
开讲之前,我们先来回顾一下数据仓库的定义。
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。这个概念最早由数据仓库之父比尔·恩门(Bill Inmon)于1990年在《建立数据仓库》一书中提出,近年来却被愈发广泛的提及和应用,不信看下图:
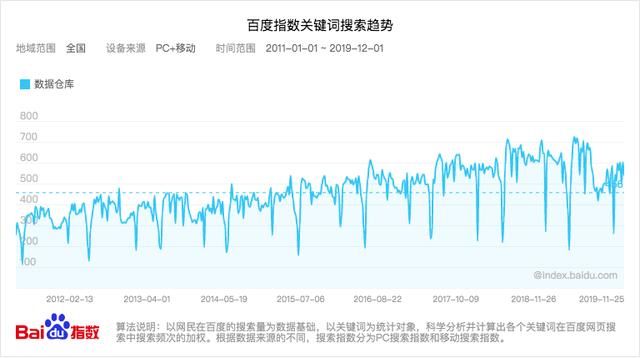
到底是什么,让一个从上世纪90年代提出的概念,在近几年确越来越热?带着这个问题,我们来了解一下产业真实的变化。
根据统计局的数字显示,近年来数字经济总体规模占GDP的比重越来越高,截止2018年将近35%;数字经济增速与GDP增速的差距逐渐拉大,远高于同期GDP增速。
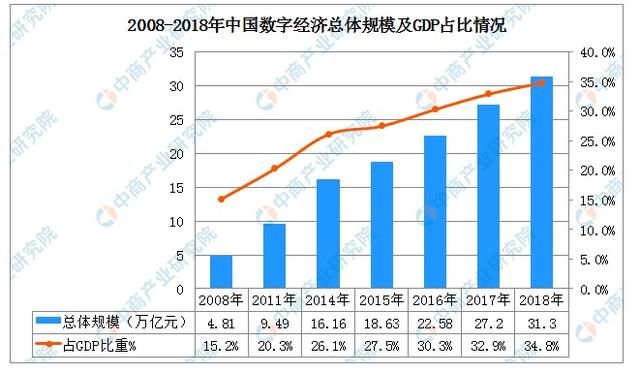
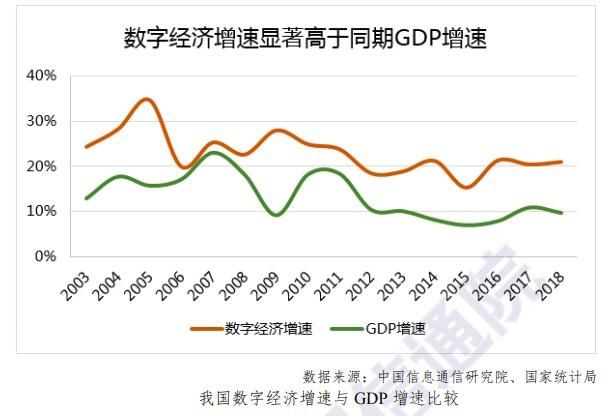
在 2014年,“新常态”一词被首次提出,指出从当前中国经济发展的阶段性特征出发,适应新常态,保持战略上的平常心态。在新常态下,数据经济背后的信息化正催生数据发挥着巨大价值,未来也会一样。


在这样的背景下,“数据”、“数据分析”、“人工智能”、“IOT”这些行业关键词在百度指数搜索趋势一路攀升。而随着转型的深入,人工智能和物联网技术被越来越广泛的接受和应用,这背后所产生的数据呈大规模增长态势,数据被依赖的程度越来越高。
所以,回到文章开头的问题“数据仓库,一个从上世纪90年代提出的概念,为啥近几年确越来越热了呢?”答案就是随着时代的发展,数据的价值正在被无限的索求、挖掘与放大。其价值的背后需要数据采集、存储、互通、治理、运用的一整套机制。
那么问题又来了,该怎么做才能正确构建企业数据仓库?
别慌!干货来了!接下来就是数据仓库从搭建到应用的一整套方法论详解,别眨眼别退出,看完全部如果觉得有用记得点赞收藏和分享!
