关键词记录
请求数据包小,返回数据大 ,差别不大
请求数据包大,返回数据小,差别大
代理 ----》热备
服务自治--->dubbo 名称服务--->hbase架构
收集提供秦秋处理的服务器的地址信息
劣势:第一:注册方放生问题 第二 发起请求建立连接的时间,第三代码升级比较复杂
路由方式:名称服务器(直接有路由策略) ,规则服务器(规则在应用服务器上解析),master服务器(规则在master服务器上完成)
分布式系统难点:
缺乏全局时钟
事务挑战:
ACID
两个阶段提交2PC
最终一致性
BASE
CAP
Paxos
2.1 什么是大型网站
分布式系统,
session问题:
http协议本身无状态
借助HTTP协议支持会话状态的机制session state。这样的机制应该可以使web服务器从多次单独的htpp请求中看到会话,也就是知道哪些请求时老次那个会话的。具体实现方式为:在会话开始时候,分配一个唯一的汇编表示SessionId,通过cookie把这个表示告诉浏览器,以后每次请求的时候浏览器都会带上这个会话标识来告诉web服务器请求时属于哪个会话的,在web服务器上,各个会话有独立的存储,保存不同的会话信息。如果遇到禁用cookie的情况,一般的做法就是把这个会话表示到url的参数中。
1、Session Sticky

根据sessionId来分发,
存在的问题:
如果一台web服务器宕机或者重启,那么这台机器上的会话数据会丢失,如果会话中有登录状态的数据,那么用户就要重新登录了。
会话表示是应用层的信息,那么负载均衡器要将同一个会话的请求都保存到同一个web服务器上的话,就需要进行应用层(第7层)的解析,这个开销比第四层的交换要大
负载均衡器变为一个有状态的节点,要将会话保存到具体的web服务器的映射,和无状态的节点相比,内存消耗会更大,容灾方面会更加麻烦
容器之间的session replication同步:简便
问题:造成网络带宽的开销。
session集中存储
问题:
引入了网络操作,存在因实行和不稳定性,不过我们的通讯基本发生在内网,问题不大。
如果集中存储session的机器或者集群有问题,会影响我们的应用
以上的session都携带在url请求
第二种写到cookie中,随身携带。
问题:暴露了服务器端的数据,,方法 对seesion数据加密,对于安全上来说物理上不能接触才是安全点额
带宽消耗
数据库读写分离:数据复制带来短期的数据不一致问题,数据的源和目标之间的映射关系以及过滤条的支持问题。
在mysql 5.5中加入了对semi-sync的支持,从数据安全角度来说,它比异步复制好。
Data Guard方案,容灾 故障恢复等场景
物理standby 逻辑备库 standby
like
倒排
什么数据应该走搜索,什么数据应该走数据库。构建搜索用的索引的过程就是一个数据复制的过程,只不过不过简单的复制对应的数据。
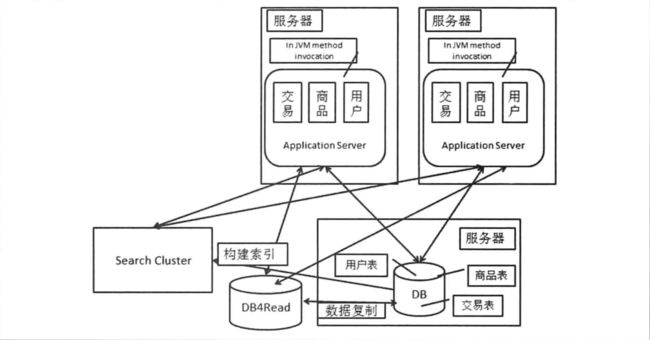
搜索集群的使用方式和读库的使用方式是一样的。可以从两个纬度对于搜索系统构建的索引的方式进行划分,一种是按照全量/增量划分,一种是按照实时/非实时划分。全量方式用于第一次建立索引(可能是新建,也可能是重建),而增量方式用于在全量的基础上持续更新索引。当然增量构建索引的挑战非常大,一般会加入每日的全量作为补充。实时和非实时的划分方式则体现在索引的更新时间上,之所以有非实时的方式 ,主要是考虑到对数据源头的保护。
搜索引擎的技术解解决了站内搜索时某些场景下的读的问题,提供量更好的查询查询效率。并且我们看到的站内搜索的结构和使用读库是非常类似的,我们可以把搜索引擎当成一个读库。
技术数据读取的利器---缓存
将应用热数据存放在缓存
这种方式和立业业务逻辑息息相关。
页面缓存--.>将特别热的页面进行缓存,减少动态重复生成页面锁带来的计算资源的消耗
采用ESI
web前端有个apache和nginx服务器,页面缓存ESI在apache中进行。web服务器产生的请求响应结果返回给apache,apache中的模块会对响应的结果做处理,找到ESI标签然后缓存中获取这些ESI标签对应的内容,如果内不存在(内容没有生成或者内容过期,那么apache中的模板会通过web服务去渲染这些内容,并且将结果放入缓存中,用内容条换掉ESI,返回给客户端开浏览器)。
后一者的方式是将渲染和缓存都在web服务器中进行。
弥补关系型数据库的不足,引入分布式存储系统
分布式数据库---->高容量,高并发访问,数据容灾的支持
数据的的垂直拆分和水平拆分两种选择。
专库专用,数据垂直才分
垂直拆分的意思是吧数据库中不同的业务数据拆分到不同的数据库中。
带来跨业务的事务。办法:分布式事务
数据水平拆分:
水平拆分就是把同一个表的数据才分到两个数据库中,产生的数据水平拆分的原因就是某个业务的数据表的数量达到了数据库的瓶颈,这时就可以把这个表拆分到两个或者多个数据库中。
数据水平拆分和读写分离的区别是,读写分离解决的是读压力的问题,对于数据量大或者更新量的情况并不起作用。
数据的水平拆分与数据的垂直拆分的区别是,垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是吧同一个表拆分到不同的数据库中。
水平拆分瘦给业务应用带来的影响:
1、sql路由问题
2、主键的处理发生变化,数据量大需要分页,处理比较难
拆分应用
1、不局限于单机内部的方法调用,引入了远程的服务调用
2、共享的代码不再是散落在不同方法调用了,这些实现被放在了各个服务中心
3、数据库的交互放在了服务中心1)前端注重交互,不必 关心注重业务逻辑2)降低数据库的链接数
4、维护方便
消息中间件:异步和解耦
远程过程调用和对象访问中间件:主要解决风不是环境下应用的互相访问问题
消息中间件:解决应用之间的消息传递、解耦、异步的问题
数据访问中间件:主要解决应用访问数据库的共性问题的组件。

