在电商的搜索模块中,需要支持全量索引和增量索引。全量搜索是指根据数据库的数据重建索引里的数据,一般耗时耗性能,可能一天甚至几天重建一次;而增量索引是根据业务库数据的变化,准实时地更新该部分内容到索引中。对于增量索引而言,就需要能够监听业务的表数据变化,阿里开源的Canal组件便是一个不错的选择。
什么是Mysql的二进制日志(binlog)?
- binlog记录了数据库变更的事件(如create table、update records)。由一组二进制日志文件(如log-bin.000010)和一个索引文件(如log-bin.index)组成。
- binlog有两个重要用途:主从复制和数据恢复;
- 通过log-bin参数开启binlog,通过binlog-do-db和binlog-ignore-db参数配置记录和忽略的schema;
- 使用RESET MASTER命令可以清除已记录的binlog;
- 使用Mysql内置的mysqlbinlog工具可以查看和操作binlog;
- binlog有三种格式:基于语句的、基于行数据和混合模式;
- 关于记录binlog的时机,官网上如是说:
Binary logging is done immediately after a statement or transaction completes but before any locks are released or any commit is done. This ensures that the log is logged in commit order. Within an uncommitted transaction, all updates (UPDATE, DELETE, or INSERT) that change transactional tables such as InnoDB tables are cached until a COMMIT statement is received by the server. At that point, mysqld writes the entire transaction to the binary log before the COMMIT is executed.
- binlog的Event结构(目前主要用的是v4版本),下表中的字段名后的两个用冒号分隔的是offset和length。
+=====================================+
| event | timestamp 0 : 4 |
| header +----------------------------+
| | type_code 4 : 1 | = FORMAT_DESCRIPTION_EVENT = 15
| +----------------------------+
| | server_id 5 : 4 |
| +----------------------------+
| | event_length 9 : 4 | >= 91
| +----------------------------+
| | next_position 13 : 4 |
| +----------------------------+
| | flags 17 : 2 |
+=====================================+
| event | binlog_version 19 : 2 | = 4
| data +----------------------------+
| | server_version 21 : 50 |
| +----------------------------+
| | create_timestamp 71 : 4 |
| +----------------------------+
| | header_length 75 : 1 |
| +----------------------------+
| | post-header 76 : n | = array of n bytes, one byte per event
| | lengths for all | type that the server knows about
| | event types |
+=====================================+
什么是Canal?
Canal是由Alibaba开源的一个基于binlog的增量日志组件,其核心原理是Canal伪装成Mysql的slave,发送dump协议获取binlog,解析并存储起来给客户端消费。

Canal的核心架构
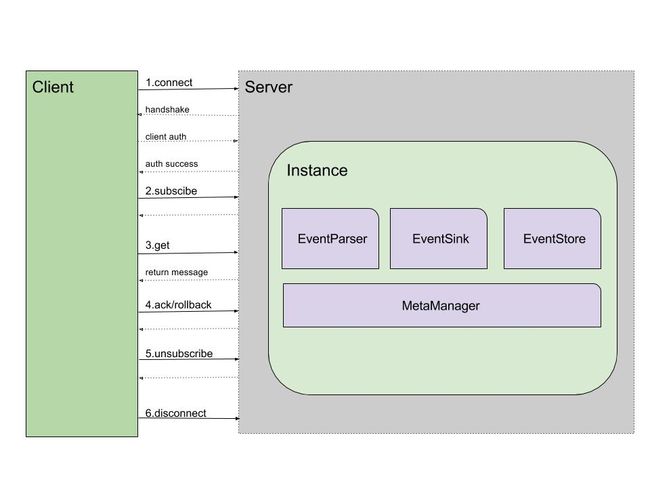
整体架构
- Canal是一个CS的架构,Client和Server基于netty进行通信,采用的protobuf协议;
- Server包含了一个或多个Instance(一个Instance可以想象为监听一个数据库的binlog),Server将Client的请求转至具体的Instance处理;
- 一个Instance又包含了EventParser、EventSink和EventStore三个核心部件。EventParser负责获取Mysql的binlog并进行解析,然后将解析的Event交给EventSink进行过滤和路由处理,处理之后的数据交由EventStore进行存储。而Server转过来的请求最终就会获取或者操作EventStore上存储的数据。
EventParser设计
处理流程
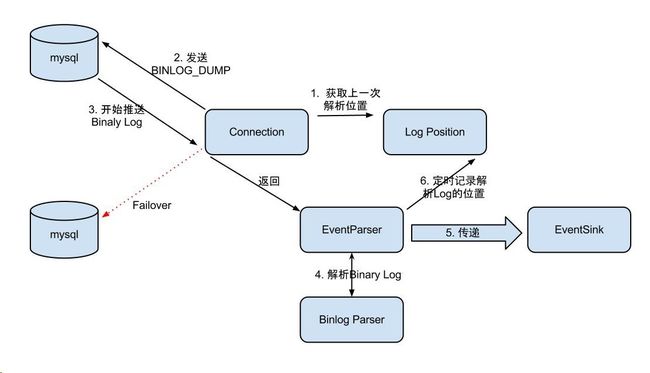
- MysqlConnection为EventParser的核心组件,它通过dump协议不断地从Mysql获取binlog,并交给EventParser处理;
