q是一个K*I矩阵。

如果我们可以通过数学手段得到这样的两个矩阵,那么一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。
LFM可以把我们从人工分类、分类粒度(隐含类越多则越细致)中解放出来,同时一个人不再只对有限个类别感兴趣,而是可以得到对所有类别的兴趣;一个物品也不再是单纯属于一个类别,而是可以属于多个类别,并且在每个类别中的权重不同。
书上给出了基于均方损失函数的参数优化算法:
在计算的过程中,有下面的这些参数需要注意:

这个学习算法的优点是不需要手工分类,自动实现基于用户行为统计的聚类。缺点是当数据集稀疏,LFM性能会明显下降,甚至不如ItemCF和UserCF;实时性差,每次训练都需要扫描所有用户的行为数据,才能计算出用户的隐类喜爱度pu和隐类物品相关度qi.
LFM在雅虎首页个性化推荐的方案,改进了LFM实时性能差的问题。具体可以参考论文latent Factor Models for Web Recommender Systems.
最后以LFM和基于邻域的方法的比较作为收尾结束了这一小节。

基于图的模型
用户行为可以用图表示,如果用户到物品有关系,那么用户节点和对应的物品节点之间就有连线。二分图模型是指图的一侧都是用户节点,另一侧是物品节点,中间的连线是用户对物品的行为。
给二分图上的用户推荐,本质上是探索用户和那些没有和用户直接相连的点之间的相关性。相关性越高的物品在推荐列表中的权重就越高。如何判断图中节点的相关性呢,主要看三点1.两个节点之间有很多路径相连;2.连接两个节点的路径短;3.连接节点的路径不会经过出度比较大的顶点。
文章简单介绍了一个随机游走的图模型算法。