hotspot
针对新生代
串行 GC Serial Coping
并行 GC ParNew
并行回收GC - Parallel scavenge
针对老年代
串行GC Serial MSC
并行MS GC Parallel MSC
并行 compacting GC Parallel Compacting
并发GC CMS
在JDK 6 UPDATE 14中引入了Garbage First G1回收器
G1的目标取代CMS

Nursery相当于HotSpot用的young 其中keep area区域可以使自己区域中的对象跳过一下次的YoungGC 也就是Keep Area区域的对象创建后,在第二次Young GC时才会被GC。
Java并发编程类、接口和方法
线程池
同样执行200000次的情况下使用线程池的场景一共消耗了120毫秒,而没有用线程池的场景则消耗了18852毫秒,
主要使用的线程池ThreadPoolExecutor
ScheduledThreadPoolExecutor
同步锁:syncronized 同步方法 同步静态方法,同步静态类,同步类 软件方式实现,同步阻塞,自旋阻塞
ReettrantLock jdk1.5加入 类似于synchronized 自旋----> 差别需要显式的进行unlock
为什么会有这个类?
ReetrantLock提供了tryLock方法,tryLock调用的时候,如果锁被其他线程持有,那么tryLock会立即返回,返回结果为false,如果锁没有被其他线程持有,那么当前调用线程会持有锁,并且tryLock返回的结果是True。
ReenTrantLock 同步快,tryLock --- >ReenTrantReadWriteLock 适合于写少读多的场景。readLock,writeLock组成
构造ReenTrantLock对象,构造接受一个boolean类型参数,描述公平与否的函数,公平的好处是等待锁的线程不会饿死,但是整体效率相对低一点,非公平锁的好处是整体效率相对高一些,但是有些线程可能会饿死或者说很早就在等待锁,但要等很久才会得到锁。其中的原因是公平锁是严格按照请求锁的顺序来排队获取锁的,而非公平锁是可以强占的,即如果某个时刻有线程需要获得锁,而这个时候刚好锁可用,那么这个就会直接抢占,而这时阻塞在等待队列的线程则不会被唤醒。
Synchronized 同步快,可见性
volatile 线程中不保存副本 直接调用主存的
采用AtomicInteger 内部通过JNI的方式使用了硬件支持的CAS指令
wait notify notifyAll
Object对象上定义的三个方法,用来完成线程间状态的通知
CountDownLatch 主要提供的机制是当多个(具体数量等于初始化CountDownLatch时的count参数的值)线程都到达了预期状态或完成预期工作时触发事件,其他线程可以等待这个事件来触发自己后续的工作。这里需要注意的是,等待的线程可以是多个,countDownLatch是可以唤醒多个等待的线程。
而等待的线程会调用countDownLatch的await方法。


