一、目前的学习
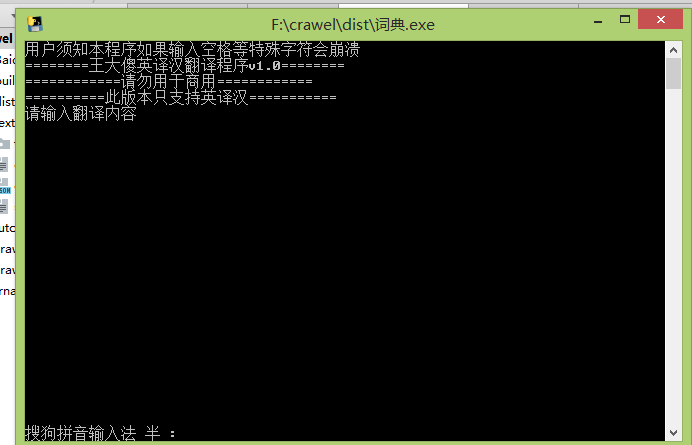
最近 ,一直在看python 基础知识,爬虫这面也只是偶尔写几下,写了好多邪恶的小爬虫,最近最得意的作品就是,爬取某宝某店家某个商品的买家评论照片那个爬虫太邪恶了,我就自己用了今天写一个属于自己的英译汉词典
二、谈谈思路
其实原理很简单,这个可以说是我写过的最简单的爬虫了,我去百度翻译的网页,用了一下他的接口然后代码就完成了~
三、我们还差什么
老规矩需要python3.5、requests库、json模块、pyinstaller模块,现在恭喜你了你要有一个属于自己的英译汉词典了,兴奋么~
四、完事具备开始爬虫
我们的目标网站:
http://fanyi.baidu.com/?aldtype=16047#auto/zh
其实百度真的特别人性化,你只要花49元就可以用他的接口,今天这个爬虫如果商用请自行购买百度的接口,如果自己用也请不要随便传播
接口购买网址:
http://api.fanyi.baidu.com/api/trans/product/index

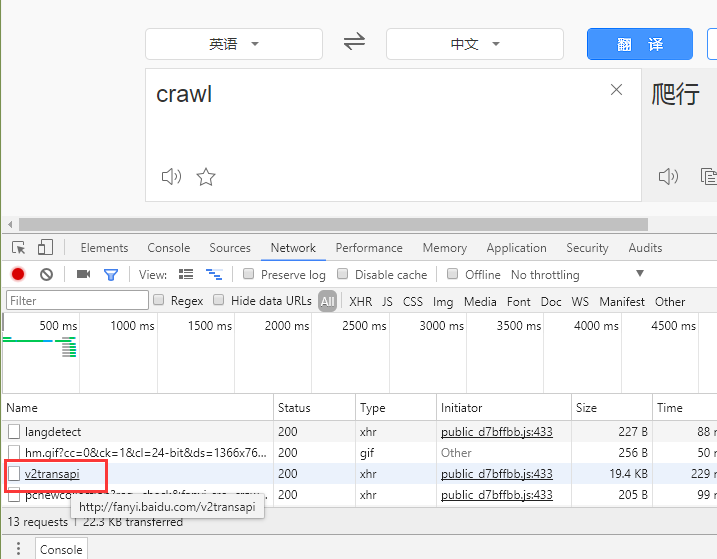
第一步,既然我们不打算买这个接口,那我们就来解析一下页面,我在网页做了下尝试输入了crawl,观察网页变化,找到一个神奇网址
打开看看都有什么:
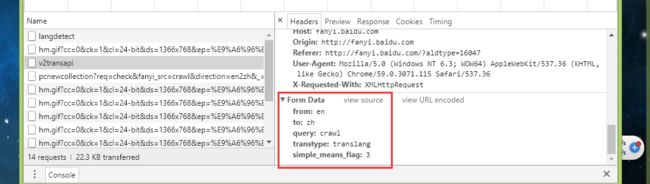
我看到一个query: 带着我的crawl。那现在我可以确定了他就是我要找的,开始我们代码的第一步发送请求,解析参数
import requests
from requests.exceptions import RequestException
import json
def get_api(query):
#最后整理了下其实就这三个参数最重要
try:
data = {
'from':'en',
'to': 'zh',
'query': query
}
#页面用post 请求我们也跟着用
r =requests.post('https://fanyi.baidu.com/v2transapi',data = data)
#判断一下网页返回的状态码
if r.status_code ==200:
r.encoding = 'utf-8'
return r.text
else:
return '请检查网络'
except RequestException:
return '连接异常'
我们提取了三个比较重要的参数,分别是from指的是翻译内容语言,to要被翻译成的语言,query要翻译的内容,做了一下异常处理,主要是为了预防连接时候出现的异常
def EN_translate(html):
concent_json = json.loads(html)
if 'trans_result' in concent_json.keys():
if 'dst' in concent_json['trans_result']['data'][0].keys():
