前言在这
最近有很强烈的产品欲望,目标很杂乱。忽然有一天,脑海里出现了一副画面,一张大大画像,美轮美奂的夕阳,夕阳下有人靠在树边,遥望远方。正看着呢,突然画里的人说话了,某年某日做了什么事什么的。
然后就有了近来的想法,把声音加载到图片里,留存下来。可是我又不想做视频。只想要图片,然后发现了隐写术。可以将一种信息隐藏在另一种介质中,同时不影响该介质的表现。正式我想要的。于是就有了这篇文章。
隐写术是什么呢?下面维基百科的解释。
隐写术是一门关于信息隐藏的技巧与科学,所谓信息隐藏指的是不让除预期的接收者之外的任何人知晓信息的传递事件或者信息的内容。
效果图



原理分析
这里讨论的图片格式是bitmap。 有两张图A和B,要把图B的信息写入到图A里,同时不影响图A的显示。两个过程,一个是把信息写入目标文件中,另一个是把信息从目标文件中提取展示。
bitmap是由无数个像素点组成的。从左到右,从上到下,是一个个的像素点。每一个像素点里包含r/g/b/alpha信息,一般是4个字节表示,每个字节有8位bit。
为求简单易懂,这里提取RGB像素的最低有效位,用于展示信息 -- 本文里是读取像素Red字段的最低位用于存储信息。如果是最低位值是1,说明信息是我们想要的;如果最低位值是0,则不是我们想要的,丢弃。
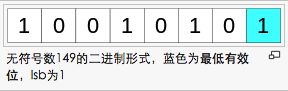
这种最低有效位思想,英文叫做LSB( Last Significant Bit )。参见维基百科
最低有效位(英语:Least Significant Bit,lsb)是指一个二进制数字中的第0位(即最低位),权值为2^0,可以用它来检测数的奇偶性.
参考文章见这里,只不过这个小哥是用JS写的,我这里用Swift实现。
像素
在iOS中,RGB像素由4个字节表示,分别是red、green、blue、alpha。如一个红色不透明的像素点,用16进制表示就是0xFF0000FF。
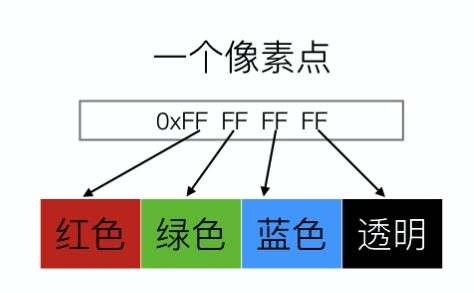
假如一个像素点的值0xFAFF00FF,那么红色字段值就是0xFA, 因为0xFA = 0b11111010, 所以最低位的值是0。
获取所有像素值
iOS中,获取bitmap图片的像素值,可以使用Quartz 2D提供的方法: CGBitmapContextGetData 。最近,发现它真的很强大。之前只是用来做动画。其实还有很多用途。
简单说明他的用法:
只有一个参数:CGContext,这是一个CoreGraphics的数据类型,用来展示和操作相关信息。你可以把他想成一个画板容器。可以画画、修改。
返回参数是一个void *的指针,当然在swift中是UnsafeMutablePointer。指针指向像素空间的第一个像素。当想要操纵所有像素的时候,就需要我们去操作指针+1,来逐个获取了。
修改某个像素值
通过修改上一步返回的指针指向的值,来达到修改像素值得目的。
示例
获取上下文CGContext
func getContext(inputImage: UIImage) -> CGContext? {
let inputCGImage = inputImage.CGImage
let colorSpace = CGColorSpaceCreateDeviceRGB()
let width = CGImageGetWidth(inputCGImage)
let height = CGImageGetHeight(inputCGImage)
//每个像素有4个字节
let bytesPerPixel = 4
//每个字节有8个bit
let bitsPerComponent = 8
let bytesPerRow = bytesPerPixel * width
let bitmapInfo = RGBA32.bitmapInfo
guard let context = CGBitmapContextCreate(nil, width, height, bitsPerComponent, bytesPerRow, colorSpace, bitmapInfo) else {
print("unable to create context")
return nil
}
CGContextDrawImage(context, CGRect(x: 0, y: 0, width: CGFloat(width),height: CGFloat(height)), inputCGImage)
return context
}
//像素值结构体
struct RGBA32: Equatable {
var color: UInt32
var red: UInt8 {
return UInt8((color >> 24) & 255)
}
var green: UInt8 {
return UInt8((color >> 16) & 255)
}
var blue: UInt8 {
return UInt8((color >> 8) & 255)
}
var alpha: UInt8 {
return UInt8((color >> 0) & 255)
}
init(red: UInt8, green: UInt8, blue: UInt8, alpha: UInt8) {
color = (UInt32(red) << 24) | (UInt32(green) << 16) | (UInt32(blue) << 8) | (UInt32(alpha) << 0)
}
static let bitmapInfo = CGImageAlphaInfo.PremultipliedLast.rawValue | CGBitmapInfo.ByteOrder32Little.rawValue
}
func ==(lhs: RGBA32, rhs: RGBA32) -> Bool {
return lhs.color == rhs.color
}
解码
//MARK: 解码 - 取red字段最低位,1 隐藏的信息, 0 无用的信息
func decodeImage(inputImage: UIImage, context: CGContext) -> UIImage {
let pixelBuffer = UnsafeMutablePointer(CGBitmapContextGetData(context))
var currentPixel = pixelBuffer
for _ in 0.. 编码
将一段信息写入到图片中。稍微有点麻烦,就是需要先获得展示信息图B的像素位置。然后,再将图A位置的像素点Red最低位置为1,其他的位置设置成0。
//MARK: 获取关键点像素坐标, 目标图像 - 白底黑字
func getKeyPositionsWithImage(inputImage: UIImage, inputContext: CGContext) -> [(Int, Int)] {
let pixelBuffer = UnsafeMutablePointer(CGBitmapContextGetData(inputContext))
var currentPixel = pixelBuffer
var result: [(Int, Int)] = [(0,0)]
for i in 0.. UIImage {
let pixelBuffer = UnsafeMutablePointer(CGBitmapContextGetData(context))
var currentPixel = pixelBuffer
var index = 0
for height in 0.. 引用:
不能说的秘密——前端也能玩的图片隐写术 :一个小哥用JS写的,简单实用。
附录
demo