CyclicBarrier 字面理解循环屏障,协同多个线程在屏障前等待,直到所有的线程都达到了这个屏障是在继续执行后续的动作。
semapgore 用户管理信号量 初始化传入参数即为并发数量, acquire或许信号许可,release归还信号许可。
Exchanger 交换。Exchager用于两个线程之间进行数据交换,当两个线程都到 同一个Exchanger的方法上,二者进行交换
Future 接口 和FutureTask 实现类
并发容器:
线程不安全,
CopyOnWrite的思路在更改容器的时的场景中会非常好
代理类与委托类具有同样的接口,代理类也有很多的实际应用
InvacationHandler
Proxy.newProxyInstance(
classloader
interfaces
)
需要讲清楚 反射的具体实现????????
反射是java提供的非常方便而又强大的功能,java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于人一个对象,都能够调用它的任意一个方法和属性。


问题:newInstance调用来构造对象时,要求被构造的对象的雷一定有一个无参数的构造函数。否则抛出异常。
字节码增强--> javassist cglib asm bcel
分布式环境下完成事务的思路???? 什么思路


服务化方案,真实的实施中的服务可能是多层的,服务之间也会有互相访问,这是需要加以管理的,
一般规则服务器更多的运用到有状态的场景。
请求方和服务提供房之间直连的方式
结构请求数据包实质把对象变为二进制数据,也就是常说的序列化(熟悉com的读者应该知道这个过程就是marshalling)
从发送请求到收到响应的过程,请求发送端所经过的主要环节。

Idl interface description language。接口描述语言的方式,然后生成代理存根代码,再分别于调用端和被调用端一起编译

classloader是java中一项非常关键的技术,结构如图:
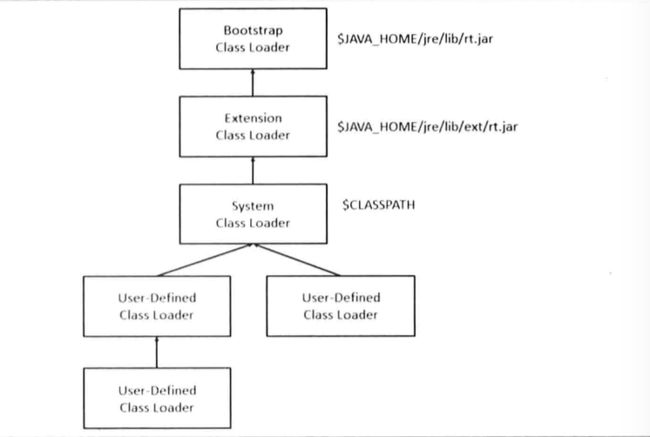
用户自定义--user-defined class loader。class loader 有多个,而且有机会进行隔离,
将服务框架自身的类与应用用的的类都控制在user-defiled class loader。以及osgi对于不同的bundle
的处理采用类似的方法
我们并不是每次调用远程服务前都通过这个服务注册查询中心来查询可用的地址,而是把地址缓存在调用者本地,当有变化时主动从服务注册中发起通知,告诉调用者列表的变化。
当客户端拿到可用的服务提供者的地址列表后,如何为档次的调用选择就路由要解决的问题了。我们在在这里首先要考虑的就是集群的负载均衡。具体到负载均衡是实现上,随机、轮询、权势比较常见的时间方式,其中权衡方式一般是指动态权重的方式,可以更具响应时间来进行计算。在服务提供者的机器能力对等的情况下,采用随机和轮询两种方式比较容易时间;在北调用的服务集群的机器能力使用权重计算的方式来进行路由比较适合。关于具体的负载均衡的策略,可以参考yin键负载均衡设备以及lvs haproxy等代替硬件负载均衡设备的系统所支持的策略,不过需要注意的是。
增加线程总数(增加物理机),但是这种思想不太经济也不抬可控,实际中计算需要的线程总数是很困难的事情,从系统可用性和经济性的角度考虑的话,控制这些慢的方法对正常情况的影响是比较合理的思路。第一种思路是增加资源保证系统的能力是超出需要的,第二种思路是隔离这些资源,从而使得快慢不同,重要级别不同方法之间无不影响。
在具体调用者的服务框架上获取规则后进行路由的处理,具体来说是根据服务定位提供服务的哪个集群的地址,然后与接口路由规则中的地址一起取交集,得到的地址列表再进行接下来的负载均衡算法,最终得到可用的地址去进行调用。
通信协议和服务调用协议的扩展性

