1."淘宝商品信息定向爬虫"实例介绍
2."淘宝商品信息定向爬虫"实例编写
3."淘宝商品信息定向爬虫"实例数据解析
4.单元小结
网页链接【Python网络爬虫与信息提取】.MOOC. 北京理工大学
https://www.bilibili.com/video/av9784617/index_37.html#page=43
最近更新:2018-01-18
1."淘宝商品信息定向爬虫"实例介绍
1.1功能描述

- 打开淘宝链接-https://www.taobao.com/,搜索书包.就能看到很多书包的信息. 提交淘宝页面关键词浏览器返回的的链接信息

- 发现search?q=书包,书包是我们搜索的关键词,q就是引进关键词的变量.前面这一部分就是向淘宝提交关键词的链接接口.
- 在看看第二页,第三页,提交相关的链接,有一点不同.就是最后s这个变量.第二页s=44,第三页s=88.如果细心数一下每页淘宝展示的商品数量,恰好是44个商品.因此我们可以得出这样的猜测变量s是第二页,第三页,甚至更多下一页的起始商品的编号.
- 通过这样的基本分析,可以得到淘宝提交搜索的接口以及对应每一页翻页的url的参数变量.可以确立向淘宝商品提交商品相关的url接口.
1.2定向爬虫的可行性
- 作为爬虫,要确认淘宝是否允许用户在网页上爬取相关信息.因此我们需要查看淘宝的robots协议.https://www.taobao.com/robots.txt
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Disallow: /product/
Disallow: /
User-Agent: Googlebot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-agent: Bingbot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-Agent: 360Spider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Yisouspider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Sogouspider
Allow: /article
Allow: /oshtml
Allow: /product
Disallow: /
User-Agent: Yahoo! Slurp
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-Agent: *
Disallow: /
-
查看最后一条robots协议,robots对所有的爬虫限制了disallow.

- 由此可以得出,淘宝是不允许爬虫爬取相关的页面信息.如果对淘宝的访问与个人有相同的频率.并不体现对淘宝的性能骚扰,也可以用这样的链接进行实例的教学以及实例的探索.但是请不要不加限制的爬取网页.
1.3程序的结构设计

2."淘宝商品信息定向爬虫"代码及显示结果
2.1完整的代码
import requests
import re
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price=eval(plt[i].split(":")[1])
title=eval(tlt[i].split(":")[1])
ilt.append([price,title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count=0
for g in ilt:
count=count+1
print(tplt.format(count,g[0],g[1]))
print("")
def main():
goods="书包"
depth=2
start_url="https://s.taobao.com/search?q="+goods
infoList=[]
for i in range(depth):
try:
url=start_url +"&s="+str(44*i)
html=getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
2.2显示结果

