阅读目录:
1. ELK Stack 简介
2. 环境准备
3. 安装 Elasticsearch
4. 安装 Kibana
5. Kibana 使用
6. Elasticsearch 命令
最近在开发分布式服务追踪,使用 Spring Cloud Sleuth Zipkin + Stream + RabbitMQ 中间件,默认使用内存存储数据,但这样应用于生产环境,就不太合适了。
最终我采用的方案:服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana。
这篇文章主要记录 Elasticsearch 和 Kibana 环境的配置,以及采集服务追踪数据的显出处理。
1. ELK Stack 简介
ELK 是三个开源软件的缩写,分别为:Elasticsearch、Logstash 以及 Kibana,它们都是开源软件。不过现在还新增了一个 Beats,它是一个轻量级的日志收集处理工具(Agent),Beats 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具,目前由于原本的 ELK Stack 成员中加入了 Beats 工具所以已改名为 Elastic Stack。
根据 Google Trend 的信息显示,Elastic Stack 已经成为目前最流行的集中式日志解决方案。
Elastic Stack 包含:
Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。详细可参考 Elasticsearch 权威指南
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 Elasticsearch 上去。
Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Beats 在这里是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。
目前 Beats 包含六种工具:
Packetbeat: 网络数据(收集网络流量数据)
Metricbeat: 指标(收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat: 日志文件(收集文件数据)
Winlogbeat: windows 事件日志(收集 Windows 事件日志数据)
Auditbeat:审计数据(收集审计日志)
Heartbeat:运行时间监控(收集系统运行时的数据)
ELK 简单架构图:
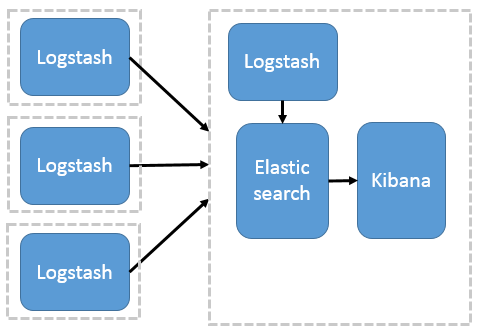
2. 环境准备
服务器环境:Centos 7.0(目前单机,后续再部署集群)
Elasticsearch 和 Logstash 需要 Java 环境,Elasticsearch 推荐的版本为 Java 8,安装教程:确定稳定的 Spring Cloud 相关环境版本
另外,我们需要修改下服务器主机信息:
[root@node1 ~]# vi /etc/hostnamenode1[root@node1 ~]# vi /etc/hosts192.168.0.11 node1127.0.0.1 node1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 node1 localhost localhost.localdomain localhost6 localhost6.localdomain6
注意:我之前安装 Elasticsearch 和 Kibana 都是最新版本(6.x),但和 Spring Cloud 集成有些问题,所以就采用了 5.x 版本(具体 5.6.9 版本)
3. 安装 Elasticsearch
运行以下命令将 Elasticsearch 公共 GPG 密钥导入 rpm:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在/etc/yum.repos.d/目录中,创建一个名为elasticsearch.repo的文件,添加下面配置:
[elasticsearch-5.x]name=Elasticsearch repositoryfor5.x packagesbaseurl=https://artifacts.elastic.co/packages/5.x/yumgpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearchenabled=1autorefresh=1type=rpm-md
Elasticsearch 源创建完成之后,通过 makecache 查看源是否可用,然后通过 yum 安装 Elasticsearch:
[root@node1 ~]# yum makecache && yum install elasticsearch -y
修改配置(启动地址和端口):
[root@node1 ~]# vi /etc/elasticsearch/elasticsearch.ymlnetwork.host: node1# 默认localhost,自定义为iphttp.port: 9200
要将 Elasticsearch 配置为在系统引导时自动启动,运行以下命令:
[root@node1 ~]# sudo /bin/systemctl daemon-reload[root@node1 ~]# sudo /bin/systemctl enable elasticsearch.service
Elasticsearch 可以按如下方式启动和停止:
[root@node1 ~]# sudo systemctl start elasticsearch.service[root@node1 ~]# sudo systemctl stop elasticsearch.service
列出 Elasticsearch 服务的日志:
[root@node1 ~]# sudo journalctl --unit elasticsearch-- Logs begin at 三 2018-05-09 10:13:46 CEST, end at 三 2018-05-09 10:53:53 CEST. --5月 09 10:53:43 node1 systemd[1]: [/usr/lib/systemd/system/elasticsearch.service:8] Unknown lvalue'RuntimeDirectory'insection'Service'5月 09 10:53:43 node1 systemd[1]: [/usr/lib/systemd/system/elasticsearch.service:8] Unknown lvalue'RuntimeDirectory'insection'Service'5月 09 10:53:48 node1 systemd[1]: Starting Elasticsearch...5月 09 10:53:48 node1 systemd[1]: Started Elasticsearch.5月 09 10:53:48 node1 elasticsearch[2908]:which: no javain(/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin)5月 09 10:53:48 node1 elasticsearch[2908]: could not find java;setJAVA_HOME or ensure java isinPATH5月 09 10:53:48 node1 systemd[1]: elasticsearch.service: main process exited, code=exited, status=1/FAILURE5月 09 10:53:48 node1 systemd[1]: Unit elasticsearch.service entered failed state.