NIO方式
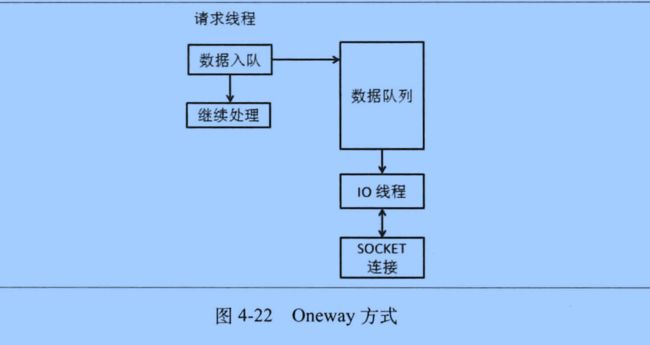
oneway 方式 只管发送而不关心结果的方式
第二种方式callback,这种方式下请求发送请求后会继续执行自己的操作,等对方响应时进行一个回调

IO线程通知回调对象,这时就执行回调的方法了,如果需要支持超时,同样可以通过定时任务的方式来完成,如果已经超时却没有返回,那么同样需要执行回调对象的方法,只是要告知的是已经超时没有结果。,这里需要值得注意的一点是,如果我们不再引入新的线程,那么回调的执行要么在IO线程中,要么是在定时任务线程中,我们还是建议用新的线程来执行回调。
第三种方式是:Future

