引言
HyperLogLog算法经常在数据库中被用来统计某一字段的Distinct Value(下文简称DV),比如Redis的HyperLogLog结构,出于好奇探索了一下这个算法的原理,无奈中文资料很少,只能直接去阅读论文以及一些英文资料,总结成此文。
介绍
HyperLogLog算法来源于论文《HyperLogLog the analysis of a near-optimal cardinality estimation algorithm》(下载地址见文末的参考文献),可以使用固定大小的字节计算任意大小的DV,本文先介绍该算法的原理,然后通过剖析stream-lib(一个Java实现的实时计算库)对此算法的实现来进一步理解该算法。本文追求直观理解,所以不会太过于纠结一些数学细节,如果关心数学细节的话可以直接去看论文,论文里会有具体的证明。
基数
基数就是指一个集合中不同值的数目,比如[a,b,c,d]的基数就是4,[a,b,c,d,a]的基数还是4,因为a重复了一个,不算。基数也可以称之为Distinct Value,简称DV。下文中可能有时候称呼为基数,有时候称之为DV,但都是同一个意思。HyperLogLog算法就是用来计算基数的。
生活中的启发-以抛硬币为例

HyperLogLog本质上来源于生活中一个小的发现,假设你抛了很多次硬币,你告诉在这次抛硬币的过程中最多只有两次扔出连续的反面,让我猜你总共抛了多少次硬币,我敢打赌你抛硬币的总次数不会太多,相反,如果你和我说最多出现了100次连续的反面,那么我敢肯定扔硬盘的总次数非常的多,甚至我还可以给出一个估计,这个估计要怎么给呢?其实是一个很简单的概率问题,假设1代表抛出正面,0代表反面:
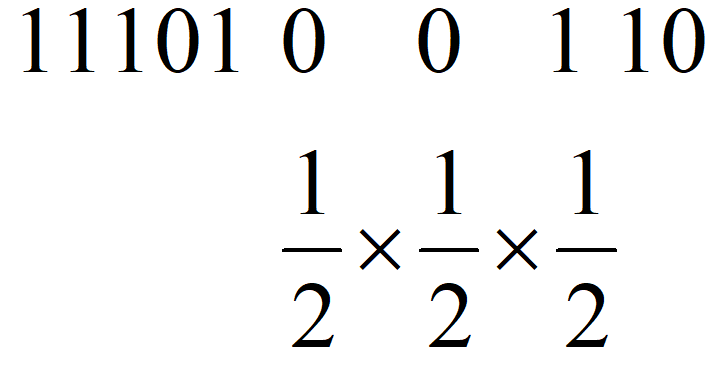
上图中以抛硬币序列"1110100110"为例,其中最长的反面序列是"00",我们顺手把后面那个1也给带上,也就是"001",因为它包括了序列中最长的一串0,所以在序列中肯定只出现过一次,而它在任意序列出现出现且仅出现一次的概率显然是上图所示的三个二分之一相乘,也就是八分之一,所以我可以给出一个估计值,你大概总共抛了8次硬币。
很显然,上面这种做法虽然能够估计抛硬币的总数,但是显然误差是比较大的,很容易受到突发事件(比如突然连续抛出好多0)的影响,HyperLogLog算法研究的就是如何减小这个误差。
之前说过,HyperLogLog算法是用来计算基数的,这个抛硬币的序列和基数有什么关系呢?比如在数据库中,我只要在每次插入一条新的记录时,计算这条记录的hash,并且转换成二进制,就可以将其看成一个硬币序列了,如下(0b前缀表示二进制数):
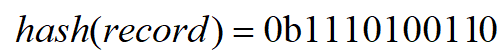
最简单的想法
根据上面抛硬币的启发我可以想到如下的估计基数的算法(这里先给出伪代码,后面会有Java实现):
输入:一个集合
输出:集合的基数
算法:
max = 0
对于集合中的每个元素:
hashCode = hash(元素)
num = hashCode二进制表示中最前面连续的0的数量
if num > max:
max = num
最后的结果是2的(max + 1)次幂
举个例子,对于集合{ele1, ele2},先求hash(ele1)=0b00110111,它最前面的连续的0的数量为2(又称为前导0),然后求hash(ele2)=0b10010000111,它的前导0数量为0,我们始终只保存前导零数量的最大值,所以最后max是2,我们估计的基数就是2的(2+1)次幂,即8。
为什么最后的max要加1呢?这是一个数学细节,具体要看论文,简单的理解的话,可以像之前抛硬币的例子那样理解,把最长的一串零的后面的一个1或者前面的一个1"顺手"带上进行概率估计。
显然这个算法是非常不准确的,但是这个想法还是很有启发性的,从这个简单的想法跟随下文一步一步优化即可得到最终的比较高精度的HyperLogLog算法。
分桶
最简单的一种优化方法显然就是把数据分成m个均等的部分,分别估计其总数求平均后再乘以m,称之为分桶。对应到前面抛硬币的例子,其实就是把硬币序列分成m个均等的部分,分别用之前提到的那个方法估计总数求平均后再乘以m,这样就能一定程度上避免单一突发事件造成的误差。
具体要怎么分桶呢?我们可以将每个元素的hash值的二进制表示的前几位用来指示数据属于哪个桶,然后把剩下的部分再按照之前最简单的想法处理。
还是以刚刚的那个集合{ele1,ele2}为例,假设我要分2个桶,那么我只要去ele1的hash值的第一位来确定其分桶即可,之后用剩下的部分进行前导零的计算,如下图:
假设ele1和ele2的hash值二进制表示如下:
hash(ele1) = 00110111
hash(ele2) = 10010001
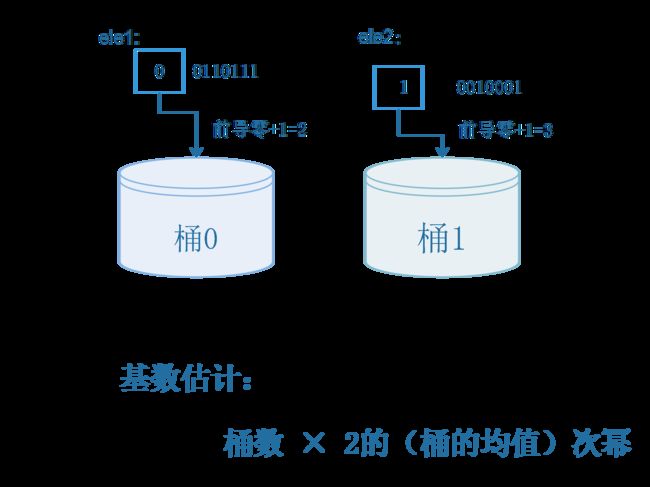
到这里,你大概已经理解了LogLog算法的基本思想,LogLog算法是在HyperLogLog算法之前提出的一个基数估计算法,HyperLogLog算法其实就是LogLog算法的一个改进版。