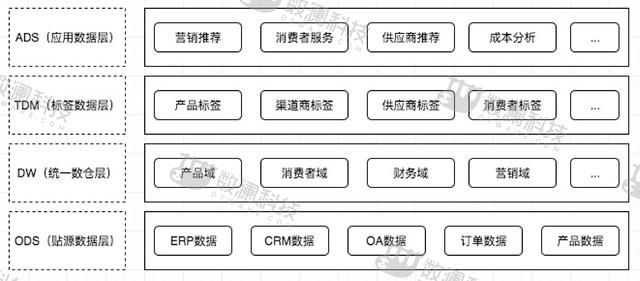
先来看张体系图:

我们这里所说的数据仓库,是基于大数据体系的,里面包含标签类目,区别于传统的数据仓库。下面我们来将这张图分解,逐个做简要分析。
一、前期调研
调研是数仓搭建的基础,根据建设目标,我们将调研分为三类:业务调研、业务系统调研、业务数据调研。
业务调研内容:
项目承载的业务是什么,业务的特征和性质
当前的业务流程,有真实流程表格和报告最好,用一个实例的方式来展示整个业务流程
业务专业术语、产品资料、规则算法、逻辑条件等资料
关注用户对流程中存在的问题和痛点描述、以及期望
业务系统调研内容:
清楚了解项目有哪些系统,每个系统对接人,重点系统详细介绍功能和交互
整体系统架构,调用规模,子系统交互方式,并发和吞吐量目标
系统技术选型和系统当前技术难点
数据调研内容:
可提供的数据
数据源类型、环境、数据规模
数据接口方式:文件接口、数据库接口、web service接口等
数据目录,数据字段类型、字典、字段含义、使用场景
数据在业务系统中流向等
二、数据建模
数据建模是数仓搭建的灵魂,是数据存储、组织关系设计的蓝图。
分层架构是对数据进行逻辑上的梳理,按照不同来源、不同使用目的、不同颗粒度等进行区分,使数据使用者在使用数据的时候更方便和容易理解,使数据管理者在管理数据的时候更高效和具有条理。我们推荐的分层架构是:
维度建模是Kimball在《数据仓库工具箱》中所倡导的数据建模方法,也是目前在大数据场景下我们推荐使用的建模方法。因为维度建模以分析决策的需求出发来构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
维度建模的核心步骤如下:
选择业务过程:对业务生命周期中的活动过程进行分析
声明粒度:选择事实表的数据粒度
维度设计:确定维度字段,确定维度表的信息
事实设计:基于粒度和维度,将业务过程度量
设计原则:
易用性:冗余存储换性能,公共计算下沉,明细汇总并存
高内聚低耦合:核心与扩展分离,业务过程合并,考虑产出时间
数据隔离:业务与数据系统隔离,建设与使用隔离
一致性:业务口径一致,主要实体一致,命名规范一致
中性原则:弱业务属性,数据驱动
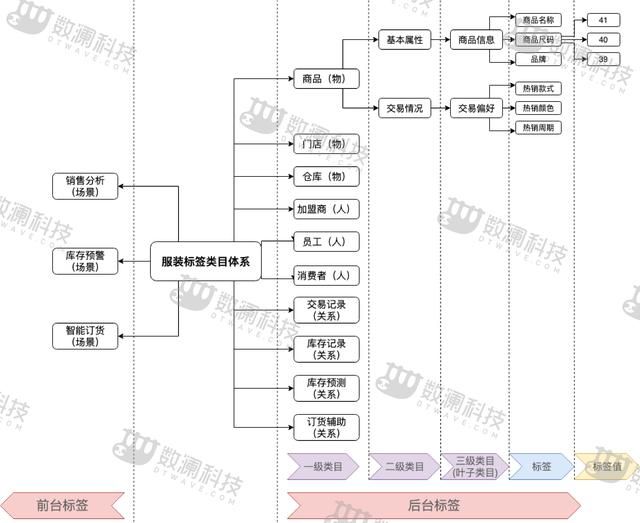
三、标签类目