使用Future方式,同时先发Future放入队列,然后把数据放入队列,接着就在线程中进行处理,等到请求线程的其他工作处理结束后,就通过Future来获取通信结果并直接控制超时,IO线程仍然是从数据队列中得到数据后再进行通信,得到结果后会把它传给Future
??研究下源码????
第四种是可靠异步
可靠异步要保证异步请求能够在远程被执行,一般是通过消息中间件来完成这个保证。
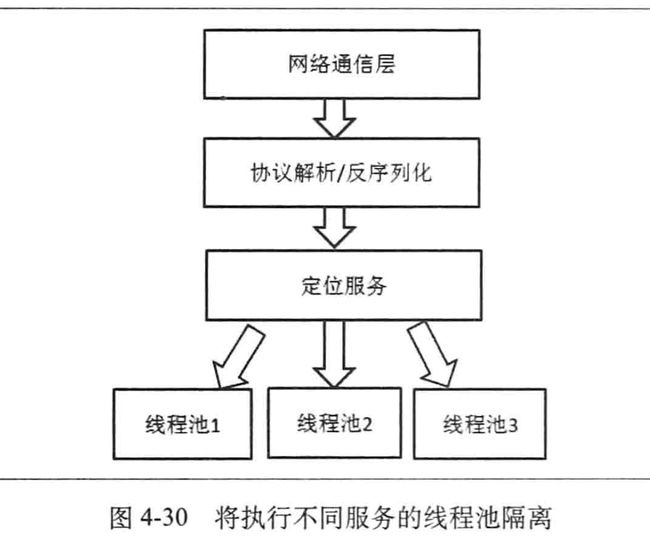
执行不同服务的线程池隔离
服务提供端的工作线程是一个线程池,路由到本地的服务请求会被放入这个线程池执行。什么叫线程池隔离??
接口,方法,参数---区别
QPS ,TPS 流控制实现
对不同的服务调用这进行不同的对待。这样的做法就是对不同的服务调用者进行分级,确保优先级高的服务调用这被优先提供服务。这也是确保稳定性的策略。
服务升级:
第一种情况接口不变,只是代码本身进行完善,这样的情况处理起来比较简单,因为提供给使用者的接口,方法都没有变,只是内部的实现有变化,这种情况下,采用灰度发布的方式验证然后全部发布就可以了
第二种情况需要修改原有的接口:分为以下两种情况:
一种在接口中增加方法,这个情况比较简单,直接增加方法就行。而且在这样的情况下,需要使用新方法的调用者就是用新方法,原来的调用者继续使用原来的那个方法即可。
二是要对接口的某些方法修改调用的参数列表。这种情况相对比较复杂些。我们有几种方式来应对。
1)通过版本号来解决,这是比较常用的方式,使用老方法的系统继续调用原来版本的服务,而需要使用新方法的系统则使用新版本的服务。
2)在设计方法上考虑参数的可扩展性。
实战中的优化:
1、服务拆分:要拆分的服务是需要为多方提供公共功能的,对于那些比较专用的实现,查出来他们是独立部署在远程机器上来提供服务的,这不仅没必要,还会增加系统的复杂性。
2、服务粒度
服务治理分为管理服务和查看服务两个方面,也相当于数据的读和写
ESB 企业服务总线
服务框架
ESB 概念 从面向服务体系架构中SOA发展过来的,
数据访问层:
数据库垂直/水平拆分的困难
优化三个思路:优化应用;二是看看有没有其他办法降低对数据库的压力:例如引入缓存、加索引等,最后一种思路就是把数据库的数据和访问分到多台数据库上,分开支持
垂直拆分会带来如下影响:
1、单机的ACID保证被打破了。数据到了多机后,解决:放弃单机事务,修改实现,要么引入分布式事务
2、一些join操作会变得比较困难,
了解分布式事务的知识--->事务的参与者,支持事务的服务器、资源服务器以及事务管理器分别会与分布式系统的不同节点上,
X/Open X/OPEN DTP distributed transaction processing reference model.
Application program ap 即应用程序 DTP
ResourceManager 资源管理器,可以理解为一个DBMS系统,资源必须实现XA定义的接口。资源管理器提供了存储共享资源的支持。
Transaction manager TM 事务管理器,负责协调和管理事务,提供给AP应用程序编程接口并管理资源管理器。事务管理器向事务指定标识,监视它们的进程,并负责处理事务的完成和失败。事务分支标识(称为XID)有TM指定,以表示一个RM内的全局事务和特定分支。它是TM中日志与RM中日志之间的相关标记。两个阶段提交或回滚需要XID,以便在系统启动时执行再同步操作(resync)