print(concent_json['trans_result']['data'][0]['dst'])
else:
print("暂时没有找到对应翻译")
print("请输入正确内容")
上面的代码我们获取接口返回的json,然后处理一下,在处理的时候我发现如果输入空格或者是不存在的单词会报错,我在这就做了处理,首先判断字典中必须有trans_result字段,其次有dst,完美解决问题
现在,我们的字典完成了,我们这就结束么,来让我们看看百度这个借口还有点啥,毕竟免费的东西不用白不用。
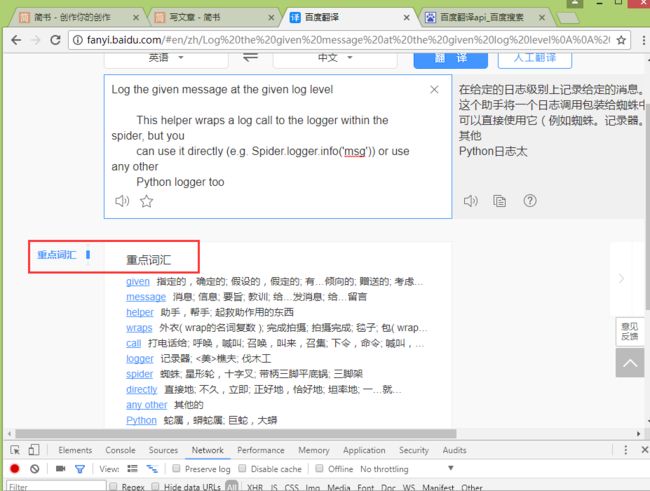
我们接着来把这个重点词汇也解析出来
这是我的第一种解析的方法:
def keywords(concent):
keywordss=[]
if 'trans_result' in concent.keys():
if 'keywords' in concent['trans_result'].keys() :
for means in concent['trans_result']['keywords']:
keywordss.append({'英文单词':means['word'],'中文翻译':means['means']})
else:
keywordss.append({'英文单词': "未查到",'中文翻译': '未查到'})
return keywordss
这是第二种:
def keywords(concent):
if 'keywords' in concent['trans_result'].keys() :
for means in concent['trans_result']['keywords']:
yield {
'英文单词':means['word'],
'中文翻译': means['means']
}
yield {
'英文单词':'未查到',
'中文翻译': '重点单词'
}
最后合成的时候我们以第一种为讲解合成:
def main():
while True:
query = input("请输入英文:").strip()
html = get_api(query)
concent = EN_translate(html)
print('重点单词')
for keyword in keywords(concent):
print(keyword["英文单词"],keyword['中文翻译'])
con = input("0.退出 其他键继续")
try:
if con.isdigit():
con = int(con)
if con == 0:
break
except:
main()
if __name__ == '__main__':
main()
这里我做了递归处理,如果别人输入非0默认继续,就重新调用主函数,递归的活用
属于我们自己的英译汉词典完成,你可以用pyinstaller库生成一个exe文件 自己在Windows平台使用~下一期的爬虫案例我会接着上篇文章爬取大学排行继续