- 如果配置了Mysql的配置了standby,MysqlConnection支持失效转移,从standby的数据库获取binlog;
- MysqlEventParser为核心组件,接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息;
- MysqlEventParser传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功;
- 存储成功后,由CanalLogPositionManager定时记录Binaly Log位置,其持久化策略支持内存的、文件的、ZK的以及混合式的;
代码设计
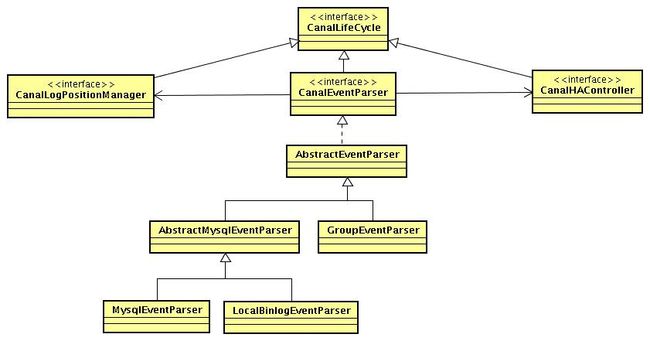
核心源码解析
以下核心源码为AbstractEventParser类的start方法,具体的执行流程见代码注释:
public void start() {
super.start();
MDC.put("destination", destination);
// 配置transaction buffer
// 初始化缓冲队列
transactionBuffer.setBufferSize(transactionSize);// 设置buffer大小
transactionBuffer.start();
// 构造bin log parser
binlogParser = buildParser();// 初始化一下BinLogParser
binlogParser.start();
// 启动工作线程
parseThread = new Thread(new Runnable() {
public void run() {
MDC.put("destination", String.valueOf(destination));
ErosaConnection erosaConnection = null;
while (running) {
try {
// 开始执行replication
// 1. 构造Erosa连接
erosaConnection = buildErosaConnection();
// 2. 启动一个心跳线程
startHeartBeat(erosaConnection);
// 3. 执行dump前的准备工作
preDump(erosaConnection);
erosaConnection.connect();// 链接
// 4. 获取最后的位置信息
final EntryPosition startPosition = findStartPosition(erosaConnection);
if (startPosition == null) {
throw new CanalParseException("can't find start position for " + destination);
}
logger.info("find start position : {}", startPosition.toString());
// 重新链接,因为在找position过程中可能有状态,需要断开后重建
erosaConnection.reconnect();
final SinkFunction sinkHandler = new SinkFunction() {
private LogPosition lastPosition;
public boolean sink(EVENT event) {
try {
CanalEntry.Entry entry = parseAndProfilingIfNecessary(event);
if (!running) {
return false;
}
if (entry != null) {
exception = null; // 有正常数据流过,清空exception
transactionBuffer.add(entry);
// 记录一下对应的positions
this.lastPosition = buildLastPosition(entry);
// 记录一下最后一次有数据的时间
lastEntryTime = System.currentTimeMillis();
}
return running;
} catch (TableIdNotFoundException e) {
throw e;
} catch (Exception e) {
// 记录一下,出错的位点信息
processError(e,
this.lastPosition,
startPosition.getJournalName(),
startPosition.getPosition());
throw new CanalParseException(e); // 继续抛出异常,让上层统一感知
}
}
};
// 4. 开始dump数据
if (StringUtils.isEmpty(startPosition.getJournalName()) && startPosition.getTimestamp() != null) {
erosaConnection.dump(startPosition.getTimestamp(), sinkHandler);
} else {
erosaConnection.dump(startPosition.getJournalName(),
startPosition.getPosition(),
sinkHandler);
}
} catch (TableIdNotFoundException e) {
exception = e;
// 特殊处理TableIdNotFound异常,出现这样的异常,一种可能就是起始的position是一个事务当中,导致tablemap