出现了错误,具体信息是未找到JAVA_HOME环境变量,但我们明明已经配置过了。
解决方式(参考资料:https://segmentfault.com/q/1010000004715131):
[root@node1 ~]# vi /etc/sysconfig/elasticsearchJAVA_HOME=/usr/local/java
重新启动:
sudo systemctl restart elasticsearch.service
或者通过systemctl命令,查看 Elasticsearch 启动状态:
[root@node1 ~]# systemctl status elasticsearch.serviceelasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled) Active: active (running) since 一 2018-05-14 05:13:45 CEST; 4h 5min ago Docs: http://www.elastic.co Process: 951 ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec (code=exited, status=0/SUCCESS) Main PID: 953 (java) CGroup: /system.slice/elasticsearch.service └─953 /usr/local/java/bin/java -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingO...5月 14 05:13:45 node1 systemd[1]: Started Elasticsearch.
发现 Elasticsearch 已经成功启动。
查看 Elasticsearch 信息:
[root@node1 ~]# curl -XGET 'http://node1:9200/?pretty'{"name":"AKmrtMm","cluster_name":"elasticsearch","cluster_uuid":"r7lG3UBXQ-uTLHInJxbOJA","version": {"number":"5.6.9","build_hash":"877a590","build_date":"2018-04-12T16:25:14.838Z","build_snapshot":false,"lucene_version":"6.6.1"},"tagline":"You Know, for Search"}
4. 安装 Kibana
运行以下命令将 Elasticsearch 公共 GPG 密钥导入 rpm:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在/etc/yum.repos.d/目录中,创建一个名为kibana.repo的文件,添加下面配置:
[kibana-5.x]name=Kibana repositoryfor5.x packagesbaseurl=https://artifacts.elastic.co/packages/5.x/yumgpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearchenabled=1autorefresh=1type=rpm-md
安装 Kibana:
[root@node1 ~]# yum makecache && yum install kibana -y
修改配置(地址和端口,以及 Elasticsearch 的地址,注意server.host只能填写服务器的 IP 地址):
[root@node1 ~]# vi /etc/kibana/kibana.yml# Kibana is served by a back end server. This setting specifies the port to use.server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.# The default is 'localhost', which usually means remote machines will not be able to connect.# To allow connections from remote users, set this parameter to a non-loopback address.server.host:"192.168.0.11"# The Kibana server's name. This is used for display purposes.server.name:"kibana-server"# The URL of the Elasticsearch instance to use for all your queries.elasticsearch.url:"http://node1:9200"# 配置kibana的日志文件路径,不然默认是messages里记录日志logging.dest: /var/log/kibana.log
创建日志文件:
[root@node1 ~]# touch /var/log/kibana.log; chmod 777 /var/log/kibana.log
要将 Kibana 配置为在系统引导时自动启动,运行以下命令:
[root@node1 ~]# sudo /bin/systemctl daemon-reload[root@node1 ~]# sudo /bin/systemctl enable kibana.service
Kibana 可以如下启动和停止
[root@node1 ~]# sudo systemctl start kibana.service[root@node1 ~]# sudo systemctl stop kibana.service
查看启动日志:
[root@node1 ~]# sudo journalctl --unit kibana5月 09 11:14:48 node1 systemd[1]: Starting Kibana...5月 09 11:14:48 node1 systemd[1]: Started Kibana.
