本文来自OPPO互联网技术团队,是《剖析Spark数据分区》系列文章的第二篇,将重点分析Spark RDD的数据分区。该系列共分3篇文章,欢迎持续关注。
- 第一篇:主要分析Hadoop中的分片;
- 第二篇:主要分析Spark RDD的分区;
- 第三篇:主要分析Spark Streaming,TiSpark中的数据分区;
转载请注名作者,同时欢迎关注OPPO互联网技术团队的公众号:OPPO_tech,一同分享OPPO前沿互联网技术及活动。
Spark
我们以Spark on Yarn为例阐述Spark运行原理。
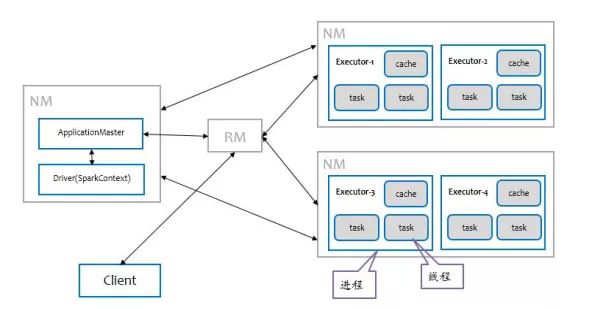
任务运行步骤
1.客户端提交Application到RM,RM判断集群资源是否满足需求 ;
2.RM在集群中选择一台NodeManager启动Application Master(cluster模式);
3.Driver在AM所在的NodeManager节点启动进程;
4.AM向ResourceManager申请资源,并在每台NodeManager上启动相应的executors;
5.Driver开始进行任务调度,通过Transaction操作形成了RDD血缘关系图,即DAG图,最后通过Action的调用,触发Job并调度执行;
6.DAGScheduler负责Stage级的调度,主要是将DAG切分成若干个Stages,并将每个Stage打包成Taskset交给TaskScheduler调度;
7.TaskScheduler负责Task级的调度,将DAGScheduler给过来的Taskset按照指定的调度策略分发到Executor上执行;
Spark RDD
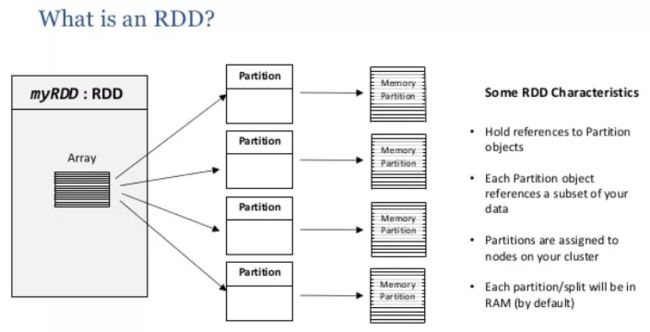
RDD 弹性分布式数据集,RDD包含5个特征
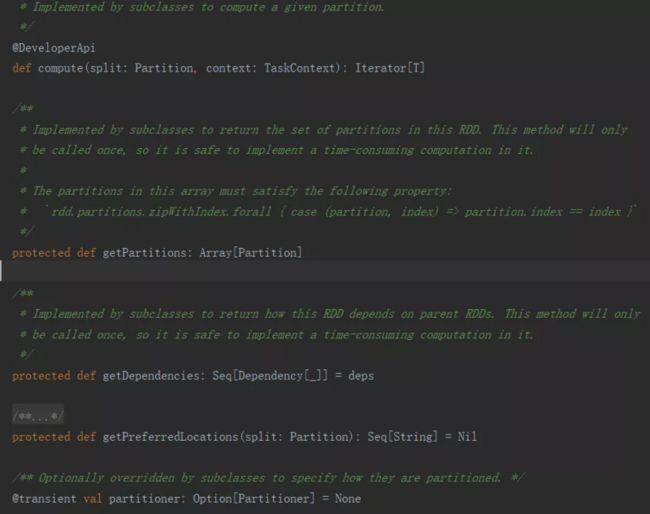
1.Compute:
RDD在任务计算时是以分区为单位的,通过Compute计算得到每一个分片的数据,不同的RDD子类可以实现自己的compute方法;
2.getPartitions:
计算获取所有分区列表,RDD是一个分区的集合,一个RDD有一个或者多个分区,分区的数量决定了Spark任务的并行度;
3.getDependencies:
获取RDD的依赖,每个RDD都有依赖关系(源RDD的依赖关系为空),这些依赖关系成为lineage;