标签,是数据资产的逻辑载体。数据资产,指的是能够给业务带来经济效益的数据。所以,标签类目的建设在整个数据中心的建设过程中具有核心地位。
标签的设计需要结合数据情况和业务需求,因为标签值就是数据字段值,同时标签是要服务于业务的,需要具备业务意义。假如,标签的设计仅基于业务方以往的经验得出,那么最终开发出来的标签值可能会失去标签的使用意义,比如值档次分布不均、有值的覆盖率低等。
基于标签开发方式,我们将标签分为以下三类:
基础标签:直接对应的业务表字段,如性别、城市等
统计标签:标签定义含有常规的统计逻辑,开发时需要通过简易规则进行加工,如年增长率、月平均收益率等
算法标签:标签定义含有复杂的统计逻辑,开发时需要通过算法模型进行加工,如企业信用分、预测年销量等
基于标签应用场景,我们将标签分为以下二类:
后台标签:开发场景下,面向开发人员,不涉及业务场景,聚焦标签设计、开发、管理。
前台标签:应用场景下,面向业务人员,结合业务场景,聚焦对后台标签的直接使用或组合使用。
随着大量的标签产生,为了更好的管理和使用,我们需要将标签进行分类。所有的事物都可以归类于三类对象:人、物、关系,所以我们可以对标签按照人、物、关系来划分一级类目,再按照业务特性对每个一级类目进行二级、三级的拆分,通常我们建议将标签类目划分到三级。
四、开发实施
经过前期调研、数据建模、标签设计之后,接着会进入到开发阶段,开发实施的关键环节由以下几部分组成:
同步汇聚
清洗加工
测试校验
调度配置
发布上线
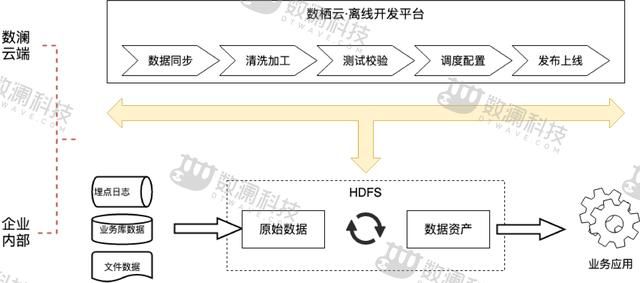
工欲善其事,必先利其器。一个好的开发工具对开发进度、成本、质量等具有举足轻重的影响。目前市面上很多开源,如Kettle、Azkaban、Hue等多多少少具有部分功能,但是要形成一个从端到端的数据自动化生产,需要将多个开源工具进行组合并通过复杂甚至人工方式进行衔接,整个过程复杂、低效和可靠性低。数栖云一站式离线开发平台,就是为了解决上述问题而生的。

开发落地,规范先行,遵守一套标准规范是整个开发质量和效率的保障。该套数据开发规范应该具备以下几个核心内容:
公共规范
层次调用约定
数据类型规范
数据冗余拆分
空值处理原则
刷新周期标识
增量全量标识
生命周期管理
......
ODS层模型开发规范
表命名规范
任务命名规范
数据同步方式
数据清洗规范
ODS层架构
数据同步及处理规范
命名规范
DW层模型开发规范
......