然后浏览器访问:http://node1:5601
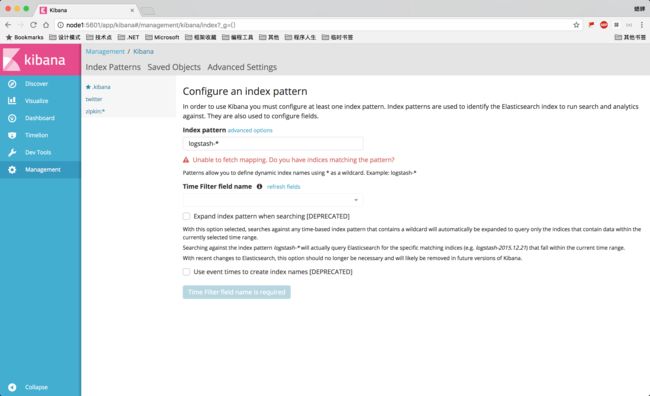
初次使用时,会让你配置一个默认的 index,也就是你至少需要关联一个 Elasticsearch 里的 Index,可以使用 pattern 正则匹配。
注意:如果 Elasticsearch 中没有数据的话,你是无法创建 Index 的。
如果 Spring Cloud Sleuth Zipkin + Stream + RabbitMQ 配置正确的话(以后再详细说明),服务追踪的数据就已经存储在 Elasticsearch 中了。
5. Kibana 使用
创建zipkin:*索引(*匹配后面所有字符):
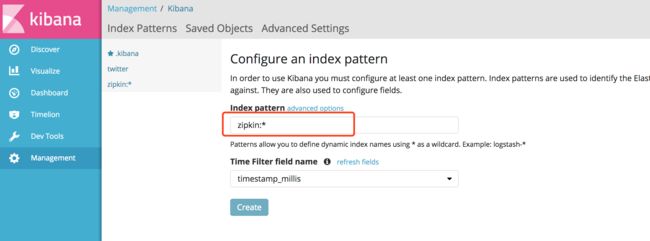
然后就可以查看服务追踪的数据了:

也可以创建自定义仪表盘:

6. Elasticsearch 命令
创建索引:
$ curl -XPUT'http://node1:9200/twitter'
查看 Index 索引列表:
$ curl -XGET http://node1:9200/_cat/indices
yellow open twitter k1KnzWyYRDeckjt7GASh8w 5 1 1 0 5.1kb 5.1kb
yellow open .kibana 8zJGQkq8TwC4s3JJLMX44g 1 1 1 0 4kb 4kb
yellow open student iZPqPcwrQbifGOfE9DQYvg 5 1 0 0 955b 955b
添加 Document 数据:
$ curl -XPUT'http://node1:9200/twitter/tweet/1'-d'{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elastic Search"
}'
获取 Document 数据:
$ curl -XGET'http://node1:9200/twitter/tweet/1'{"_index":"twitter","_type":"tweet","_id":"1","_version":1,"found":true,"_source":{"user":"kimchy","post_date":"2009-11-15T14:12:12","message":"trying out Elastic Search"}}%
查询zipkin索引下面的数据:
$ curl -XGET'http://node1:9200/zipkin:*/_search'
参考资料:
集中式日志系统 ELK 协议栈详解
ELK+Filebeat搭建实时日志分析平台
如何在CentOS 7上安装Elasticsearch,Logstash和Kibana(ELK堆栈)
Spring Cloud Sleuth进阶实战
How To Install Elasticsearch, Logstash, and Kibana (ELK Stack) on CentOS 7
如何在 CentOS 7 上安装 Elastic Stack
搭建ELK日志分析平台(下)—— 搭建kibana和logstash服务器(推荐)
搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群(推荐)