(本人原创,谢绝转载)
咳咳。。豇豆哥昨天偷懒了,没给大家分享文章。。太累了
今天可就不能偷懒了。。继上一篇微信指数推出来,粉丝蹭蹭蹭的上涨,心中大喜(实则窃笑,不知道多少小白又要入坑啦)哈哈。。。
今天推出第三篇,百度指数。
感谢篇:
写这篇文章之前还是首先要感谢一些人:
@采铜谢谢老大哥给我提供的思路与提示
其次感谢@七夜的故事 谢谢老哥提供解决百度登录的思路。。思路清晰明了,一读就懂。
当然还有一个最需要感谢的是我的团队老哥@小庄 此老哥骨骼精奇,专治疑难杂症!!
好了 正式开始!
分析篇:
百度指数:百度指数搜索关键词:美女(百度:想看美女,没门!)
给我给我登录,不登录门都没有!!
好吧,开启踩坑之路!!
1、百度登录。。推荐大家上github上搜索baidulogin.py (也就是我要感谢的哪位老哥提供的登录思路。)登录可以解决了额。。
2、那么我们就开始疯狂的搜搜(什么美女啊,波多野结衣啊、日本女优啊。。。咳咳差不多了,一个一个的来不然受不了)查到了吧,哈哈这么简单。有日期,有数据。这不正是我想要的吗?(此时脑袋中疯狂的想到了用fiddler抓包,分析,请求,gameover)
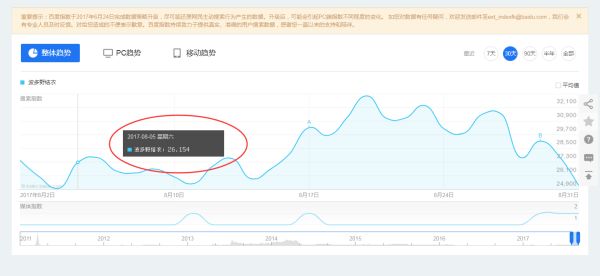
开启fiddler中。。。。
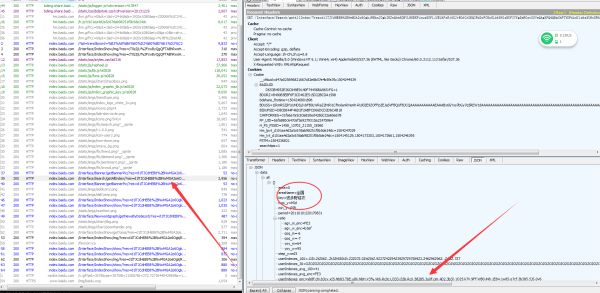
我找啊找。。,找到了,简单吧。。返回值还是json(我的最爱。)咦?不对吧,这个返回值怎么没有我需要的数据呢(坑来了。。。)
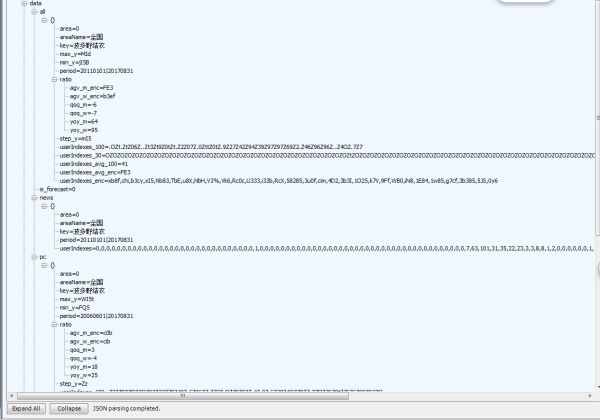
3、寻找我需要的数据,但是返回值是一串我看不懂的代码。等等。。我发现一个userIndexes_enc的值是不一样?这个是什么值呢,于是乎我在整个fiddler里面搜索关键字:b3ef,发现了
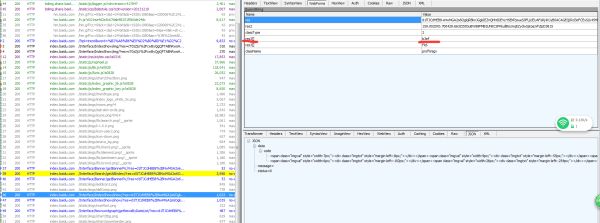
哈哈 有收获吧,在来看看这个这个网页的返回值是什么?感觉是个前端的代码。。看不懂(大坑)
好吧,可以先把userIndexes_enc的值拿下来,可能有用。
4、继续寻找参数来源:
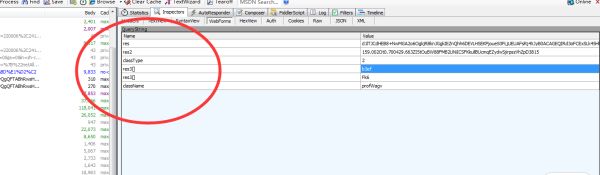
在寻找这些参数的来源时候,是通过web端的代码去解析出res和res2来获取的,这一段得感谢@采铜老哥的解答。我成功的拿到了res 和res2,我是用了execute_script这个函数去执行脚本后拿到的(坑)
5、这一段代码有啥用呢?我也不知道,主要是看不懂源代码,赶紧去补一些前端的知识(祭出我百度大法好,坑!)。。大概了解这段代码的意思后,俺们动手了。
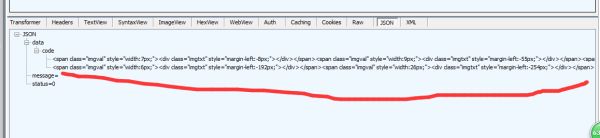
大概的意思是一些html下图片。(似乎懂了,百度这个大坑。居然用前端渲染的图片作为返回值!!!下次搜索放弃你了,还是我Google大法好!!!)