DTP:一个事务是一个完整的工作单元,由多个独立的计算任务组成,这多个任务在逻辑上是原子的。
全局事务:一次性操作个多资源管理器的事务就是全局事务。

two phase commit protocol
大型网站一致性的理论基础-CAP /BASE
分布式事务系统在多机环境下可以相单机系统那样做到强一致,这需要付出比较大的代价。而在有些场景下,接受状态并不时刻保持一致,只要最终一致就行。
CAP
consistency all nodes see the same data at the same time -----C
Availability:每个请求都能接受到一个反馈。
partition-tolerance:系统持续操作部分问题或者有消息丢失,但仍能继续运行。
BASE:
Basically Avalable 基本可用,允许分区失败
Soft state:软状态,接受一段时间的状态不同步
Eventually consistent 最终一致性,保证最终数据的状态是一致的
比两个阶段提交更轻一些的Paxos协议:
paxos协议是帮助我们解决分布式系统中一致性问题的一个方案。
集群内数据一致性算法实例:
quorum 法定人数
vector clock 算法来具体下,
实际工程中考虑最终一致的方法而不是追求强一致,从实现上来说,可以通过补偿的机制不断重试,让之前因为异常而没有进行到底的操作继续进行还不是回滚,如果还不能满足需求,那么继续paxos算法实现会是一个不错的选择。
多机的sequence问题与处理:
原来单库中的sequence以及自增的ID的做法需要改变。
唯一性
连续性
如果考虑ID的唯一性的话,可以考虑参考UUID的生成方式(或者根据自己的业务情况使用各种种子不用维度的标识,IP MAC 机器名 时间 本机计算器等因素生成唯一ID,但在整个分布式系统中的连续性不好)
连续性---实现方案,所有的ID集中放在一个地方进行管理,对每个ID序列独立管理,每台机器使用ID时都从这个ID生成器上取,需要解决的问题;
性能问题:每次都远程去ID会有资源损耗。一种该井方案是一次去一段ID,然后缓存在本地,这样就不需要每次都去远程的生成器上取ID,但是也会带来问题:如果应用取了一段ID,正在使用时完全宕机了,那么一些ID就浪费了。
ID生成器稳定性问题:id生成器作为一个无状态的集群存在,其可用性要靠整个集群来保证。
存储的问题。这确实是需要去考虑的问题,底层存储的选择空间较大,需要根据不同的类型进行对应的容灾方案,下面介绍两种方案:
我们自底层使用一个独立的存储来记录每个ID序列当前的最大值,并控制并发更新,这样一来ID生成器的逻辑就很简单了。

另一种:改变是直接把ID生成器舍弃,把相关的逻辑存放到需要生成ID的应用本身就行了。

应对多机的数据查询:
跨库join
1、在应用层把原来的数据库的join操作分成多次的数据库操作。我们有用户基本信息的数据表,也有用户出售商品的信息表,需要是查出号码为138XXXXXXX的用户在售的商品的总数。
2、数据冗余,也就是对一些常用的信息进行冗余,这样就可以把原来需要join的操作变为单标查询。这需要结合具体业务场景。
3、借助外部系统,搜索引擎解决一些夸库的问题。
同等步长:分页的内页中,来自不同数据源的记录是一样的,同等比例的意思是:分页的煤业中,来自不同的数据源的数据占这个数据源符合条件的数据总数的比例是一样的。





分布式数据访问层:数据层
演变 : 专有API---> 实现比较简单
第二种通用方式--->java应用中一般是通过JDBC方式访问数据库
还有一种是基于ROM或类ORM接口的方式,
mybatis hibernate spring jdbc

按照数据层流程的顺序看数据层设计

SQL方言----根据实际情况去做选择
具体解析是使用antlr、javacc还是其他工具,就看自己的选择了。
一个很重要的事情是根据执行的SQL得到被操作的表,根据参数及规则来确定目标数据源的连接。
规则处理阶段:
1、采用固定哈希算法作为规则
固定哈希的方式为,根据某个字段取模,然后将数据分散到不同的数据库和表中。

一致性hash 范围

虚拟节点对一致性哈希的改进
为了对应上述问题,我们引入虚拟节点的概念,四个物理节点可以变为很多个虚拟节点,每个节点虚拟节点支持连续的hash环上的一段,而这时如果加入一个物理节点,就会响应加入很多虚拟节点,这些虚拟节点是相对均匀的插入到整个hash环上的,这样就可以很好的分摊现有物理节点的压力了;如果减少一个物理节点,对应的很多虚拟节点就会失败,这样就会有很多剩余的虚拟节点来承担之前虚拟节点的工作,但是物理节点来说,增加的负载相对是均衡的。可以通过一个物理节点对应非常多的虚拟节点,并且同一个物理接点的虚拟节点尽量均衡分布的方式来解决增加或减少节点时负载不均衡的问题。

为什么要要改写sql
前面介绍了规则对分库分表的支持,如果设定规则,也就是如何分库分表,没有绝对同一的原则,一般的标准是分库后尽可能避免夸库查询。
对于没有经过解析的sql解析的SQL,在进行SQL替换时要特别注意,需要对各种情况全面思考。
在具体工程实践上,可以把配置集中在同一个地方管理,这样使用配置中心的应用就可以去配置管理中心获取具体配置内容,修改时只需要修改配置管理中心的值就可以了,配置管理中心的相关内容会在后。
构建AtomDataSource