4.getPreferredLocations:
对其他RDD的依赖列表,Spark在进行任务调度时,会尝试将任务分配到数据所在的机器上,从而避免了机器间的数据传输,RDD获取优先位置的方法为getPreferredLocations,一般只有涉及到从外部存储结构中读取数据时才会有优先位置,比如HadoopRDD, ShuffleRDD;
5.Partitioner:
决定数据分到哪个Partition,对于非key-value类型的RDD,Partitioner为None, 对应key-value类型的RDD,Partitioner默认为HashPartitioner。在进行shuffle操作时,如reduceByKey, sortByKey,Partitioner决定了父RDD shuffle的输出时对应的分区中的数据是如何进行map的;
前2个函数是所有RDD必须的,后三个可选,所有的RDD均继承了该接口。
Spark Partition
由于RDD的数据量很大,因此为了计算方便,需要将RDD进行切分并存储在各个节点的分区当中,从而当我们对RDD进行各种计算操作时,实际上是对每个分区中的数据进行并行的操作。
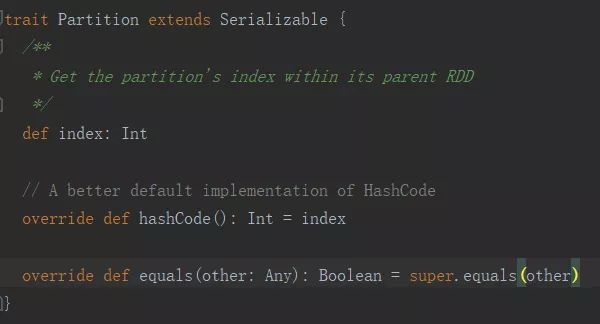
也就是一份待处理的原始数据会被按照相应的逻辑切分成多分,每份数据对应RDD的一个Partition,partition的数量决定了task的数量,影响程序的并行度,Partition是伴生的,也就是说每一种RDD都有其对应的Partition实现。
HadoopRDD
Spark经常需要从hdfs读取文件生成RDD,然后进行计算分析。这种从hdfs读取文件生成的RDD就是HadoopRDD。
HadoopRDD主要重写了RDD接口的三个方法:
- override def getPartitions: Array[Partition]
- override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)]
- override def getPreferredLocations(split:Partition): Seq[String]
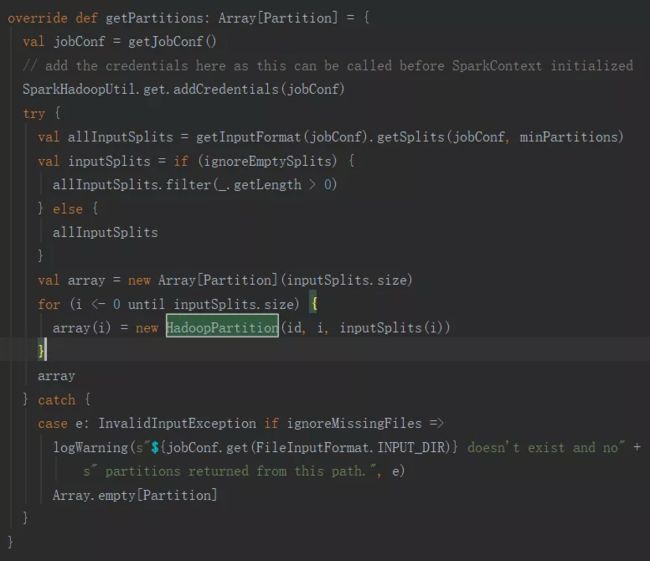
决定分区数量的逻辑在getPartitions中,实际上调用的是InputFormat.getSplits,