6、拿到图片后,当然得识别图片上的数字啦。。(悄悄告诉大家,又是一个大坑!),识别图片嘛,简单。。tesseract随便搞搞就出来了。。咳咳把图片拿下之后才发现是这样的。
蒙版识别(吐。。。。),不过坚持就是胜利,把数据从里面拿出来就行啦。。不难不难
于是乎,我开始了我编程的大坑路!!
编程篇:
1、百度登录这块直接参考别人得文章,耗费的时间实际上不长(乔布斯老人家说过嘛,greate artist steal。https://github.com/qiyeboy/baidulogin/blob/master/baidulogin.py
这个不错,逻辑清晰,代码干净,万能的github果然不辜负我的重望)
2、获取res、res2、res3[],实话说,获取res和res2是最难的,想过很多办法都没获取,在团队(奇男子的帮住下,两行代码解决问题,在下怎么一个服字了得!!!记住:他叫小庄!!!)res3[]的获取相对要简单的多,传入一个时间参数,res和res2传入进去后就能获得!
3、请求数据,获得html的图片,并采用切割拼接的方法获得数据图片(老板,上菜):
拼接渲染之后的图片。
4、图片识别,这块网上教程太多,我就不多讲!
还是给大家贴一点福利吧(核心代码):
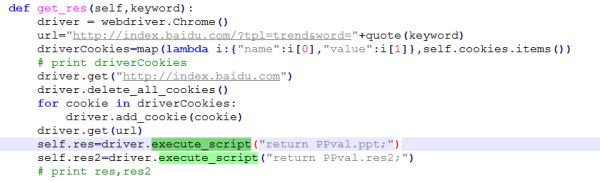
ok,编程篇讲完了,是不是感觉一脸闷逼。。
咦好像少了一点啥:
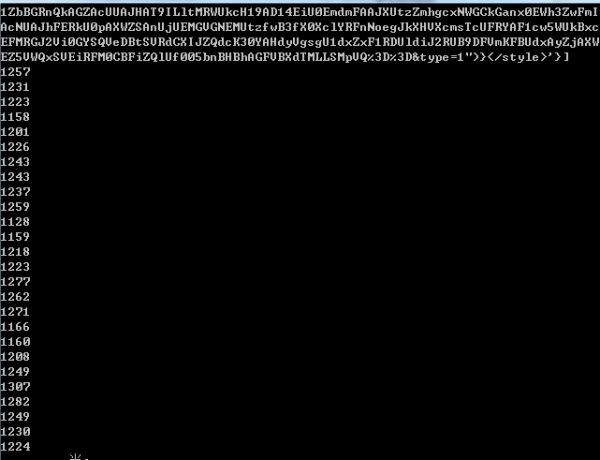
对对对!!!结果图:
第一章是win7下直接采集的数据:
第二章是通过接口调用获得的数据:
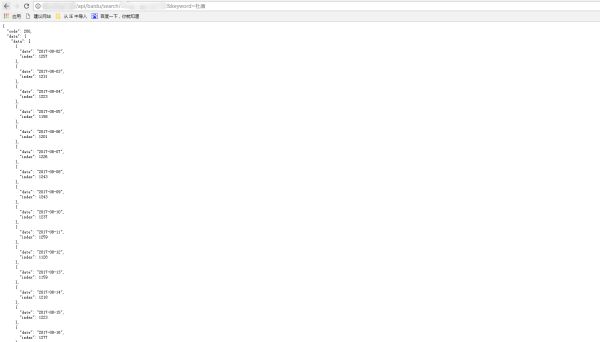
数据截图不完整,可以对比一下,接口是调通了的。。
总结篇:
1、分析很关键,分析通了写代码就很简单。
2、从根源找起,找到需要的参数,一步一步的走过来(实话说:是不是有点像高中数学中的证明题!!特别是反证法。ps:俺的最爱)
3、用到的技术:Python执行js代码的库,selenium+phantomjs获取cookies,图片的切割和拼接,图像识别(像素比对)。
4、在图像识别这块可以使用神经网络学习,不过俺不会,继续加强学习!本人技术比较low,还有很多不懂的地方,知乎中的各位大神小神,文章有不妥的地方欢迎指出,也欢迎粉我,私信骚扰俺。