数据库协议连接
或者驱动连接
协议适配器访问,

读写分离的挑战和应对:
读写分离分主库的读的压力。这里存在一个数据复制的问题,也就是把主库的数据复制到备库Slave去

数据结构相同,多从库对应一主库的场景,通过mysql的replication可以解决复制的问题,业务应用只要根据自身的业务特点把对数据延迟不太敏感的读切换到备库来进行就可以了。
对master进行分库


分库规则配置负责在读数据及数据同步服务器更新分库时让数据层知道分库规则。数据同步服务器和DB主库的交互主要是根据被修改的或新增的数据主键来获取内容,采用的是行复制方法。
可以说这是一个不休呀但能够解决问题的方法。,比较优雅的方式是基于数据库日志来进行数据的复制。

这是一个虚拟的订单的例子,在主库中,我们根据买家id进行了分库,把所有买家订单分到了四个库中,这保证了一个买家查询自己的交易记录时都在一个数据库上查询,不过卖家查询的时候就可能扩多个库了。我们可以用一组备库,在其中按照卖家ID进行分库,这样卖家从悲苦上查询自己的订单时就都在一个数据库中,那么这就需要我们完成这个非对称的复制,需要控制数据的分发,而不是简单进行镜像复制。
引入数据变更平台:
复制到其他数据库是数据变更的一种场景,

引入Extractor、applier、Extractor负责把数据源变更的信息加入到数据分发平台中,而applier的作用是把这些变更应用到响应的目标上。中间的数据分发是由多管道组成。不同的数据变更来源需要有不同的Extractor来进行解析和变成进入数据分发平台的工作。进入到数据分发平台的更新信息就是标准化,结构化的数据了,根据不同的目标用不同的applier吧数据落地到目标数据源上就可以了。,因此数据分发平台构建好之后,主要的工作就是实现不同类的的extractor和applier,从而接入更多类型的数据源。
如何做到数据的平滑的迁移:
对于无状态的应用,扩容和缩容是比较容易的。
如果不能接受长时间 的停机,那该怎么办?
对数据平滑迁移的最大挑战是,在迁移的过程中又不会有数据的变化,可以考虑方面是,在开始进行数据迁移时,记录增量的日志,在迁移结束后,在对增量的变化进行处理。在最后,可以把要迁移的数据的写暂停,保证增量日志都粗粒完毕后,再切换规则,放开所有的写,完成迁移工作。



处理新增日志时,还有新的增量日志进来,这是一个逐渐收敛的过程。
然后进行增量日志的处理,以是的新库表的数据是新的。
最后更新路由的规则,所有新数据的读或写就到了新表了,这样的完成了整个迁移过程。有了平滑迁移的支持,我们在进行数据库扩容和缩容时就会相对标准化和容易了,否则恐怕每次的扩容都要变成一个项目才能完成了。
总结



如何解决消息发送一致性
消息发送一致性的定义
消息发送一致性是指产生消息的业务动作与发送的一致,就是说如果业务操作成功了,那么由这个操作产生的消息一定要发送出去,否则就丢失消息了,另一方面,如果这个行为发生或者失败,那么就不应该吧消息发送出去。
JMS可以实现消息发送一致性吗???????????我们来看看看JMS消息的部分。



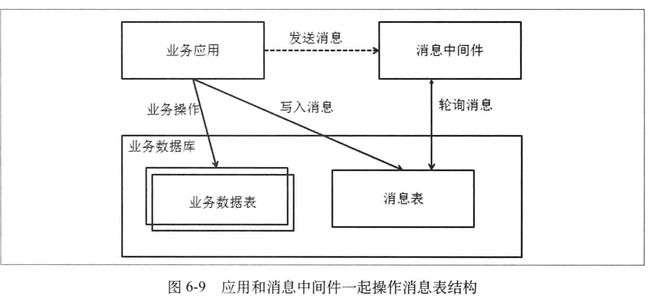
1 业务处理应用首先把消息发送给消息中间件,标记消息状态为待处理。

可靠性:
影响、
需要用业务自己的数据库承载消息数据
需要让消息中间件去访问业务数据库
需要业务操作的对象是一个数据库,或者说支持事务的存储,并且存储必须能够支持消息中间件的需求