InputFormat是一个接口:org.apache.hadoop.mapred.InputFormat,其中getInputSplit就是 图 – 7 中所展示的。
从源码分析可知,在HadoopRDD这种场景下,RDD的分区数在生成RDD之前就已经决定了,是被HADOOP的参数所决定的,我们可以通过调整:
spark.hadoop.mapreduce.input.fileinputformat.split.minsize;
spark.hadoop.mapreduce.input.fileinputformat.split.maxsize;
的大小来调整HadoopRDD的分区数量。
Spark SQL中的分区
Spark SQL 最终将SQL 语句经过逻辑算子树转换成物理算子树。
在物理算子树中,叶子类型的SparkPlan 节点负责从无到有的创建RDD ,每个非叶子类型的SparkPlan 节点等价于在RDD 上进行一次Transformation ,即通过调用execute()函数转换成新的RDD ,最终执行collect()操作触发计算,返回结果给用户。
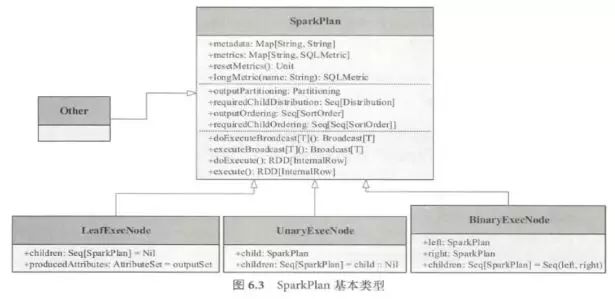
重点分析一下叶子节点:
在Spark SQL 中,LeafExecNode 类型的SparkPlan 负责对初始RDD 的创建。
HiveTableScanExec 会根据Hive数据表存储的HDFS 信息直接生成HadoopRDD;FileSourceScanExec 根据数据表所在的源文件生成FileScanRDD 。
当向Hive metastore中读写Parquet表时文件,转化的方式通过 spark.sql.hive.convertMetastoreParquet 控制。
默认为true,如果设置为 true
会使用 :
org.apache.spark.sql.execution.FileSourceScanExec ,
否则会使用 :
org.apache.spark.sql.hive.execution.HiveTableScanExec
目前FileSourceScanExec包括创建分桶表RDD,非分桶表RDD,不管哪种方式,最终生成的都是一个FileRDD。
下面分析的创建非分桶表的RDD
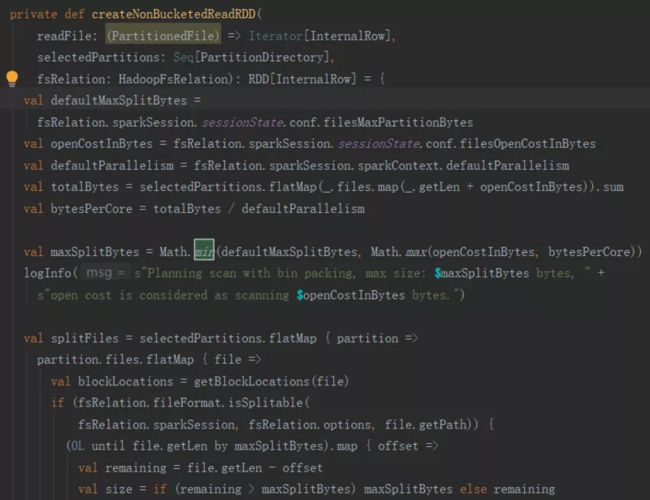
