1.在universal-image-loader中的内存缓存策略
我们先来了解下强引用和弱引用的概念:
强引用(StrongReference):从字面上的意思就是我对你强制引用,比如说我们经常写的new 一个对象,即使程序抛出 outOfMemory 错误也不会被垃圾回收器回收;
弱引用(WeakReference):它与软引用的区别在于,一旦垃圾回收器扫描到weakReference对象,不管内存是否够用都会被回收,然后释放内存。
OK,了解完概念后,我们看 universal-image-loader 源码中提供的缓存策略,先来看下源码中的结构图:
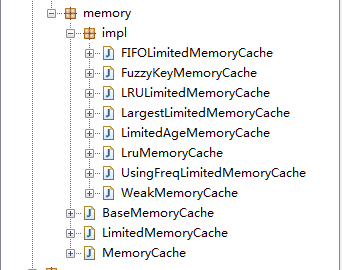
有三种内存缓存策略,分别是:
只使用的是强引用缓存
LruMemoryCache:开源框架默认的内存缓存类,缓存的是Bitmap的强引用;使用强引用和弱引用的结合,相关的类有:
FIFOLimitedMemoryCache : 先进先出的缓存策略,当超过设定值后,把最先添加进去的bitmap移出去;
LRULimitedMemoryCache : 内部使用lru算法,与LruMemoryCache不同的是,它使用的是Bitmap的弱引用;
LargestLimitedMemoryCache : 如果缓存大小超过设定值,删除最大的bitmap图片;
LimitedAgeMemoryCache : 如果缓存里的图片存在的时间超出我们设置的最大时间,就被移除出去;
UsingFreqLimitedMemoryCache : 如果缓存的图片超出设置的总量,就会删除使用频率少的Bitmap;只使用弱引用的缓存
WeakMemoryCache : 缓存bitmap的空间不受限制,但是不稳定,容易被系统回收掉。
一般我们都是使用默认的强引用缓存策略,即LruMemoryCache,当然通过ImageLoaderConfigration创建时也可以设置别的缓存策略:
通过 .memoryCache()可以设置
ImageLoaderConfiguration config = new ImageLoaderConfiguration.Builder(
context)
// 线程池内加载的数量
.threadPoolSize(4).threadPriority(Thread.NORM_PRIORITY - 2)
.memoryCache(new WeakMemoryCache())
.denyCacheImageMultipleSizesInMemory()
.discCacheFileNameGenerator(new Md5FileNameGenerator())
// 将保存的时候的URI名称用MD5 加密
.tasksProcessingOrder(QueueProcessingType.LIFO)
// .defaultDisplayImageOptions(DisplayImageOptions.createSimple())
// .writeDebugLogs() // Remove for release app
.build();
// Initialize ImageLoader with configuration.
ImageLoader.getInstance().init(config);// 全局初始化此配置
接下来我们重点看下LruMemoryCache内存缓存策略,看下它究竟是怎么实现在空间有限的情况下,保留最近使用的图片。首先贴出LruMemory的源码:
package com.nostra13.universalimageloader.cache.memory.impl;
import android.graphics.Bitmap;
import com.nostra13.universalimageloader.cache.memory.MemoryCache;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map.Entry;
import java.util.Set;
public class LruMemoryCache
implements MemoryCache
{
private final LinkedHashMap map;
private final int maxSize;
private int size;
public LruMemoryCache(int maxSize)
{
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap(0, 0.75F, true);
}
public final Bitmap get(String key)
{
if (key == null) {
throw new NullPointerException("key == null");
}
synchronized (this) {
return (Bitmap)this.map.get(key);
}
}
public final boolean put(String key, Bitmap value)
{
if ((key == null) || (value == null)) {
throw new NullPointerException("key == null || value == null");
}
synchronized (this) {
this.size += sizeOf(key, value);
Bitmap previous = (Bitmap)this.map.put(key, value);
if (previous != null) {
this.size -= sizeOf(key, previous);
}
}
trimToSize(this.maxSize);
return true;
}
private void trimToSize(int maxSize)
{
while (true)
synchronized (this) {
if ((this.size < 0) || ((this.map.isEmpty()) && (this.size != 0))) {
throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if ((this.size > maxSize) && (this.map.isEmpty()))
{
break;
}
Map.Entry toEvict = (Map.Entry)this.map.entrySet().iterator().next();
if (toEvict == null) {
break;
}
String key = (String)toEvict.getKey();
Bitmap value = (Bitmap)toEvict.getValue();
this.map.remove(key);
this.size -= sizeOf(key, value);
}
}
public final Bitmap remove(String key)
{
if (key == null) {
throw new NullPointerException("key == null");
}
synchronized (this) {
Bitmap previous = (Bitmap)this.map.remove(key);
if (previous != null) {
this.size -= sizeOf(key, previous);
}
return previous;
}
}
public Collection keys()
{
synchronized (this) {
return new HashSet(this.map.keySet());
}
}
public void clear()
{
trimToSize(-1);
}
private int sizeOf(String key, Bitmap value)
{
return value.getRowBytes() * value.getHeight();
}
public final synchronized String toString()
{
return String.format("LruCache[maxSize=%d]", new Object[] { Integer.valueOf(this.maxSize) });
}
}
我们只看重点,首先我们看它的get方法:
public final Bitmap get(String key)
{
if (key == null) {
throw new NullPointerException("key == null");
}
synchronized (this) {
return (Bitmap)this.map.get(key);
}
}
通过key取Bitmap,乍一看挺简单的哈,也没有做很复杂的判断,我们看到它是从一个map里取entry,然后我们查看这个map的get方法:
/**
* Returns the value of the mapping with the specified key.