JMS,每个Connection都有一个唯一的Client,yoghurt标记连接的唯一性,也就是说刚才对queue和topic的介绍中,我们是默认一个接受应用只用了一个连接,现在看下多个连接的情况,

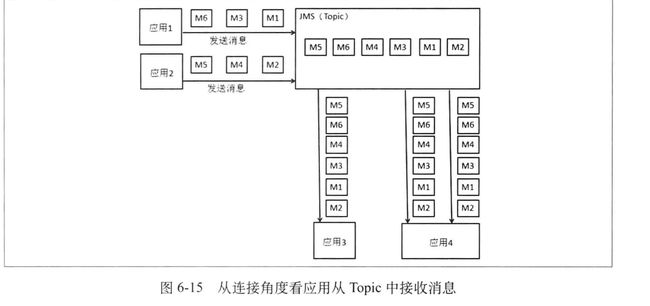
多集群订阅者解决方案



中间有三个节点需要保证可靠,分别是:消息发送者吧消息发送到消息中间件,消息中间件把消息存入消息存储
Active MQ 中的kaha persistence的一个实现
在投递过程中产生的消息重复接受主要是因为消息接受者成功处理完消息后,消息中间件不能及时更新投递状态造成的。
可以采用分布式事务来解决,不过这种方式比较复杂,成本也高,另一种方式要求消息接受者来处理重复的情况,也就是要求消息接受者的消息处理是幂等操作
。
幂等 idempotence是一个数学概念,常用于抽象代数中。有两种主要的定义;'
????????

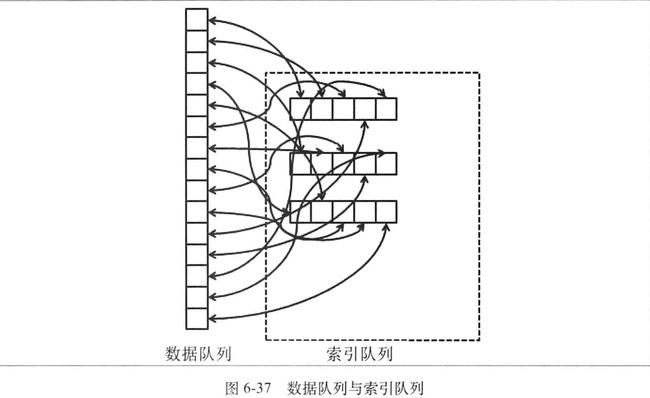
单机多队列的问题和优化,为了解决队列越多,消息写入接近随机写,保证写入有序,然后通过创建索引为是逻辑队列相互独立。但是在读的时候还是随机读取。
push和pull方式对比

push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
pull方式里,取消息的过程需要用户自己写,首先通过打算消费的Topic拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每个MessageQueue批量取消息,一次取完后,记录该队列下一次要取的开始offset,直到取完了,再换另一个MessageQueue。
软负载中心与集群配置管理




ConcurrentHashMap线程安全地并发HahMap来管理所有的dataId手,这在并发上比Hashtable或加锁的HashMap要好很多。而对于响应的value处理也是我们需要注意的地方。一种方式是使用linkedList来实现,但是注意在进行数据增删是需要加锁,读时也需要加锁,否则是是非线程安全的,另外也可以用一个ConcurrentHashMap来实现,其中Key是产生这个数据信息数据发布者的表示,而Vaue就是具体的数据。而使用ConcurrentHahsMap也是需要注意咋新曾dataId数据处理时的处理,因为这时可能是多线程都会新增,使用putIfAbsent并且进行返回值的判断,能够帮助我们正确处理这个场景。





集群配置管理中心
持久指数据本身与联发布者的声明周期无关的,典型的是持久订阅关系、路由规则、数据访问层的分库分表规则和数据库配置等;非持久规则则是发布者声明周期有关联的,如服务地址列表。此外服务地址列表、订阅关系等数据是需要聚合的;而路由规则以及一些设置项的佩蓉则不需要聚合。具体可以分为非持久/聚合、持久/聚合、持久/非聚合和非持久/非聚合四类。我们按照数据是否持久进行划分,软负载中心管理是非持久数据,而集中配置管理中心则是为了管理持久数据,两个可以支持数据的数据

客户端实现容灾策略 客户端通过http协议集中配置管理中心进行通讯
改进是采用长轮询 long polling