3."淘宝商品信息定向爬虫"实例数据解析
3.1流程框架设计
3.1.1getHTMLText(url)
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
- getHTMLText这个是获得页面的函数.
3.1.2parsePage(ilt,html)
def parsePage(ilt,html):
try:
plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price=eval(plt[i].split(":")[1])
title=eval(tlt[i].split(":")[1])
ilt.append([price,title])
except:
print("")
- 这个函数是主流程的关键.parsePage这个是对每一个获得页面进行解析.从商品页面信息获取商品名称和价格.
- 有两个变量,ilt是对结果的列表类型,html是相关页面的信息.
3.1.3printGoodsList(ilt)
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count=0
for g in ilt:
count=count+1
print(tplt.format(count,g[0],g[1]))
print("")
- printGoodsList这个是对淘宝商品的信息输入到屏幕上.
3.1.4main()
def main():
goods="书包"
depth=2
start_url="https://s.taobao.com/search?q="+goods
infoList=[]
for i in range(depth):
try:
url=start_url +"&s="+str(44*i)
html=getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
- main这个是主程序,记录程序运行的相关过程.
- 搜索的关键词是goods,书包作为解锁词,即goods="书包".
- 同时要设定向下一页爬取的深度.假设爬取是当前页第二页,这个深度设为2,即depth=2.
- 还要给出淘宝爬取信息的相关url,这个url中通过跟变量goods相整合来实现对商品的检索,即
start_url="https://s.taobao.com/search?q=" + goods
- 对输出结果定义一个变量,即:
infoList=[]
-
开始对这个程序进行爬取.针对页面的访问深度,返回页面中,每一个页面是一个不同的url.比如点下一页,会有下一页的url,因此我们对每一个页面进行单独的访问处理.我们这里用一个for循环.
对url的每一个页面链接进行设计,即 url=start_url +"&s="+str(44*i)
这里44*i对于第一个页面和第二个页面,对于每一个页面有个起始变量s,这个s是以44为倍数的.所以我们在第一个页面的s变量为0,第二页就是44,后续页面就是44的倍数.
通过getHTMLText(),来获得网页.即html=getHTMLText(url)
通过parsePage()来获得页面的解析过程.即parsePage(infoList,html)
这里通过try and except对这些过程中发现的错误进行异常判断.如果某个页面解析出了问题.我们就会下一页面的解析.而不影响整个程序的执行.
当所有的页面解析之后,通过printGoodsList()来打印相关信息.而这里的信息是保持在infoList列表中.
最后通过调用main()来使程序运行.
3.2具体函数的介绍
3.2.1getHTMLText()
- 这个代码需要注意encoding的处理,r.encoding=r.apparent_encoding将对文本分析的编码来替换整体的编码.居于这个语句是否适用,需要手工进行判断,r.encoding是否获得文件的编码信息.
3.2.2parsePage()
-
这个函数是整个程序的关键,是从商品页面信息中获取商品的名称和价格.除了编写代码外,还要看看页面的源代码有什么特点.
- 打开浏览器,找到商品搜索页面.点击右键,查看源代码,获得页面的源代码信息.能看到返回页面的html代码.找一下我们第一页的第一个商品.对于价格在代码所在的位置,具体如下两张截图: (备注:第一个价格59元,所在位置在源代码用橘红色标注)
-
-
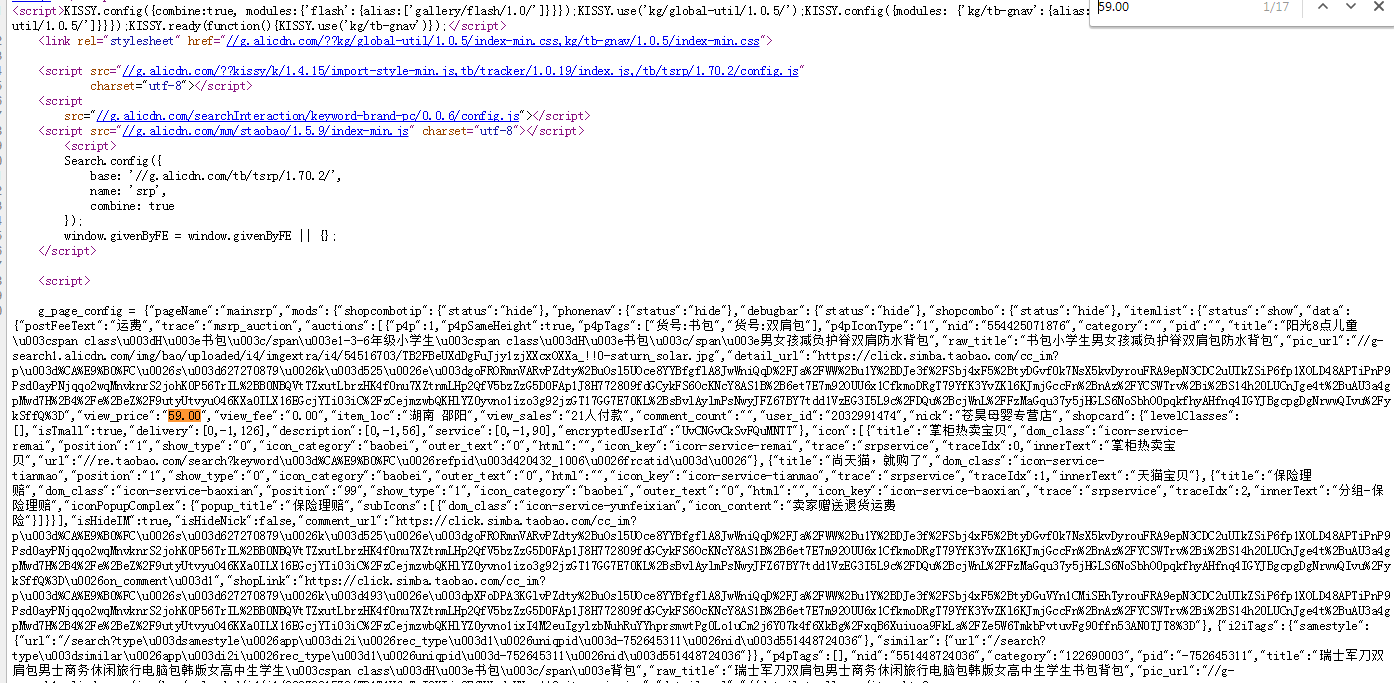
- 这个价格事实上是代码的一部分.看到前面有一个键,与价格相对应,这个键叫view_price,也就是说任何的商品是由view_price由键子对组成的,具体如下:

-
继续在源代码搜索第一个商品的名称"书包小学生男女孩减负护脊双肩包防水背包",前面有一个键,与商品名称相对应,这个键叫raw_title,具体如下:

- 淘宝商品查询信息,返回的价格,由view_price来标识.商品的名称由raw_title来标识.因此我们想获得这两个信息.在获得的文本中能够检索到view_price,raw_title,并将后续相关的内容提取出来.
-
从众多的文本从提取我们想要的信息,用正则表达式是非常合适的工具. 由于这段商品信息包含在html页面中,但是一种脚本语言体现.并不是完整的html页面表示,因此就未使用beautifulSoup库.换句话而言,当不使用beautifulSoup库去解析html代码,如果只通过搜索获得信息,那么这种方式就是最简单的.这里面只采用正则表达式的方式来实现对商品价格和商品名称的获取.具体如下:
首先在文本搜索过程中采用try,except结构,我们定义第一个变量叫plt,是一个列表类型.我们来看一下如下正则表达式的处理:plt=re.findall(r'"view_price":"[\d.]*"',html)
使用了findall函数,然后定义了正则表达式. "view_price",这个是代表首先检索view_price字符串,并且获得这个字符串后面的\d.形成的相关信息.我们知道商品的价格是由数字与小数点构成.通过这样的正则表达式,能够将商品价格与价格前面对应的view_price获得出来.获得所有的商品价格信息,保持在plt的列表中,即plt=re.findall(r'"view_price":"[\d.]*"',html)
同理,我们用同样的方式,获得商品的名称信息.保持在变量tlt中,这个正则表达式匹配"raw_title",采用了.?的形式,?表示最小匹配,匹配的是一个"raw_title"作为键,"作为值的一个键值对,它的最小匹配表明,值是取最后一个"为止的那一部分内容.这样可以很好的约束匹配的内容就是商品的本身的名字,具体如下:tlt=re.findall(r'"raw_title":".*?"',html)
通过这两行代码,我们可以获得商品全部的价格和名称信息.
-
现在我们将这些信息关联起来.保存到我们要输出的变量当中.这里我们用一个for循环来实现.
对plt信息做相关提取,去掉前面的view_price字段.只获得其中的价格部分.这里用了eval函数,将获得字符串最外层的"和'去掉.同时将split函数,用:来分割字符串,获得键值对后面的部分.price=eval(plt[i].split(":")[1])
同理,用a)的方法获得商品价格的名称.title=eval(tlt[i].split(":")[1])
将价格和名称写入我们将要输出的相关列表.ilt.append([price,title])
在这个parsePage()代码中,我们可能会遇到一些问题.首先使用findall方法来检索文本的时候.可能出现与我们要求不符的相关情况出现.出现之后,我们用eval()来去掉"会出现错误,而产生split不完整的情况.不管我们遇到什么样的情况.我们可以通过try和except来将所有的异常情况消灭掉.程序不会因为异常而退出.这样程序编写起来才更加稳定.才更加可靠.
这样一段函数就能解析返回信息的代码,并且里面的价格和名称.
def parsePage(ilt,html):
try:
plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price=eval(plt[i].split(":")[1])
title=eval(tlt[i].split(":")[1])
ilt.append([price,title])
except:
print("")
3.2.3printGoodsList()
- 设置打印模版,输出的内容以什么样的形式展示在屏幕上.我们定义这个模版叫tplt,用{}来定义槽函数,分别对第一个位置给定了长度为4,中间位置给定了长度为8,最后一个位置给定了长度为16.具体如下:
tplt = "{:4}\t{:8}\t{:16}"
- 下列我们给输出信息打印表头,表头分别表示序号,价格,商品名称,具体如下:
print(tplt.format("序号","价格","商品名称"))
- 然后我们定义一个计算器,count表明序号,后面两个是商品的价格和商品名称,如下:
count=0
for g in ilt:
count=count+1
print(tplt.format(count,g[0],g[1]))
- 重点理解parsePage()函数,尤其是正则表达式的使用.这个是代码最关键的部分
4.单元小结

- 正则表达式能找到要提取的任何关键信息,前提是要设计好正确的正则表达式.
-熟练运用正则表达式是提取信息的重要手段. - 在练习的过程中不断掌握这个方法.