*
* @param key
* the key.
* @return the value of the mapping with the specified key, or {@code null}
* if no mapping for the specified key is found.
*/
@Override public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
}
return null;
}
这个方法除了返回key对应的value外,我们注意到一个accessOrder变量控制的变量,里面有一个makeTail方法,我们进去看看这个makeTail方法:
/**
* Relinks the given entry to the tail of the list. Under access ordering,
* this method is invoked whenever the value of a pre-existing entry is
* read by Map.get or modified by Map.put.
*/
private void makeTail(LinkedEntry e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}
Relinks the given entry to the tail of the list 就是说会对当前key对应的entry的顺序移动到集合的最后,但前提是这个accessOrder必须是true,我们看下这个变量在哪里赋值的:
/**
* Constructs a new {@code LinkedHashMap} instance with the specified
* capacity, load factor and a flag specifying the ordering behavior.
*
* @param initialCapacity
* the initial capacity of this hash map.
* @param loadFactor
* the initial load factor.
* @param accessOrder
* {@code true} if the ordering should be done based on the last
* access (from least-recently accessed to most-recently
* accessed), and {@code false} if the ordering should be the
* order in which the entries were inserted.
* @throws IllegalArgumentException
* when the capacity is less than zero or the load factor is
* less or equal to zero.
*/
public LinkedHashMap(
int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
}
在这个LinkedHashMap初始化的时候赋值的,OK,我们再看下LruMemoryCache里的LinkedHashMap的初始化:
this.map = new LinkedHashMap(0, 0.75F, true);
看到了吧,源码里传入true,也就是说我们get的时候总会把调整当前key对应的entry,调整到链表的最后,the tail of the list。
接下来,我们来看下LruMemoryCache put方法:
public final boolean put(String key, Bitmap value)
{
if ((key == null) || (value == null)) {
throw new NullPointerException("key == null || value == null");
}
synchronized (this) {
this.size += sizeOf(key, value);
Bitmap previous = (Bitmap)this.map.put(key, value);
if (previous != null) {
this.size -= sizeOf(key, previous);
}
}
trimToSize(this.maxSize);
return true;
}
又是好简短,首先一个sizeOf方法,根据图片key,value,计算图片的大小,然后累积赋值 this.size ,之后会调用trimToSize方法:
private void trimToSize(int maxSize)
{
while (true)
synchronized (this) {
if ((this.size < 0) || ((this.map.isEmpty()) && (this.size != 0))) {
throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if ((this.size > maxSize) && (this.map.isEmpty()))
{
break;
}
Map.Entry toEvict = (Map.Entry)this.map.entrySet().iterator().next();
if (toEvict == null) {
break;
}
String key = (String)toEvict.getKey();
Bitmap value = (Bitmap)toEvict.getValue();
this.map.remove(key);
this.size -= sizeOf(key, value);
}
}
循环遍历,当添加的图片大于最大值时,就会remove掉,这时候我们会思考会不会误删掉最近使用的Bitmap呢?答案是不会的,为什么呢,LruMemoryCache的最近使用指的是最近操作get put方式操作的bitmap缓存,刚才我们已经说了,当我们get的时候会把这个entry的顺序调到链表的尾部,当我们remove时,从链表头部开始遍历删除bitmap,直到size小于等于我们设置的最大值,自然不会误删掉我们最近使用的Bitmap了。借用一下别人的一个图,非常形象:
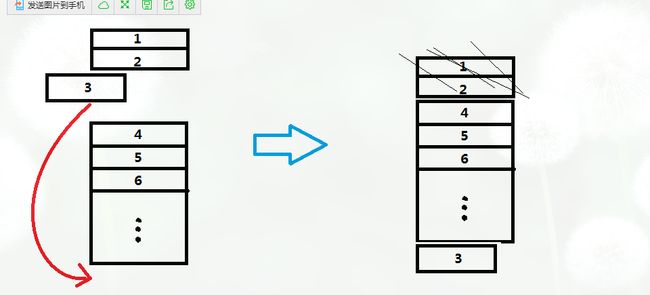
OK,这样看下来,我们通过查看LruMemoryCache的get put remove方法,了解了它的缓存策略。再来就是它的磁盘缓存。
我们先看下结构图:

思考就是我们如何保证下载到本地的图片不会重复或者覆盖掉呢?那就是保证命名唯一,我们可以看到有一个name的包,就是用来命名的,俗称命名生成器。