一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
58招聘网站爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取58同城上面发布的职位信息,分析不同地区薪资水平等。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
通过分析爬取58招聘当中不同城市的同一种职位信息,以程序员为例,通过分析其网页特征来使用python代码切换不同的城市页面,再通过BeautifulSoup库获取其网页标签内的内容来爬取我们所需要的程序员职位数据,之后保存进csv表格内,再通过提取出不同城市程序员的薪水当中的最大值进行绘制柱状图。
技术难点:58招聘的内容较多,在分析其网页结构可能会比普通的求职网站要来得复杂一些,并且注意识别其中一些广告内容。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
58招聘网站中的城市与网页地址中的头两个字母有关,通过使用不同的城市中文拼音简写来实现切换不同的城市页面


顶部是搜索栏,之后是筛选器,而之后就是职位列表了
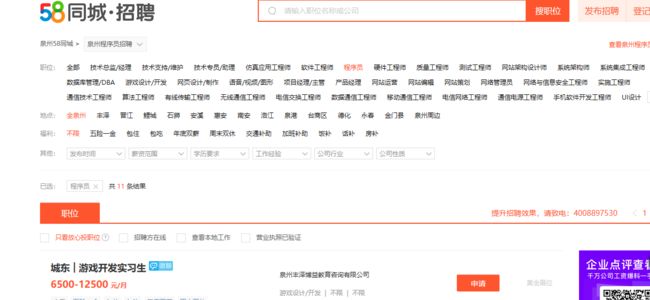
2.Htmls页面解析
查看查看内部标签可以看出职位信息被写在id为list_con的无序列表里的列表项目标签内,且class都是job_item clearfix。
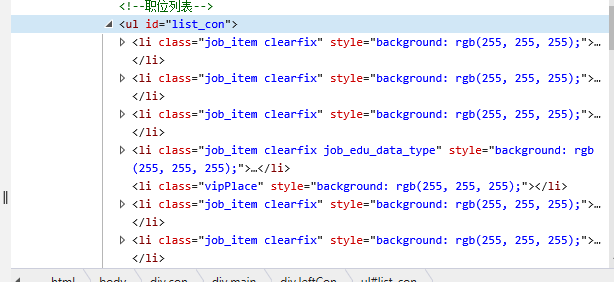
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构 )
通过遍历所有的class为job_item clearfix的li标签,通过查找其中class不同的对应标签来查找相关数据



三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
#导入所要用到的库 import requests import csv import pandas as pd import matplotlib.pyplot as plt from bs4 import BeautifulSoup as bs #创建对象 class Wuba_HTML(): #构造变量city def __init__(self, city): self.city = city #开始获取网页内容 def get_HTML(self): #创建url地址 url = 'https://%s.58.com/chengxuyuan/?PGTID=0d202408-0012-39bf-3ae1-7a57ca6212e9&ClickID=3' \ % (self.city) #创建访问请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } #爬取网页异常处理框架 def requests_caputure(): try: #请求超时时间为30秒 r=requests.get(url,headers=headers,timeout=30) #如果状态不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding=r.apparent_encoding return r.text except: return "发生异常" text=requests_caputure() #构造BeautifulSoup对象 soup = bs(text, 'html.parser') #设置写入的csv的位置和名字和分隔符,写入模式为不覆盖 csv_file = open('D:\\58data.csv', 'a', newline='') writer = csv.writer(csv_file) #写入第一行 writer.writerow(['公司', '地点', '地区', '职位', '薪水']) #遍历所有class为job_item clearfix的li标签的内容 for li in soup.find_all('li', class_='job_item clearfix'): try: #获取公司名称 comp = li.find('div', class_="comp_name").find('a') #获取地址 address = li.find('span', class_='address') #获取工作地区 workcity=list (dic.keys()) [list (dic.values()).index (self.city)] #获取职位名称 job = li.find('span', class_='name') #获取薪资水平 salary = li.find('p', class_='job_salary') #依次写入csv表格 writer.writerow([comp.text, address.text, workcity, job.text, salary.text]) #如果过程中发生异常则直接跳过 except OSError: pass continue print('数据已经写入') def show(): # 设置字体,避免无法输出中文符号 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.family'] = 'sans-serif' # 读取csv表格 df = pd.read_csv(r'D:\58data.csv', encoding="gbk") # 读取“职位”一列中含有“程序员”的相关行 cxy1 = df[df['职位'].str.contains("程序员")] # 过滤“薪水”为“面议 ”的行 cxy2 = cxy1[~cxy1['薪水'].isin(['面议'])] # 创建空列表来保存之后分析下来的薪水信息 qz = [] xm = [] fz = [] hz = [] sh = [] bj = [] # 读取地区为“泉州”的程序员的薪水 qz_cxy = cxy2[cxy2['地区'].isin(['泉州'])] qz_cxy2 = qz_cxy['薪水'] # 将其作为列表返回 data_list1 = qz_cxy2.values.tolist() # 将薪水内想要的数字依次提取出来放进新列表,例如“6000-8000每月”中的“6000” for i in data_list1: # 提取前4个字符 qz.append(i[0:4]) # 将其转换为整型,并且取出最大值用于对比 qz_maxsalary = int(max(qz)) # 读取表格里面地区为厦门的程序员薪水信息 xm_cxy = cxy2[cxy2['地区'].isin(['厦门'])] xm_cxy2 = xm_cxy['薪水'] data_list2 = xm_cxy2.values.tolist() for j in data_list2: xm.append(j[0:4]) # 选取最大值用于对比 xm_maxsalary = int(max(xm)) # 选取表格中地区为福州的程序员薪水信息 fz_cxy = cxy2[cxy2['地区'].isin(['福州'])] fz_cxy2 = fz_cxy['薪水'] data_list3 = fz_cxy2.values.tolist() for k in data_list3: fz.append(k[0:4]) fz_maxsalary = int(max(fz)) # 选取表格中地区为杭州的程序员薪水信息 hz_cxy = cxy2[cxy2['地区'].isin(['杭州'])] hz_cxy2 = hz_cxy['薪水'] data_list4 = hz_cxy2.values.tolist() for l in data_list4: hz.append(l[0:4]) # 选取最大值用于对比 hz_maxsalary = int(max(hz)) # 选取表格中地区为上海的程序员薪水信息 sh_cxy = cxy2[cxy2['地区'].isin(['上海'])] sh_cxy2 = sh_cxy['薪水'] data_list5 = sh_cxy2.values.tolist() for m in data_list5: sh.append(m[0:4]) # 选取最大值用于对比 sh_maxsalary = int(max(sh)) # 选取表格中地区为北京的程序员薪水信息 bj_cxy = cxy2[cxy2['地区'].isin(['北京'])] bj_cxy2 = bj_cxy['薪水'] data_list6 = bj_cxy2.values.tolist() for n in data_list6: bj.append(n[0:4]) # 选取最大值用于对比 bj_maxsalary = int(max(bj)) # 绘制图表,纵坐标为薪水数量,横坐标为城市名称 s = pd.Series([qz_maxsalary, xm_maxsalary, fz_maxsalary, hz_maxsalary, sh_maxsalary, bj_maxsalary], ['泉州', '厦门', '福州', '杭州', '上海', '北京']) # 设置图表标题 s.plot(kind='bar', title='各城市工资对比图片') # 输出图片 plt.show() if __name__ == '__main__': #定义所查找的城市 citys=['qz','xm','fz','hz','sh','bj'] #定义字典用于返回工作地区,当网页内的城市简写与对应的字典值相等时时,workcity返回相应的地区 dic={"泉州": "qz", "厦门":"xm","福州":"fz","杭州":"hz","上海":"sh","北京":"bj"} #依次将city变量代入执行函数 for i in citys: a = Wuba_HTML(i) a.get_HTML() show()
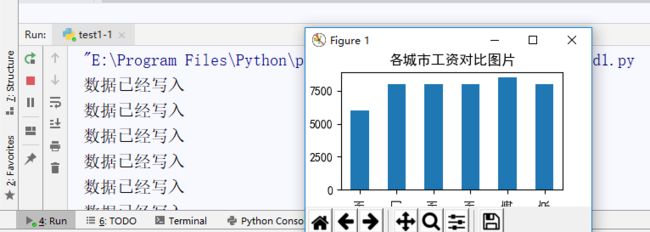
1.数据爬取与采集
def get_HTML(self): url = 'https://%s.58.com/chengxuyuan/?PGTID=0d202408-0012-39bf-3ae1-7a57ca6212e9&ClickID=3' \ % (self.city) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } def requests_caputure(): try: r=requests.get(url,headers=headers,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "发生异常" text=requests_caputure() soup = bs(text, 'html.parser') csv_file = open('D:\\58data.csv', 'a', newline='') writer = csv.writer(csv_file) writer.writerow(['公司', '地点', '地区', '职位', '薪水']) for li in soup.find_all('li', class_='job_item clearfix'): try: comp = li.find('div', class_="comp_name").find('a') address = li.find('span', class_='address') workcity=list (dic.keys()) [list (dic.values()).index (self.city)] job = li.find('span', class_='name') salary = li.find('p', class_='job_salary') writer.writerow([comp.text, address.text, workcity, job.text, salary.text]) except OSError: pass continue print('数据已经写入')
2.对数据进行清洗和处理
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.family'] = 'sans-serif' df = pd.read_csv(r'D:\58data.csv', encoding="gbk") cxy1 = df[df['职位'].str.contains("程序员")] cxy2 = cxy1[~cxy1['薪水'].isin(['面议'])] qz = [] xm = [] fz = [] hz = [] sh = [] bj = [] qz_cxy = cxy2[cxy2['地区'].isin(['泉州'])] qz_cxy2 = qz_cxy['薪水'] data_list1 = qz_cxy2.values.tolist() for i in data_list1: qz.append(i[0:4]) qz_maxsalary = int(max(qz)) xm_cxy = cxy2[cxy2['地区'].isin(['厦门'])] xm_cxy2 = xm_cxy['薪水'] data_list2 = xm_cxy2.values.tolist() for j in data_list2: xm.append(j[0:4]) xm_maxsalary = int(max(xm)) fz_cxy = cxy2[cxy2['地区'].isin(['福州'])] fz_cxy2 = fz_cxy['薪水'] data_list3 = fz_cxy2.values.tolist() for k in data_list3: fz.append(k[0:4]) fz_maxsalary = int(max(fz)) hz_cxy = cxy2[cxy2['地区'].isin(['杭州'])] hz_cxy2 = hz_cxy['薪水'] data_list4 = hz_cxy2.values.tolist() for l in data_list4: hz.append(l[0:4]) hz_maxsalary = int(max(hz)) sh_cxy = cxy2[cxy2['地区'].isin(['上海'])] sh_cxy2 = sh_cxy['薪水'] data_list5 = sh_cxy2.values.tolist() for m in data_list5: sh.append(m[0:4]) sh_maxsalary = int(max(sh)) bj_cxy = cxy2[cxy2['地区'].isin(['北京'])] bj_cxy2 = bj_cxy['薪水'] data_list6 = bj_cxy2.values.tolist() for n in data_list6: bj.append(n[0:4]) bj_maxsalary = int(max(bj))
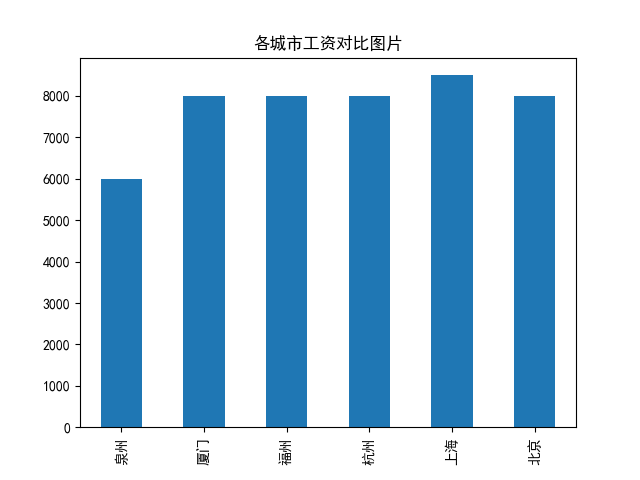
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
# 绘制图表,纵坐标为薪水数量,横坐标为城市名称 s = pd.Series([qz_maxsalary, xm_maxsalary, fz_maxsalary, hz_maxsalary, sh_maxsalary, bj_maxsalary], ['泉州', '厦门', '福州', '杭州', '上海', '北京']) # 设置图表标题 s.plot(kind='bar', title='各城市工资对比图片') # 输出图片 plt.show()
csv_file = open('D:\\58data.csv', 'a', newline='') writer = csv.writer(csv_file) writer.writerow(['公司', '地点', '地区', '职位', '薪水']) for li in soup.find_all('li', class_='job_item clearfix'): try: comp = li.find('div', class_="comp_name").find('a') address = li.find('span', class_='address') workcity=list (dic.keys()) [list (dic.values()).index (self.city)] job = li.find('span', class_='name') salary = li.find('p', class_='job_salary') writer.writerow([comp.text, address.text, workcity, job.text, salary.text]) except OSError: pass continue print('数据已经写入')
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过获取岗位信息,能够很直观的看到不同地区的同一种职位的差距,本次爬虫分析则是很直观地看到了在薪资上的不同。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
整体上的爬取内容与预期相符合,虽然爬取到的职位信息有个别是培训内容和广告信息,但是不影响最终的可视化结果。