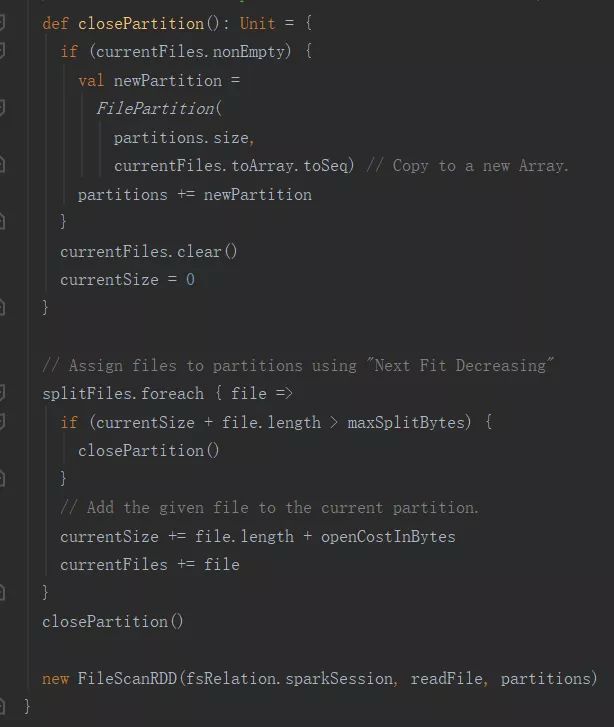
FileRDD的getPartition方法:
override protected def getPartitions: Array[RDDPartition] = filePartitions.toArray要获取maxSplitBytes,那么决定因素在以下三个参数:
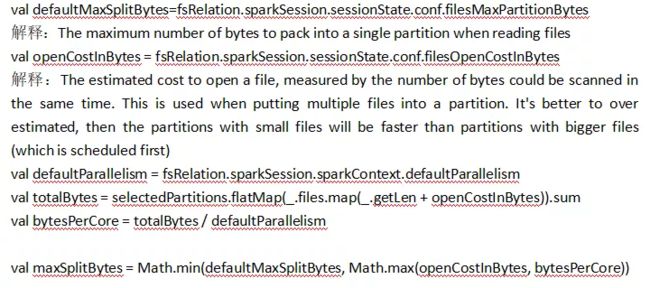
结论:
如果想要使得maxSplitBytes值变大,也就是分区数变小。
可通过将defaultMaxSplitBytes值调大,
也就是spark.sql.files.maxPartitionBytes,
将spark.sql.files.openCostInBytes也调大;
如果如果想要使得maxSplitBytes值变小,也就是分区数变大。
可以将defaultMaxSplitBytes值调小,
也就是spark.sql.files.maxPartitionBytes,
将spark.sql.files.openCostInBytes也调小。
下面分析FileSourceScanExec的创建分桶表的RDD。
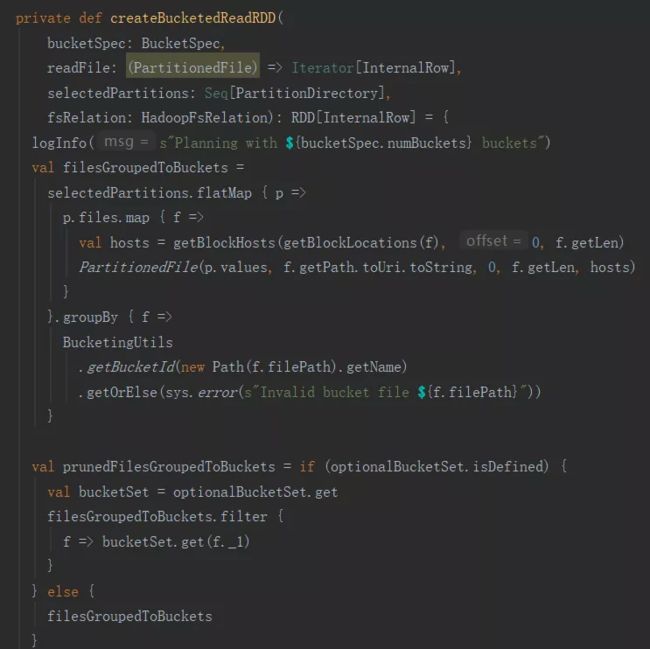
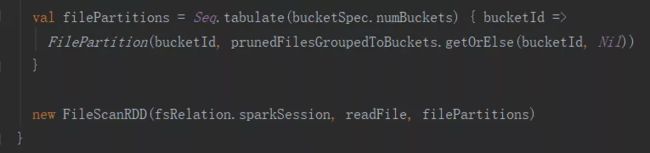
通过源码分析,分桶表的分区数量跟桶的数量是一对一关系。
HiveTableScanExec
HiveTableScanExec 会根据 Hive数据表存储的 HDFS 信息直接生成 HadoopRDD。
通常情况下,HiveTableScanExec通过文件数量,大小进行分区。
例如:
读入一份 2048M 大小的数据,hdfs 块大小设置为 128M
1) 该目录有1000个小文件
答案:则会生成1000个partition。
2) 如果只有1个文件,
答案:则会生成 16 个partition
3) 如果有一个大文件1024M,其余999 个文件共 1024M
答案:则会生成 1007个分区。
针对HiveTableScanExec类型的调优可参考HadoopRDD。
RDD transformation
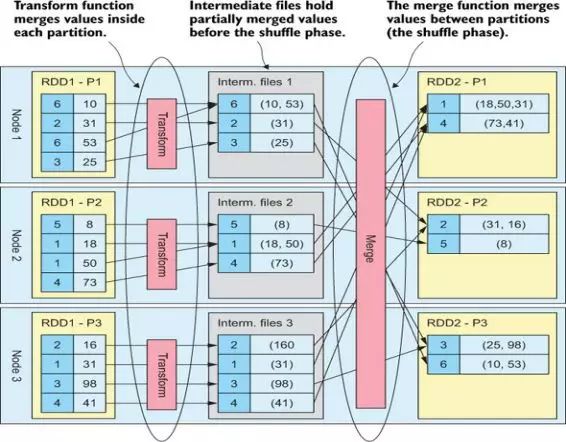
一个RDD通过transformation转换成另外一个RDD,那么新生成的分区数量是多少呢?
1) filter(), map(), flatMap(), distinct()
partition数量等于parent RDD的数量。
2) rdd.union(other_rdd)
partition数量等于rdd_size + other_rdd_size
3) rdd.intersection(other_rdd)
partition数量等于max(rdd_size, other_rdd_size)
4) rdd.subtract(other_rdd)
partition数量等于rdd_size
5) rdd.cartesian(other_rdd)
partition数量等于rdd_size * other_rdd_size
RDD coalesce 与 repartition
有时候需要重新设置RDD的分区数量,比如RDD的分区中,RDD分区比较多,但是每个RDD的数量比较小,分区数量增多可增大任务并行度,但是有可能造成每个分区的数据量偏少,分区数据量太少导致节点间通信时间在整个任务执行时长占比被放大,所以需要设置一个比较合理的分区。
有两种方法可以重设RDD分区:分别是coalesce()方法和repartition()。
Repartition是coalesce函数中shuffle为true的特例。

分布式计算中,每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全部数据,比如reduceByKey、groupByKey,那就需要把相同key的数据拉取到同一个分区,原分区的数据需要被打乱重组,这个按照一定的规则对数据重新分区的过程就是Shuffle(洗牌)。
Shuffle是连接Map和Reduce之间的桥梁,描述的是数据从Map端到Reduce端的过程。
当增加并行度的时候,额外的shuffle是有利的。例如,数据中有一些文件是不可分割的,那么该大文件对应的分区就会有大量的记录,而不是说将数据分散到尽可能多的分区内部来使用所有已经申请cpu。在这种情况下,使用Reparition重新产生更多的分区数,以满足后面转换算子所需的并行度,这会提升很大性能。
分析coalesce函数源码
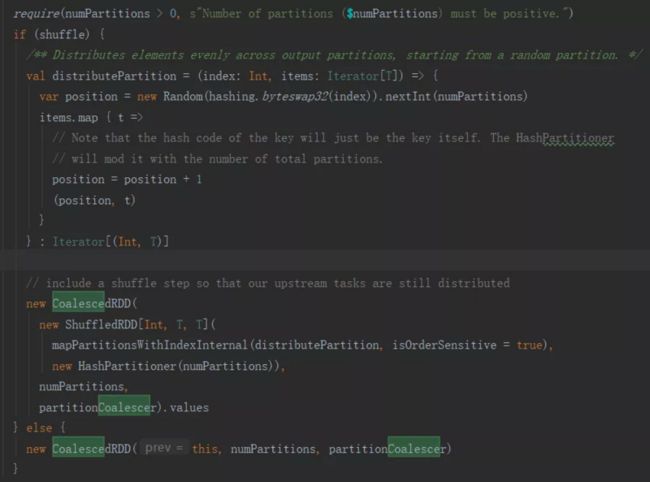
Shuffle = true
数据进行基于新的分区数量进行hash计算, 随机选择输出分区,将输入分区的数据
输出到输出分区中。
Shuffle = false
分析CoalescedRDD源码的getPartitions方法
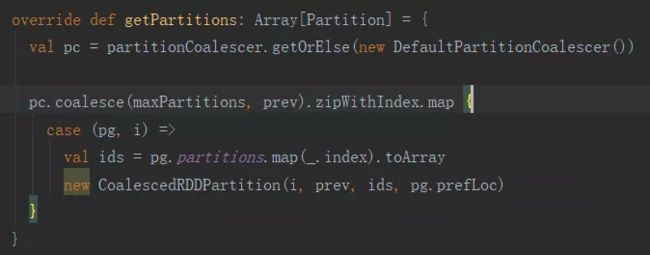
PartitionCoalescer的作用是:
1) 保证CoalescedRDD的每个分区基本上对应于它Parent RDD分区的个数相同;
2) CoalescedRDD的每个分区,尽量跟它的Parent RDD的本地性形同。比如说CoalescedRDD的分区1对应于它的Parent RDD的1到10这10个分区,但是1到7这7个分区在节点1.1.1.1上;那么 CoalescedRDD的分区1所要执行的节点就是1.1.1.1。这么做的目的是为了减少节点间的数据通信,提升处理能力;
3) CoalescedRDD的分区尽量分配到不同的节点执行;具体实现可参考DefaultPartitionCoalescer类。
下面以一个例子来分析Repartition和Coalesce。
假设源RDD有N个分区,需要重新划分成M个分区
1、Repartition实现:
如果N 一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true; 2、Coalesce实现: 如果N>M 1) N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuffle设置为false; 2) 如果M>N时,coalesce是无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系,无法使文件数(partiton)变多。总之如果shuffle为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的; 3) 如果N>M并且两者相差悬殊,这时要看executor数与要生成的partition关系,如果executor数 <= 要生成partition数,coalesce效率高,反之如果用coalesce会导致(executor数-要生成partiton数)个excutor空跑从而降低效率。 Spark作为当前用户使用最广泛的大数据计算引擎之一,在数据分析师中有着广泛的应用,以其处理速度快著称,通过上述的分析,我们能够以合理的计算资源,包括CPU, 内存,executor来执行计算任务,使得我们的集群更高效,在相同的计算资源场景下能获得更多的任务产出。结语