通过工具+规范,促使我们的开发实施快速做好。
五、治理维护
随着调度作业和数据量的增长,管理和维护会成为一项重要任务。
数据管理的范围很大,贯穿数据采集、应用和价值实现等整个生命周期全过程。所谓的数据管理就是通过对数据的生命周期的管理,提高数据资产质量,促进数据在“内增值,外增效”两方面的价值表现。数据管理的核心内容为:
数据标准管理
数据模型管理
元数据管理
主数据管理
数据质量管理
数据安全管理
数据监控是数据质量的保障,会根据数据质量规则制定监控策略,当触发规则时能够自动通知到相关人。基础的数据质量监控维度有以下几部分:
完整性
特定完整性:必须有值的字段中,不允许为空
条件完整性:根据条件字段值必须始终存在
唯一性
特定唯一性:字段必须唯一
条件唯一性:根据业务条件,字段值必须唯一
有效性
范围有效性:字段值必须在指定的范围内取值
日期有效性:字段是日期的时候取值必须是有效的
形式有效性:字段值必须和指定的格式一致
一致性
参照一致性:数据或业务具有参照关系的时候,必须保持其一致性
数据一致性:数据采集、加工或迁移后,前后的数据必须保持一致性
准确性
逻辑正确性:业务逻辑之间的正确性
计算正确性:复合指标计算的结果应符合原始数据和计算逻辑的要求
状态正确性:要维护好数据的产生、收集和更新周期
当出现数据异常后,需要快速的进行恢复。基于异常和修复场景,有以下几种数据运维方式:
平台环境问题引起的异常
重跑:当环境问题解决后,重新调度作业,对当天的数据进行修复
重跑下游:当环境问题解决后,重新调度某一个工作流节点的作业及其下游,对当天该作业及其下游的数据进行修复
业务逻辑变更或代码 bug 引起的异常
补数据:对应作业代码更新并重新发布到生产后,重新生成异常时间段内的该作业数据
补下游:对应作业代码更新并重新发布到生产后,重新生成异常时间段内的该作业及其下游的数据
其他
终止:终止正在被执行的作业
数据安全主要是保障数据不被窃取、破坏和滥用,包括核心数据和隐私数据,以及确保数据系统的安全可靠运行。需要构建系统层面、数据层面和服务层面的数据安全框架,从技术保障、管理保障、过程保障和运行保障多维度保障大数据应用和数据安全。
系统层面
技术架构
网络传输
租户隔离
权限管理
数据层面
数据评估:对数据来源、用途、合法性等进行评估
数据脱敏:对隐私数据进行脱敏处理
数据权限:根据数据使用者的不同角色和需求,开放不同权限
血缘追溯:建立数据血缘关系,可追溯数据生产的来龙去脉
下载限制:限制数据结果集的下载条数,防止数据外泄
服务层面
应用监控:监控数据使用端、使用次数、使用流量等
接口管理:生产和管理数据输出接口
数据脱敏
六、数据应用
给业务赋能,是数据价值的最终体现,也就是我们讲的数据业务化。数据业务化的方向有两种:业务优化和业务创新。在数据业务化的过程中,为了更方便的服务于上层应用,我们先将数据形成服务接口,然后让业务应用直接调用服务接口,即形成 数据服务化+服务业务化。
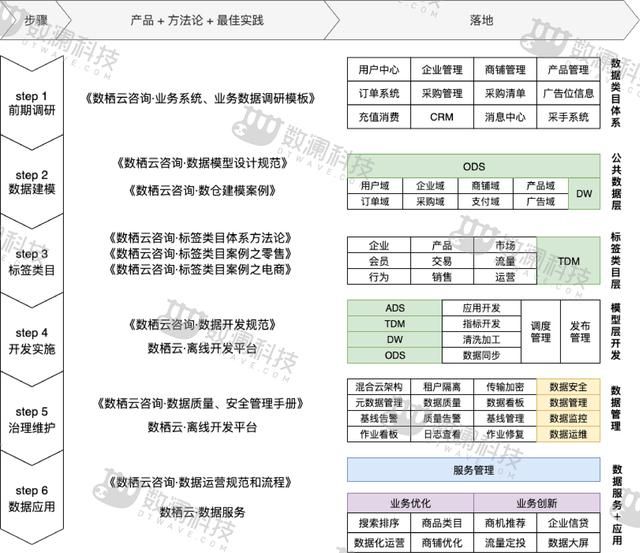
如何通过已有的 产品 + 方法论 + 最佳实践 去完成一个业务优化和业务创新呢?这里有一张完整的图,帮助你更快的理解全过程。
以上,就是我们对于数据仓库建设实践积累总结出的经验分享,欢迎与我们共同讨论,共同碰撞!不服来稿!同时如果你觉得这篇文章对你有帮助,别忘了把这篇文章分享出去给更多人看到~
如果你对数栖云感兴趣,也欢迎进入:dtcloud.dtwave.com