// Event时间没解析过
needTransactionPosition.compareAndSet(false, true);
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
} catch (Throwable e) {
exception = e;
if (!running) {
if (!(e instanceof java.nio.channels.ClosedByInterruptException || e.getCause() instanceof java.nio.channels.ClosedByInterruptException)) {
throw new CanalParseException(String.format("dump address %s has an error, retrying. ",
runningInfo.getAddress().toString()), e);
}
} else {
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
sendAlarm(destination, ExceptionUtils.getFullStackTrace(e));
}
} finally {
// 关闭一下链接
afterDump(erosaConnection);
try {
if (erosaConnection != null) {
erosaConnection.disconnect();
}
} catch (IOException e1) {
if (!running) {
throw new CanalParseException(String.format("disconnect address %s has an error, retrying. ",
runningInfo.getAddress().toString()),
e1);
} else {
logger.error("disconnect address {} has an error, retrying., caused by ",
runningInfo.getAddress().toString(),
e1);
}
}
}
// 出异常了,退出sink消费,释放一下状态
eventSink.interrupt();
transactionBuffer.reset();// 重置一下缓冲队列,重新记录数据
binlogParser.reset();// 重新置位
if (running) {
// sleep一段时间再进行重试
try {
Thread.sleep(10000 + RandomUtils.nextInt(10000));
} catch (InterruptedException e) {
}
}
}
MDC.remove("destination");
}
});
parseThread.setUncaughtExceptionHandler(handler);
parseThread.setName(String.format("destination = %s , address = %s , EventParser",
destination,
runningInfo == null ? null : runningInfo.getAddress().toString()));
parseThread.start();
}
EventSink设计
处理流程

- 数据过滤:支持通配符的过滤模式,表名、字段内容等;
- 数据路由/分发:解决1:n (1个parser对应多个store的模式);
- 数据归并:解决n:1 (多个parser对应1个store);
- 数据加工:在进入store之前进行额外的处理,比如join;
代码设计
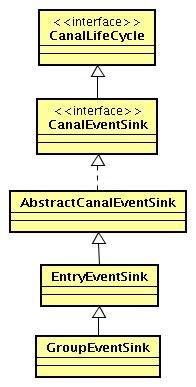
核心源码解析
以下核心代码为EntryEventSink类的sinkData方法:
private boolean sinkData(List entrys, InetSocketAddress remoteAddress) throws InterruptedException {
boolean hasRowData = false;
boolean hasHeartBeat = false;
List events = new ArrayList();
for (CanalEntry.Entry entry : entrys) {
Event event = new Event(new LogIdentity(remoteAddress, -1L), entry);
if (!doFilter(event)) {
continue;
}
events.add(event);
hasRowData |= (entry.getEntryType() == EntryType.ROWDATA);
hasHeartBeat |= (entry.getEntryType() == EntryType.HEARTBEAT);
}
if (hasRowData) {
// 存在row记录
return doSink(events);
} else if (hasHeartBeat) {
// 存在heartbeat记录,直接跳给后续处理
return doSink(events);
} else {
// 需要过滤的数据
if (filterEmtryTransactionEntry && !CollectionUtils.isEmpty(events)) {