LogLog算法完整的基数计算公式如下:
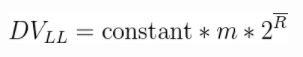
其中m代表分桶数,R头上一道横杠的记号就代表每个桶的结果(其实就是桶中数据的最长前导零+1)的均值,相比我之前举的简单的例子,LogLog算法还乘了一个常数constant进行修正,这个constant具体是多少等我讲到Java实现的时候再说。
调和平均数
前面的LogLog算法中我们是使用的是平均数来将每个桶的结果汇总起来,但是平均数有一个广为人知的缺点,就是容易受到大的数值的影响,一个常见的例子是,假如我的工资是1000元一个月,我老板的工资是100000元一个月,那么我和老板的平均工资就是(100000 + 1000)/2,即50500元,显然这离我的工资相差甚远,我肯定不服这个平均工资。
用调和平均数就可以解决这一问题,调和平均数的结果会倾向于集合中比较小的数,x1到xn的调和平均数的公式如下:
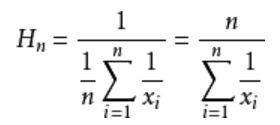
再用这个公式算一下我和老板的平均工资:
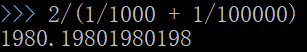
最后的结果是1980元,这和我的工资水平还比较接近,这样的平均工资水平我才比较信服。
再回到前面的LogLog算法,从前面的举的例子可以看出,
影响LogLog算法精度的一个重要因素就是,hash值的前导零的数量显然是有很大的偶然性的,经常会出现一两数据前导零的数目比较多的情况,所以HyperLogLog算法相比LogLog算法一个重要的改进就是使用调和平均数而不是平均数来聚合每个桶中的结果,HyperLogLog算法的公式如下:
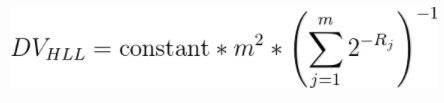
其中constant常数和m的含义和之前的LogLog算法公式中的含义一致,Rj代表(第j个桶中的数据的最大前导零数目+1),为了方便理解,我将公式再拆解一下:

其实从算术平均数改成调和平均数这个优化是很容易想到的,但是为什么LogLog算法没有直接使用调和平均数吗?网上看到一篇英文文章里说大概是因为使用算术平均数的话证明比较容易一些,毕竟科学家们出论文每一步都是要证明的,不像我们这里简单理解一下,猜一猜就可以了。
细节微调
关于HyperLogLog算法的大体思想到这里你就已经全部理解了。
不过算法中还有一些细微的校正,在数据总量比较小的时候,很容易就预测偏大,所以我们做如下校正:
(DV代表估计的基数值,m代表桶的数量,V代表结果为0的桶的数目,log表示自然对数)
if DV < (5 / 2) * m:
DV = m * log(m/V)
我再详细解释一下V的含义,假设我分配了64个桶(即m=64),当数据量很小时(比方说只有两三个),那肯定有大量桶中没有数据,也就说他们的估计值是0,V就代表这样的桶的数目。
事实证明,这个校正的效果是非常好,在数据量小的时,估计得非常准确,有兴趣可以去玩一下外国大佬制作的一个HyperLogLog算法的仿真:
http://content.research.neustar.biz/blog/hll.html
constant常数的选择
constant常数的选择与分桶的数目有关,具体的数学证明请看论文,这里就直接给出结论:
假设:m为分桶数,p是m的以2为底的对数
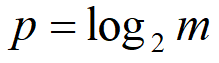
则按如下的规则计算constant
switch (p) {
case 4:
constant = 0.673 * m * m;
case 5:
constant = 0.697 * m * m;
case 6:
constant = 0.709 * m * m;
default:
constant = (0.7213 / (1 + 1.079 / m)) * m * m;
}
分桶数m的选择
如果理解了之前的分桶算法,那么很显然分桶数只能是2的整数次幂。
如果分桶越多,那么估计的精度就会越高,统计学上用来衡量估计精度的一个指标是“相对标准误差”(relative standard deviation,简称RSD),RSD的计算公式这里就不给出了,百科上一搜就可以知道,从直观上理解,RSD的值其实就是((每次估计的值)在(估计均值)上下的波动)占(估计均值)的比例(这句话加那么多括号是为了方便大家断句)。RSD的值与分桶数m存在如下的计算关系:
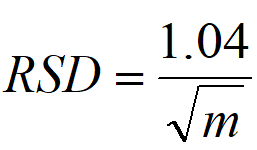
有了这个公式,你可以先确定你想要达到的RSD的值,然后再推出分桶的数目m。
合并
假设有两个数据流,分别构建了两个HyperLogLog结构,称为a和b,他们的桶数是一样的,为n,现在要计算两个数据流总体的基数。
数据流a:"a" "b" "c" "d" 基数:4
数据流b:"b" "c" "d" "e" 基数:4
两个数据流的总体基数:5
从前文我们可以知道,HyperLogLog算法在内存中的结构其实就是一个桶数组,需要先用下面的算法从a和我b的桶数组中构建出新的桶数组c,其实就是从a,b的对应位置取最大的:
输入:桶数组a,b。它们的长度都是n
输出:新的桶数组c
算法:
c = c[n];
for (i=0; i之后用桶数组c代入前面的算法即可得到合并的总体基数。
Redis中的实现
Redis中和HyperLogLog相关的命令有三个:
-
PFADD hll ele:将ele添加进hll的基数计算中。流程:- 先对ele求hash(使用的是一种叫做MurMurHash的算法)
- 将hash的低14位(因为总共有2的14次方个桶)作为桶的编号,选桶,记桶中当前的值为count
- 从的hash的第15位开始数0,假设从第15位开始有n个连续的0(即前导0)
- 如果n大于count,则把选中的桶的值置为n,否则不变
-
PFCOUNT hll:计算hll的基数。就是使用上面给出的DV公式根据桶中的数值,计算基数 -
PFMERGE hll3 hll1 hll2:将hll1和hll2合并成hll3。用的就是上面说的合并算法。
Redis的所有HyperLogLog结构都是固定的16384个桶(2的14次方),并且有两种存储格式:
- 稀疏格式:HyperLogLog算法在刚开始的时候,大多数桶其实都是0,稀疏格式通过存储连续的0的数目,而不是每个0存一遍,大大减小了HyperLogLog刚开始时需要占用的内存
- 紧凑格式:用6个bit表示一个桶,需要占用12KB内存
如果还想更详细地了解Redis中的实现细节的话,可以阅读我的另一篇博客Redis源码走马观花(5)HyperLogLog
HyperLogLog索引
之前在蚂蚁实习的时候,用的一个自研数据库号称支持HyperLogLog索引.(目前还不知道有什么开源的数据库支持这玩意,如果你知道,欢迎在评论里告诉我)。
所谓HyperLogLog索引,比如你在user列上建立了一个hyperLogLog索引,那么当你使用如下的查询时:
SELECT COUNT(DISTINCT user) FROM users WHERE age >= 10 and city = "shanghai";
在计算COUNT(DISTINCT)时,会自动使用之前构建好的HyperLogLog索引来加速,据说能够获得数量级上的查询速度提升。
如果仔细看了之前的算法,到这里可能会产生困惑,通过HyperLogLog似乎只能得到user的基数是多少,那又怎么能知道含有一定含有一定筛选条件(WHERE age > 10 and city = "shanghai")的user基数是多少呢?
其实再仔细想想,也很简单,通过前面介绍过的“合并”就可以完成,对每个不同的city都构建了一个关于user的HyperLogLog结构,因为age自己的基数比较,数据库可能是根据范围在每个范围构建了一个HyperLogLog结构,比如分别是010,1020,2030,这样只需要将涉及到的这三个HyperLogLog结构合并即可(三个分别是指city为"guangzhou",age为1020和age为20~30)。
这个只是我的个人猜测,也可能不是这样。哪怕不保存任何索引,也只要将查出来的数据扫一遍即可,应该也比传统基于排序或者hash的distinct快不少。
Java实现分析
stream-lib是一个开源的Java流式计算库,里面有很多大数据估值算法的实现,其中当然包括HyperLogLog算法,HyperLogLog实现类的代码地址如下:
https://github.com/addthis/stream-lib/blob/master/src/main/java/com/clearspring/analytics/stream/cardinality/HyperLogLog.java
这个实现类中还包含很多与算法无关的序列化之类的代码,所以不建议你直接去看,我把它的算法主干抽取了出来,变成了如下的三个类,你把这三个类的代码复制下来放到项目的同一个包下即可,HyperLogLog类中还包含一个main函数,你可以运行一下看看代码是否正确,代码如下:
HyperLogLog.java
public class HyperLogLog {
private final RegisterSet registerSet;
private final int log2m; //log(m)
private final double alphaMM;
/**
*
* rsd = 1.04/sqrt(m)
* @param rsd 相对标准偏差
*/
public HyperLogLog(double rsd) {
this(log2m(rsd));
}
/**
* rsd = 1.04/sqrt(m)
* m = (1.04 / rsd)^2
* @param rsd 相对标准偏差
* @return
*/
private static int log2m(double rsd) {
return (int) (Math.log((1.106 / rsd) * (1.106 / rsd)) / Math.log(2));
}
private static double rsd(int log2m) {
return 1.106 / Math.sqrt(Math.exp(log2m * Math.log(2)));
}
/**
* accuracy = 1.04/sqrt(2^log2m)
*
* @param log2m
*/
public HyperLogLog(int log2m) {
this(log2m, new RegisterSet(1 << log2m));
}
/**
*
* @param registerSet
*/
public HyperLogLog(int log2m, RegisterSet registerSet) {
this.registerSet = registerSet;
this.log2m = log2m;
int m = 1 << this.log2m; //从log2m中算出m
alphaMM = getAlphaMM(log2m, m);
}
public boolean offerHashed(int hashedValue) {
// j 代表第几个桶,取hashedValue的前log2m位即可
// j 介于 0 到 m
final int j = hashedValue >>> (Integer.SIZE - log2m);
// r代表 除去前log2m位剩下部分的前导零 + 1
final int r = Integer.numberOfLeadingZeros((hashedValue << this.log2m) | (1 << (this.log2m - 1)) + 1) + 1;
return registerSet.updateIfGreater(j, r);
}
/**
* 添加元素
* @param o 要被添加的元素
* @return
*/
public boolean offer(Object o) {
final int x = MurmurHash.hash(o);
return offerHashed(x);
}
public long cardinality() {
double registerSum = 0;
int count = registerSet.count;
double zeros = 0.0;
//count是桶的数量
for (int j = 0; j < registerSet.count; j++) {
int val = registerSet.get(j);
registerSum += 1.0 / (1 << val);
if (val == 0) {
zeros++;
}
}
double estimate = alphaMM * (1 / registerSum);
if (estimate <= (5.0 / 2.0) * count) { //小数据量修正
return Math.round(linearCounting(count, zeros));
} else {
return Math.round(estimate);
}
}
/**
* 计算constant常数的取值
* @param p log2m
* @param m m
* @return
*/
protected static double getAlphaMM(final int p, final int m) {
// See the paper.
switch (p) {
case 4:
return 0.673 * m * m;
case 5:
return 0.697 * m * m;
case 6:
return 0.709 * m * m;
default:
return (0.7213 / (1 + 1.079 / m)) * m * m;
}
}
/**
*
* @param m 桶的数目
* @param V 桶中0的数目
* @return
*/
protected static double linearCounting(int m, double V) {
return m * Math.log(m / V);
}
public static void main(String[] args) {
HyperLogLog hyperLogLog = new HyperLogLog(0.1325);//64个桶
//集合中只有下面这些元素
hyperLogLog.offer("hhh");
hyperLogLog.offer("mmm");
hyperLogLog.offer("ccc");
//估算基数
System.out.println(hyperLogLog.cardinality());
}
}
MurmurHash.java
/**
* 一种快速的非加密hash
* 适用于对保密性要求不高以及不在意hash碰撞攻击的场合
*/
public class MurmurHash {
public static int hash(Object o) {
if (o == null) {
return 0;
}
if (o instanceof Long) {
return hashLong((Long) o);
}
if (o instanceof Integer) {
return hashLong((Integer) o);
}
if (o instanceof Double) {
return hashLong(Double.doubleToRawLongBits((Double) o));
}
if (o instanceof Float) {
return hashLong(Float.floatToRawIntBits((Float) o));
}
if (o instanceof String) {
return hash(((String) o).getBytes());
}
if (o instanceof byte[]) {
return hash((byte[]) o);
}
return hash(o.toString());
}
public static int hash(byte[] data) {
return hash(data, data.length, -1);
}
public static int hash(byte[] data, int seed) {
return hash(data, data.length, seed);
}
public static int hash(byte[] data, int length, int seed) {
int m = 0x5bd1e995;
int r = 24;
int h = seed ^ length;
int len_4 = length >> 2;
for (int i = 0; i < len_4; i++) {
int i_4 = i << 2;
int k = data[i_4 + 3];
k = k << 8;
k = k | (data[i_4 + 2] & 0xff);
k = k << 8;
k = k | (data[i_4 + 1] & 0xff);
k = k << 8;
k = k | (data[i_4 + 0] & 0xff);
k *= m;
k ^= k >>> r;
k *= m;
h *= m;
h ^= k;
}
// avoid calculating modulo
int len_m = len_4 << 2;
int left = length - len_m;
if (left != 0) {
if (left >= 3) {
h ^= (int) data[length - 3] << 16;
}
if (left >= 2) {
h ^= (int) data[length - 2] << 8;
}
if (left >= 1) {
h ^= (int) data[length - 1];
}
h *= m;
}
h ^= h >>> 13;
h *= m;
h ^= h >>> 15;
return h;
}
public static int hashLong(long data) {
int m = 0x5bd1e995;
int r = 24;
int h = 0;
int k = (int) data * m;
k ^= k >>> r;
h ^= k * m;
k = (int) (data >> 32) * m;
k ^= k >>> r;
h *= m;
h ^= k * m;
h ^= h >>> 13;
h *= m;
h ^= h >>> 15;
return h;
}
public static long hash64(Object o) {
if (o == null) {
return 0l;
} else if (o instanceof String) {
final byte[] bytes = ((String) o).getBytes();
return hash64(bytes, bytes.length);
} else if (o instanceof byte[]) {
final byte[] bytes = (byte[]) o;
return hash64(bytes, bytes.length);
}
return hash64(o.toString());
}
// 64 bit implementation copied from here: https://github.com/tnm/murmurhash-java
/**
* Generates 64 bit hash from byte array with default seed value.
*
* @param data byte array to hash
* @param length length of the array to hash
* @return 64 bit hash of the given string
*/
public static long hash64(final byte[] data, int length) {
return hash64(data, length, 0xe17a1465);
}
/**
* Generates 64 bit hash from byte array of the given length and seed.
*
* @param data byte array to hash
* @param length length of the array to hash
* @param seed initial seed value
* @return 64 bit hash of the given array
*/
public static long hash64(final byte[] data, int length, int seed) {
final long m = 0xc6a4a7935bd1e995L;
final int r = 47;
long h = (seed & 0xffffffffl) ^ (length * m);
int length8 = length / 8;
for (int i = 0; i < length8; i++) {
final int i8 = i * 8;
long k = ((long) data[i8 + 0] & 0xff) + (((long) data[i8 + 1] & 0xff) << 8)
+ (((long) data[i8 + 2] & 0xff) << 16) + (((long) data[i8 + 3] & 0xff) << 24)
+ (((long) data[i8 + 4] & 0xff) << 32) + (((long) data[i8 + 5] & 0xff) << 40)
+ (((long) data[i8 + 6] & 0xff) << 48) + (((long) data[i8 + 7] & 0xff) << 56);
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
switch (length % 8) {
case 7:
h ^= (long) (data[(length & ~7) + 6] & 0xff) << 48;
case 6:
h ^= (long) (data[(length & ~7) + 5] & 0xff) << 40;
case 5:
h ^= (long) (data[(length & ~7) + 4] & 0xff) << 32;
case 4:
h ^= (long) (data[(length & ~7) + 3] & 0xff) << 24;
case 3:
h ^= (long) (data[(length & ~7) + 2] & 0xff) << 16;
case 2:
h ^= (long) (data[(length & ~7) + 1] & 0xff) << 8;
case 1:
h ^= (long) (data[length & ~7] & 0xff);
h *= m;
}
;
h ^= h >>> r;
h *= m;
h ^= h >>> r;
return h;
}
}
RegisterSet.java
public class RegisterSet {
public final static int LOG2_BITS_PER_WORD = 6; //2的6次方是64
public final static int REGISTER_SIZE = 5; //每个register占5位,代码里有一些细节涉及到这个5位,所以仅仅改这个参数是会报错的
public final int count;
public final int size;
private final int[] M;
//传入m
public RegisterSet(int count) {
this(count, null);
}
public RegisterSet(int count, int[] initialValues) {
this.count = count;
if (initialValues == null) {
/**
* 分配(m / 6)个int给M
*
* 因为一个register占五位,所以每个int(32位)有6个register
*/
this.M = new int[getSizeForCount(count)];
} else {
this.M = initialValues;
}
//size代表RegisterSet所占字的大小
this.size = this.M.length;
}
public static int getBits(int count) {
return count / LOG2_BITS_PER_WORD;
}
public static int getSizeForCount(int count) {
int bits = getBits(count);
if (bits == 0) {
return 1;
} else if (bits % Integer.SIZE == 0) {
return bits;
} else {
return bits + 1;
}
}
public void set(int position, int value) {
int bucketPos = position / LOG2_BITS_PER_WORD;
int shift = REGISTER_SIZE * (position - (bucketPos * LOG2_BITS_PER_WORD));
this.M[bucketPos] = (this.M[bucketPos] & ~(0x1f << shift)) | (value << shift);
}
public int get(int position) {
int bucketPos = position / LOG2_BITS_PER_WORD;
int shift = REGISTER_SIZE * (position - (bucketPos * LOG2_BITS_PER_WORD));
return (this.M[bucketPos] & (0x1f << shift)) >>> shift;
}
public boolean updateIfGreater(int position, int value) {
int bucket = position / LOG2_BITS_PER_WORD; //M下标
int shift = REGISTER_SIZE * (position - (bucket * LOG2_BITS_PER_WORD)); //M偏移
int mask = 0x1f << shift; //register大小为5位
// 这里使用long是为了避免int的符号位的干扰
long curVal = this.M[bucket] & mask;
long newVal = value << shift;
if (curVal < newVal) {
//将M的相应位置为新的值
this.M[bucket] = (int) ((this.M[bucket] & ~mask) | newVal);
return true;
} else {
return false;
}
}
public void merge(RegisterSet that) {
for (int bucket = 0; bucket < M.length; bucket++) {
int word = 0;
for (int j = 0; j < LOG2_BITS_PER_WORD; j++) {
int mask = 0x1f << (REGISTER_SIZE * j);
int thisVal = (this.M[bucket] & mask);
int thatVal = (that.M[bucket] & mask);
word |= (thisVal < thatVal) ? thatVal : thisVal;
}
this.M[bucket] = word;
}
}
int[] readOnlyBits() {
return M;
}
public int[] bits() {
int[] copy = new int[size];
System.arraycopy(M, 0, copy, 0, M.length);
return copy;
}
}
这里hash算法使用的是MurmurHash算法,可能很多人没听说过,其实在开源项目中使用的非常广泛,这个算法在只追求速度和hash的随机性,而不在意安全性和保密性的时候非常有效,我们不去深究这个算法的原理了,这个类的代码也不必仔细看,就把它看成一个hash函数就好了。
还有需要稍微注意一下这里的RegisterSet类,我们把存放一个桶的结果的地方叫做一个register,类中M数组就是存放这些register内容的地方,在这里我们设置一个register占5位,所以每个int(32位)总共可以存放6个register。
重点去阅读HyperLogLog类,我添加了相关注释方便你阅读,希望能够帮助你了解更多细节。
参考资料
1.论文《HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm》
http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
如果有兴趣去了解算法的数学证明的大佬可以去看一下
2.老外写的一篇博客:
https://research.neustar.biz/2012/10/25/sketch-of-the-day-hyperloglog-cornerstone-of-a-big-data-infrastructure/
3.老外做的一个仿真,玩一玩有助理解
http://content.research.neustar.biz/blog/hll.html