一.索引提交
当一个文档被添加到Solr中,但没有提交给索引之前,这个文档是无法被搜索的。换句话说,从查询的角度看,文档直到提交之后才是可见的。Solr有两种类型的提交:软提交和正常提交【也称硬提交】。
1.正常提交
Solr正常提交是将所有未提交的文档写入磁盘,并刷新一个内部搜索器组件,让新提交的文档能够被搜索。搜索器实际上可以看作索引中所有已提交文档的只读视图。可以这样说,硬提交是花销很大的操作,由于硬提交需要开启一个新搜索器,所以会影响到查询性能。
当正常提交成功后,新提交的文档被安全保存在持久存储器上不会因为正常的维护操作或服务器崩溃重启而丢失。出于高可用性考虑,如果磁盘发生故障,就需要一套故障转移方案,这一点在以后接着讨论。
2.软提交
软提交支持近实时搜索【Near Real-Time NRT】。软提交作为近乎实时可被搜索到的一种机制,跳过了硬提交的高消耗,例如,刷新到持久存储器就是花销较大的操作。软提交相对而言花销较低,可以每一秒都执行一次软提交,使得新近被索引的文档在添加到Solr之后很快被搜索到。但要记住,在某一时刻仍然需要执行硬提交操作,以确保文档最终被写入到持久化存储器中。
综上所述:
》硬提交让文档可被搜索,由于需要将其写入到持久化存储器中,所以花销较大
》软提交也可以让文档被搜索,不需要将其写入到持久化存储中
3.自动提交
不管是正常提交还是软提交,都可以采用以下三种策略中的一种来自动提交文档:
》在指定时间内提交文档
》一旦达到用户指定的未提交文档数阈值,就提交那么未提交的文档
》每隔特定时间间隔提交所有文档
4.配置
Solr硬提交与软提交的自动提交需要在solrconfig.xml中进行配置。
1 22 <autoCommit> 23 <maxTime>${solr.autoCommit.maxTime:15000}maxTime> 24 <openSearcher>falseopenSearcher> 25 autoCommit>
执行自动提交时通常会打开一个新搜索器。在默认情况下【未开启】,某文件自动提交,该文件将被写入到磁盘,但在搜索结果中不可见。Solr之所以提供这个选项,是为了减少未提交更新的事务日志大小,并避免在大规模索引过程中打开太多搜索器。
在solrconfig.xml中使用autoSoftCommit元素也可以自动配置软提交。
1 6 7 <autoSoftCommit> 8 <maxTime>${solr.autoSoftCommit.maxTime:-1}maxTime> 9 autoSoftCommit>
二.事务日志
Solr使用事务日志来确保提交到索引并已接受的更新保存在持久化存储器中。事务日志用来避免因提交过程中的异常情况而导致提交的文档丢失的情况。具体来说,事务日志主要有三个作用:
》支持近实时获取和原子更新【下面具体讲解】
》解除提交过程中写入的持久性
》通过solrcloud的分片代表支持副本的同步
在solrconfig.xml中的一个Solr内核的事务日志配置如下:
1 14 <updateLog> 15 <str name="dir">${solr.ulog.dir:}str> 16 <int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}int> 17 updateLog>
每次提交情况都会被记录到事务日志中。直到发起提交之前,事务日志会持续增长。在提交期间会处理活动的事务日志,之后将打开一个新的事务日志。一个更新执行步骤如下:
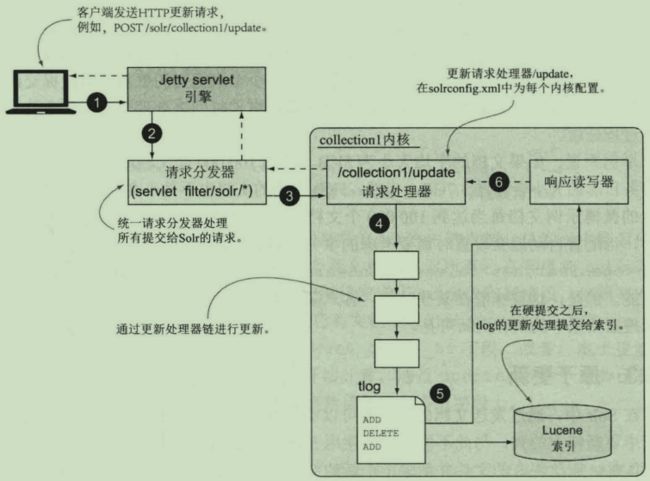
执行步骤解释如下:
1.客户端应用程序使用HTTP POST方式发送一个更新请求,可以是JSON/XML或者Solr内部二进制javabin格式
2.Jetty【Solr内部自带的WEB服务器】将此请求发送给Solr的Web应用程序
3.Solr的请求调度器通过请求路径中的collection名称确定调用的solr内核。接下来调度器定位到/update请求处理器
4.更新请求处理器对该请求进行处理,且该请求处理器将调用一个可配置的更新处理器链,在索引时为每个文档进行额外的处理
5.ADD请求写入到事务日志中
6.一旦更新请求被安全地保存到持久存储器,就会通过响应读写器回应客户端应用。这时,客户端应用得知更新请求成功执行,就可以继续执行下面的请求
注意,事务日志的关键在于权衡事务日志的长度与硬提交的执行频率。如果事务日志变得很庞大,重启就需要更长时间来处理更新,也会造成恢复过程缓慢。
三.原子更新
1.字段级别的更新
在Solr中,通过发送文档的新版本可以实现对已有文档的更新。数据库可以在一行中更新特定的列,与此不同的是,使用Solr必须更新整个文档。Solr实际执行的操作是,删除现有的文件并创建一个新的文件。不管是更改一个字段还是全部字段,都是这样执行。
从客户端的角度来看,应用程序必须发送整个文档的新版本。对于文档来自于其他来源的应用程序来说,这不是什么大问题。但是,对于那些将Solr作为主要数据存储的应用程序来说,为了更新单个字段而要重新创建全部文档,这可能会产生问题。在实践中,这需要客户先查询出整个文档,并将指定的文档整体发回给Solr。
对于已存在的文档请求所有字段,更新字段的子集,并发送新版本给Solr。这样的做法在实践中是很常见的。因此,原子更新就是为了解决这种情况,通过它可以实现仅对需要更新的字段进行更新,这让Solr更符合数据库的更新操作。Solr内部仍是删除和新建文档,但这些对客户端应用程序代码来说是通明的。
在更新操作中只需指定操作类型是更新即可:
xml配置:update="set"
java接口:
Map
map.set("name", "zhangshan")
doc.addField("set", map)
2.积极的并发控制
当两个用户同时对同一个文档进行更新时,如何执行就是一个并发的问题。当然,我们可以通过一些繁琐的过程,在一个用户更新前,显式锁定文档,但这会降低处理效率。因此,需要一些方法来防止同一文档上的并发更新,也就是积极的并发控制。
为了避免冲突,Solr通过版本跟踪字段_version_来支持积极的并发控制。在schema.xml中定义版本字段:
1 4 5 <field name="_version_" type="plong" indexed="false" stored="false"/>
当添加一个新文档时,Solr会自动分配一个唯一版本号。当需要警惕并发更新时,则在更新请求中包含精确的更新版本。当Solr处理此更新时,它会比较更新请求的_version_值与文档最新版本。文档的最新版本从索引或事务日志中获得。如果版本匹配,则进行更新。否则,更新失败。要获取最新的版本号,最好的方法是使用近实时的get请求。
全部匹配策略如下:
