参考链接:
学习Hadoop第30课
学习Hadoop第31课
- 查看数据库:show databases;建立数据库:create database XXXX;
- 查看表:show tables;
- 查看建表语句:
create table student(id int, name string);
show create table student;(student 是表名字)
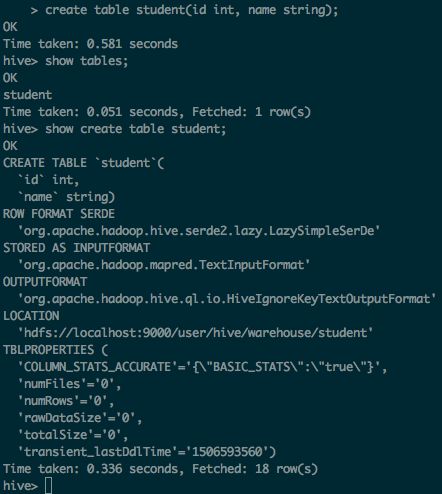
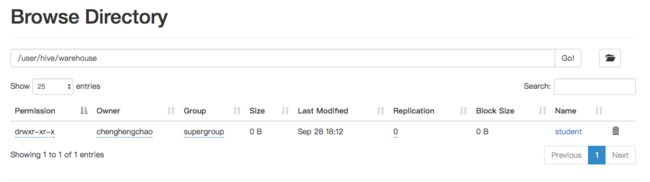
location显示了表的位置:‘ hdfs://localhost:9000/user/hive/warehouse/student’,student是一个文件夹,此时里面是空的,之后向该表插入数据就是降文件放到这个文件夹下
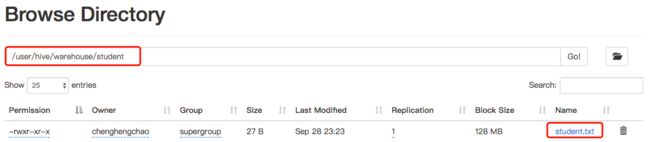
4.加载数据
在本地建立文件student.txt,输入几行内容,用空格分割,并保存
1 zhangsan
2 lisi
3 wangwu
在hive中加载数据:
hive> load data local inpath '/Users/chenghengchao/student.txt' into table student;
Loading data to table default.student
OK
Time taken: 0.227 seconds
5.查询数据
hive> select * from student;
OK
NULL NULL
NULL NULL
NULL NULL
Time taken: 0.139 seconds, Fetched: 3 row(s)
从结果来看,有3行两列记录,但是全部都是null。这是因为创建表的时候没有指定分隔符。如果查询行数,结果会是3:
hive> select count(*) from student;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = chenghengchao_20170929100451_7ff3538e-fe6c-40f6-bed2-aeff7a588dac
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1506650650336_0001, Tracking URL = http://chenghengchaodeMacBook-Air.local:8088/proxy/application_1506650650336_0001/
Kill Command = /usr/local/Cellar/hadoop/2.8.1/libexec/bin/hadoop job -kill job_1506650650336_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-09-29 10:05:08,428 Stage-1 map = 0%, reduce = 0%
2017-09-29 10:05:14,768 Stage-1 map = 100%, reduce = 0%
2017-09-29 10:05:20,056 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1506650650336_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 7587 HDFS Write: 101 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
3
Time taken: 29.506 seconds, Fetched: 1 row(s)
新建一张teacher 表:
hive> create table teacher(id bigint,name string) row format delimited fields terminated by '\t';
OK
Time taken: 0.134 seconds
在本地建立文件teacher.txt,字段之间用tab分割(tab即是\t)
1 赵老师
2 王老师
3 刘老师
4 邓老师
加载数据
hive> load data local inpath '/Users/chenghengchao/teacher.txt' into table teacher;
Loading data to table default.teacher
OK
Time taken: 0.297 seconds
查询数据
hive> select * from teacher;
OK
1 赵老师
2 王老师
3 刘老师
4 邓老师
Time taken: 0.093 seconds, Fetched: 4 row(s)
6.hive 数据表与元数据的关系
在搭建hive环境的时候,我们使用的是MySQL数据库存储元数据。再创建一张表people。现在一共有三张表。
hive> create table people (id int,name string);
OK
Time taken: 0.073 seconds
hive> show tables;
OK
people
student
teacher
Time taken: 0.074 seconds, Fetched: 3 row(s)
打开本地的mysql数据库,metastore 数据库存储了hive表相关的信息。
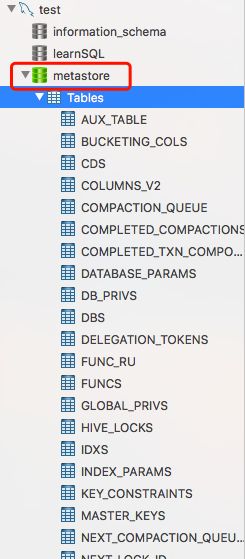
我们建立的表存放在TBLS表中。

表的字段存放在COLUMNS_V2表中。

数据在HDFS上的路径存放在SDS表中。

在文件系统中也是可以看到的:
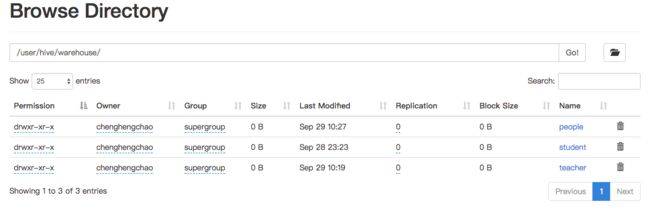
- 查询所有数据不涉及计算,只需查询出来就行了,因此不需要启动MapReduce
(即select * 不会启动MapReduce)
如果是count,sum等涉及到计算的操作就会启动MapReduce了。
8.表的类型有两种MANAGED_TABLE和EXTERNAL_TABLE,可以在TBLS中查看,也可以用desc 表名查看。 - 在hive下可以直接操作HDFS
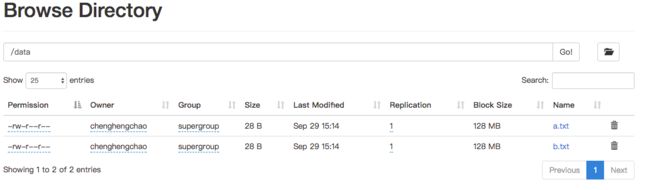
# 在hive下直接操作HDFS,建立data文件夹并上传本地文件到HDFS,命名为a.txt 和b.txt
hive> dfs -mkdir /data;
hive> dfs -put /Users/chenghengchao/student.txt /data/a.txt;
hive> dfs -put /Users/chenghengchao/student.txt /data/b.txt;
可以在HDFS中验证一下:
10.创建外部表并指向已有的data目录
hive> create external table ext_student(id bigint,name string) row format delimited fields terminated by '\t' location '/data';
OK
Time taken: 0.064 seconds
hive> select * from ext_student;
OK
1 zhangsan
2 lisi
3 wangwu
NULL NULL
1 zhangsan
2 lisi
3 wangwu
NULL NULL
Time taken: 0.076 seconds, Fetched: 8 row(s)
查询结果显示了8条记录,前4条和后4条是一样的。这是因为/data 下面有两个文件a.txt 和b.txt,每个文件有4行,其中3行有数据,最后一行为空。
如果再创建一个文件pep.txt,内容如下,并把它上传至/data目录下。
100 aaa
101 bbb
查询之后发现有10条记录了,即/data下3个文件的内容加到一起。
hive> dfs -put /Users/chenghengchao/pep.txt /data/pep.txt;
hive> select * from ext_student;
OK
1 zhangsan
2 lisi
3 wangwu
NULL NULL
1 zhangsan
2 lisi
3 wangwu
NULL NULL
100 aaa
101 bbb
Time taken: 0.085 seconds, Fetched: 10 row(s)
无论是外部表还是内部表,只要把某个文件放到表的目录下,就会被扫描并被查询出来。查询的执行过程是先通过TBLS表找到student表,然后根据表id到COLUMNS_V2表查找这张表都有哪些字段,然后再根据表id到SDS表中查找应该到HDFS的那个目录下去查找数据
- hive分区表
分区最大的好处是提高查询的速度。
创建分区表:
hive> create external table beauties(id bigint,name string,age int) partitioned by (nation string) row format delimited fields terminated by '\t' location '/beauty';
OK
Time taken: 0.095 seconds
创建表的同时,也在HDFS中创建了目录/beauty
然后创建两个文件china.txt 和japan.txt并上传到HDFS中的/beauty下
hive> dfs -put /Users/chenghengchao/japan.txt /beauty;
hive> select * from beauties;
OK
Time taken: 0.121 seconds
查询发现并没有数据,这是因为没有上传到特定的分区。
hive> load data local inpath '/Users/chenghengchao/china.txt' into table beauties partition(nation='China');
Loading data to table learnhive.beauties partition (nation=China)
OK
Time taken: 0.994 seconds
hive> select * from beauties;
OK
1 赵薇 30 China
2 赵丽颖 29 China
3 赵雅芝 62 China
Time taken: 0.152 seconds, Fetched: 3 row(s)
按照分区上传后,查询有了结果,并且多了一列分区字段
此时,在HDFS中的多了一个nation=China文件夹,新上传的china.txt存在此文件夹下。
接下来如果手动创建notion=japan文件夹,并且上传japan.txt文件,再查询
hive> dfs -mkdir /beauty/nation=Japan;
hive> dfs -put /Users/chenghengchao/japan.txt /beauty/nation=Japan;
hive> select * from beauties;
OK
1 赵薇 30 China
2 赵丽颖 29 China
3 赵雅芝 62 China
Time taken: 0.167 seconds, Fetched: 3 row(s)
还是和之前的数据一样,这是因为元数据库中没有记录Japan这个分区。(看SBS表的话,只有notion=China的记录)
12 修改分区
hive> alter table beauties add partition(nation='Japan') location '/beauty/nation=Japan'
> ;
OK
Time taken: 0.207 seconds
hive> select * from beauties;
OK
1 赵薇 30 China
2 赵丽颖 29 China
3 赵雅芝 62 China
1 福原爱 30 Japan
2 井上航平 22 Japan
3 酒井法子 45 Japan
Time taken: 0.11 seconds, Fetched: 6 row(s)
查询结果多了Japan分区的数据,并且在元数据库中也能看到nation=Japan的记录。
13 使用分区查询数据
建立了分区之后,就能够使用where条件进行查询,并且查询效率将会提高
hive> select * from beauties where nation='China';
OK
1 赵薇 30 China
2 赵丽颖 29 China
3 赵雅芝 62 China
Time taken: 0.419 seconds, Fetched: 3 row(s)
hive> select * from beauties where nation='Japan';
OK
1 福原爱 30 Japan
2 井上航平 22 Japan
3 酒井法子 45 Japan
Time taken: 0.124 seconds, Fetched: 3 row(s)
以上是hive基础的一些学习!