long currentTimestamp = events.get(0).getEntry().getHeader().getExecuteTime();
// 基于一定的策略控制,放过空的事务头和尾,便于及时更新数据库位点,表明工作正常
if (Math.abs(currentTimestamp - lastEmptyTransactionTimestamp) > emptyTransactionInterval
|| lastEmptyTransactionCount.incrementAndGet() > emptyTransctionThresold) {
lastEmptyTransactionCount.set(0L);
lastEmptyTransactionTimestamp = currentTimestamp;
return doSink(events);
}
}
// 直接返回true,忽略空的事务头和尾
return true;
}
}
EventStore设计
处理流程
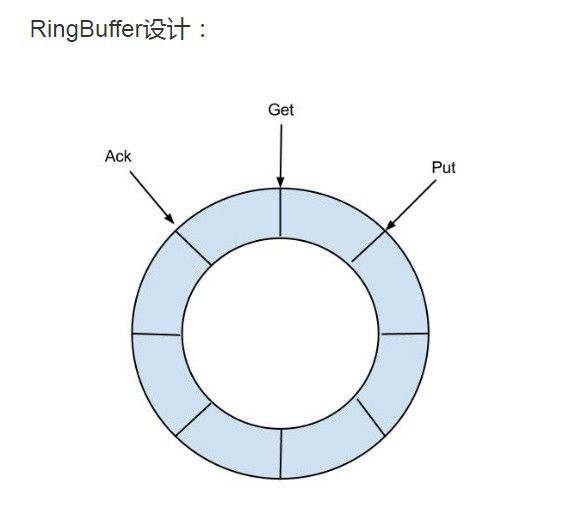
- EventStore借鉴了Disruptor的RingBuffer的实现思路,定义了3个cursor:Put(Sink模块进行数据存储的最后一次写入位置)、Get(数据订阅获取的最后一次提取位置)、Ack(数据消费成功的最后一次消费位置);
- 目前仅实现了Memory内存模式,暂不支持文件等方式存储;
- 这里Ack的设计主要是为了确保消息被客户端正常消费,当客户端调用rollback时,对应的Get会重置到Ack的位置;
代码设计
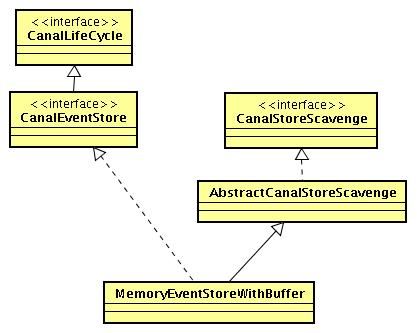
核心源码解析
以下核心代码为MemoryEventStoreWithBuffer类的几个重要操作方法:
/**
* 执行具体的put操作
*/
private void doPut(List data) {
long current = putSequence.get();
long end = current + data.size();
// 先写数据,再更新对应的cursor,并发度高的情况,putSequence会被get请求可见,拿出了ringbuffer中的老的Entry值
for (long next = current + 1; next <= end; next++) {
entries[getIndex(next)] = data.get((int) (next - current - 1));
}
putSequence.set(end);
// 记录一下gets memsize信息,方便快速检索
if (batchMode.isMemSize()) {
long size = 0;
for (Event event : data) {
size += calculateSize(event);
}
putMemSize.getAndAdd(size);
}
// tell other threads that store is not empty
notEmpty.signal();
}
private Events doGet(Position start, int batchSize) throws CanalStoreException {
LogPosition startPosition = (LogPosition) start;
long current = getSequence.get();
long maxAbleSequence = putSequence.get();
long next = current;
long end = current;
// 如果startPosition为null,说明是第一次,默认+1处理
if (startPosition == null || !startPosition.getPostion().isIncluded()) { // 第一次订阅之后,需要包含一下start位置,防止丢失第一条记录
next = next + 1;
}
if (current >= maxAbleSequence) {
return new Events();
}
Events result = new Events();
List entrys = result.getEvents();
long memsize = 0;
if (batchMode.isItemSize()) {
end = (next + batchSize - 1) < maxAbleSequence ? (next + batchSize - 1) : maxAbleSequence;
// 提取数据并返回
for (; next <= end; next++) {
Event event = entries[getIndex(next)];
if (ddlIsolation && isDdl(event.getEntry().getHeader().getEventType())) {
// 如果是ddl隔离,直接返回
if (entrys.size() == 0) {
entrys.add(event);// 如果没有DML事件,加入当前的DDL事件
end = next; // 更新end为当前
} else {
// 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
end = next - 1; // next-1一定大于current,不需要判断
}
break;
} else {
entrys.add(event);
}
}
} else {
long maxMemSize = batchSize * bufferMemUnit;
for (; memsize <= maxMemSize && next <= maxAbleSequence; next++) {
// 永远保证可以取出第一条的记录,避免死锁
Event event = entries[getIndex(next)];
if (ddlIsolation && isDdl(event.getEntry().getHeader().getEventType())) {
// 如果是ddl隔离,直接返回
if (entrys.size() == 0) {
entrys.add(event);// 如果没有DML事件,加入当前的DDL事件
end = next; // 更新end为当前
} else {
// 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
end = next - 1; // next-1一定大于current,不需要判断
}
break;
} else {
entrys.add(event);
memsize += calculateSize(event);
end = next;// 记录end位点
}
}
}
PositionRange range = new PositionRange();
result.setPositionRange(range);
range.setStart(CanalEventUtils.createPosition(entrys.get(0)));
range.setEnd(CanalEventUtils.createPosition(entrys.get(result.getEvents().size() - 1)));
// 记录一下是否存在可以被ack的点
for (int i = entrys.size() - 1; i >= 0; i--) {
Event event = entrys.get(i);
if (CanalEntry.EntryType.TRANSACTIONBEGIN == event.getEntry().getEntryType()
|| CanalEntry.EntryType.TRANSACTIONEND == event.getEntry().getEntryType()
|| isDdl(event.getEntry().getHeader().getEventType())) {
// 将事务头/尾设置可被为ack的点
range.setAck(CanalEventUtils.createPosition(event));
break;
}
}
if (getSequence.compareAndSet(current, end)) {
getMemSize.addAndGet(memsize);
notFull.signal();
return result;
} else {
return new Events();
}
}
public void rollback() throws CanalStoreException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
getSequence.set(ackSequence.get());
getMemSize.set(ackMemSize.get());
} finally {
lock.unlock();
}
}
public void ack(Position position) throws CanalStoreException {
cleanUntil(position);
}
public void cleanUntil(Position position) throws CanalStoreException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
long sequence = ackSequence.get();
long maxSequence = getSequence.get();
boolean hasMatch = false;
long memsize = 0;
for (long next = sequence + 1; next <= maxSequence; next++) {
Event event = entries[getIndex(next)];
memsize += calculateSize(event);
boolean match = CanalEventUtils.checkPosition(event, (LogPosition) position);
if (match) {// 找到对应的position,更新ack seq
hasMatch = true;
if (batchMode.isMemSize()) {
ackMemSize.addAndGet(memsize);
// 尝试清空buffer中的内存,将ack之前的内存全部释放掉
for (long index = sequence + 1; index < next; index++) {
entries[getIndex(index)] = null;// 设置为null
}
}
if (ackSequence.compareAndSet(sequence, next)) {// 避免并发ack
notFull.signal();
return;
}
}
}
if (!hasMatch) {// 找不到对应需要ack的position
throw new CanalStoreException("no match ack position" + position.toString());
}
} finally {
lock.unlock();
}
}
Instance设计
代码设计
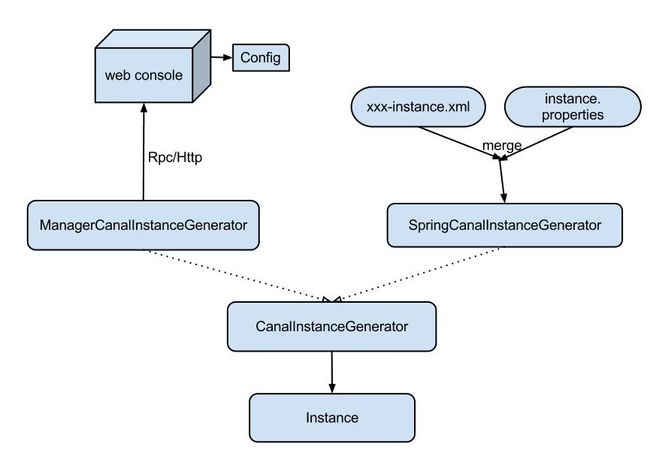
核心源码解析
CanalInstance的设计比较简单,主要是包含了上述三个组件:
/**
* 代表单个canal实例,比如一个destination会独立一个实例
*/
public interface CanalInstance extends CanalLifeCycle {
String getDestination();
CanalEventParser getEventParser();
CanalEventSink getEventSink();
CanalEventStore getEventStore();
CanalMetaManager getMetaManager();
CanalAlarmHandler getAlarmHandler();
/**
* 客户端发生订阅/取消订阅行为
*/
boolean subscribeChange(ClientIdentity identity);
}
Servers设计
代码设计
netty
Canal Server是基于netty和protobuf实现的,netty是一个很流行的nio框架,其官网描述为:
Netty is a NIO client server framework which enables quick and easy development of network applications such as protocol servers and clients. It greatly simplifies and streamlines network programming such as TCP and UDP socket server.

- client 传递过来的消息会有个Channel对象接收,然后产生一个Channel事件,并发送到ChannelPipeline。
- ChannelPipeline会选择一个ChannelHandler进行处理。
- ChannelHandler处理之后,可能会产生新的ChannelEvent,并流转到下一个ChannelHandler。
protobuf
protobuf是Google开发的一种数据描述语言语言,能够将结构化的数据序列化,可用于数据存储,通信协议等方面,官方版本支持C++、Java、Python,社区版本支持更多语言。相对于JSON和XML具有以下优点:
- 简洁;
- 体积小:消息大小只需要XML的1/10 ~ 1/3;
- 速度快:解析速度比XML快20 ~ 100倍;
- 使用Protobuf的编译器,可以生成更容易在编程中使用的数据访问代码;
- 更好的兼容性,Protobuf设计的一个原则就是要能够很好的支持向下或向上兼容;
Canal主要包含以下两个protobuf定义:CanalProtocol.proto 和 EntryProtocol.proto
核心源码解析
以下核心源码为CanalServerWithNetty类的start方法,其中piplines包含了四个Handler,最主要的Handler为SessionHandler。
public void start() {
super.start();
if (!embeddedServer.isStart()) {
embeddedServer.start();
}
this.bootstrap = new ServerBootstrap(new NioServerSocketChannelFactory(Executors.newCachedThreadPool(),
Executors.newCachedThreadPool()));
// 构造对应的pipeline
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() throws Exception {
ChannelPipeline pipelines = Channels.pipeline();
pipelines.addLast(FixedHeaderFrameDecoder.class.getName(), new FixedHeaderFrameDecoder());
pipelines.addLast(HandshakeInitializationHandler.class.getName(), new HandshakeInitializationHandler());
pipelines.addLast(ClientAuthenticationHandler.class.getName(),
new ClientAuthenticationHandler(embeddedServer));
SessionHandler sessionHandler = new SessionHandler(embeddedServer);
pipelines.addLast(SessionHandler.class.getName(), sessionHandler);
return pipelines;
}
});
// 启动
if (StringUtils.isNotEmpty(ip)) {
this.serverChannel = bootstrap.bind(new InetSocketAddress(this.ip, this.port));
} else {
this.serverChannel = bootstrap.bind(new InetSocketAddress(this.port));
}
}
Client设计
核心源码解析
Canal Client支持对Server集群的处理,其是基于zk来实现的。对于Client最主要是负责封装请求发送给Server处理,以下为SimpleCanalConnector类的getWithoutAck方法:
public Message getWithoutAck(int batchSize, Long timeout, TimeUnit unit) throws CanalClientException {
waitClientRunning();
try {
int size = (batchSize <= 0) ? 1000 : batchSize;
long time = (timeout == null || timeout < 0) ? -1 : timeout; // -1代表不做timeout控制
if (unit == null) {
unit = TimeUnit.MILLISECONDS;
}
writeWithHeader(channel,
Packet.newBuilder()
.setType(PacketType.GET)
.setBody(Get.newBuilder()
.setAutoAck(false)
.setDestination(clientIdentity.getDestination())
.setClientId(String.valueOf(clientIdentity.getClientId()))
.setFetchSize(size)
.setTimeout(time)
.setUnit(unit.ordinal())
.build()
.toByteString())
.build()
.toByteArray());
return receiveMessages();
} catch (IOException e) {
throw new CanalClientException(e);
}
}
Consumer样例代码
我们的Consumer代码通过Client就可以向Canal Server获取binlog的Event进行增量消费了,以下是一个样例代码:
public void startClient() {
for (ZkClusterCanalConfig instance : canalInstances) {
threadPool.execute(() -> {
Thread.currentThread().setName(Thread.currentThread().getName() + "-" + instance.getDestination());
initConnector(instance);
while (!threadPool.isShutdown() && !threadPool.isTerminated()) {
try {
handleCanalMessage(canalInstConnectors.get(instance.getDestination()), instance);
} catch (CanalClientException e) {
reConnectCanal(instance);
}
catch (Throwable e) {
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
}
});
}
}
private void initConnector(ZkClusterCanalConfig instance) {
CanalConnector canalConnector = CanalConnectors.newClusterConnector(instance.getZkAddress(), instance.getDestination(), instance.getUsername(), instance.getPassword());
canalConnector.connect();
canalConnector.subscribe(instance.getSubscribeChannel());
canalConnector.rollback();
canalInstConnectors.put(instance.getDestination(), canalConnector);
}
public void handleCanalMessage(CanalConnector connector, CanalConfig config) throws CanalClientException{
long batchId = 0;
try {
Message message = connector.getWithoutAck(config.getFetchSize(), 10L, TimeUnit.SECONDS);
batchId = message.getId();
int size = message.getEntries().size();
if (batchId >= 0 && size > 0) {
List entryList = message.getEntries();
for (Entry entry : entryList) {
handleEntry(entry);
}
}
}
catch (CanalClientException e) {
throw e;
}
catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
connector.ack(batchId);
}
}
参考资源
- MySQL 5.7 Reference Manual -- The Binary Log
- MySQL Internals Manual -- The Binary Log
- MySQL 5.7 Reference Manual -- mysqlbinlog Utility for Processing Binary Log Files
- alibaba/canal -- 阿里巴巴mysql数据库binlog的增量订阅&消费组件
