一、业务场景
在广告追踪系统中,我们通过提供SDK给用户,把各种各样的用户数据采集到我们的服务器中,然后通过MR计算,统计各种输出。在本文中,笔者将抽取其中一种业务场景:计算用户留存和付费LTV。
为了计算以上两个指标,需要采集三类数据:账户的激活、在线、付费记录。其中用户留存和付费LTV的计算过程如下:
1、用户留存:把用户今天在线的数据,与一个月内的用户激活数据做对比,找出今天在线的用户,是在那天激活的,并计算出差别的天数,这就是用户留存的计算方法。
2、付费LTV:找出今天哪些用户付费了,把这些用户,与一个月内的用户激活数据做对比,找出今天付费的用户,是在那天激活的,并计算出差别的天数,然后把今天付费的总额,除以差别的天数,得出付费LTV。
出于对公司数据安全考虑,这里不会贴出任何数据和计算代码,只会把与Azkaban相关的job信息和思路写出来,读者可以作为参考。
二、处理思路
1、原始的用户数据是混合在一起的,都放在按天分区的hdfs的指定目录下,这样,我们就需要写一个作为数据清洗的MR类,把原始日志中的在线,激活,付费三类数据分别输出到独立的文件中。这在hadoopMR中可以通过输出文件后缀的方式进行区分。
2、完成第一步后,我们需要把三类数据分别进行统计,比如按照appid进行统计,币别需要转换,激活时间需要从时间戳转换为日期等步骤。
3、第三步就需要把这三类数据分别入库到hive中,供后面的hiveSQL进行join操作。
4、把在线数据与激活数据做join,得出用户留存;把付费数据与激活数据做join,得出付费LTV。这两类数据计算完成后,需要入库到新的表中。
5、最后在kylin中进行计算,用户就可以在kylin中查询统计结果了。
总的数据处理流程如下:
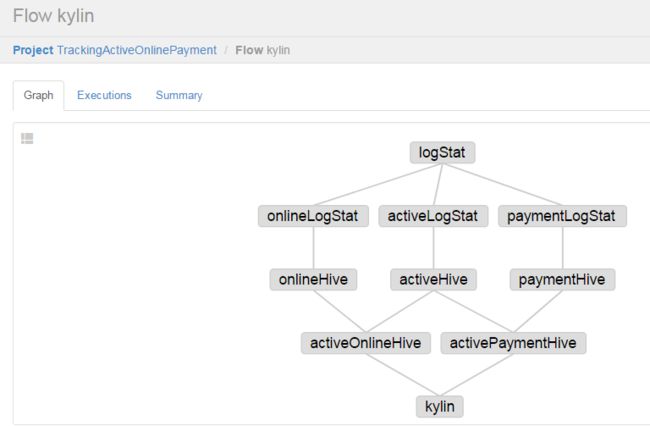
三、具体job编写
1、logStat.job:数据拆分
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
tmpjars=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/ad-tracker-mr2-1.0.0-SNAPSHOT-jar-with-dependencies.jar
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD-1}/*/input/self-event*
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat
calculate.date=all
job.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=com.dataeye.tracker.mr.common.SuffixMultipleOutputFormat
2、onlineLogStat.job:在线数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_ONLINE
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtOnlineLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
3、activeLogStat.job:激活数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_ACTIVE,/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD-1}/00/adtActiveLogStat
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtActiveLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
4、paymentLogStat.job:付费数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_PAYMENT
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtPaymentLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
5、onlineHive.job:在线数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_online.sql
dataPath=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtOnlineLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=onlineLogStat
hive_online.sql:
use azkaban;
load data inpath '${dataPath}' overwrite into table adt_logstat_online PARTITION(day_p='${day_p}');
6、activeHive.job:激活数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active.sql
dataPath=hdfs://de-hdfs/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtActiveLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=activeLogStat
hive_active.sql
use azkaban;
alter table adt_logstat_active_ext set location '${dataPath}';
INSERT overwrite TABLE adt_logstat_active PARTITION (day_p='${day_p}') SELECT appid,channel,compaign,publisher,site,country,province,city,deviceId,activeDate FROM adt_logstat_active_ext;
7、paymentHive.job:付费数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_payment.sql
dataPath=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtPaymentLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=paymentLogStat
hive_payment.sql
use azkaban;
load data inpath '${dataPath}' overwrite into table adt_logstat_payment PARTITION(day_p='${day_p}');
8、activeOnlineHive.job:用户留存统计
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active_online.sql
now_day=${DD:YYYY}-${DD:MM}-${DD:DD-1}
bef_day=${DD:YYYY}-${DD:MM}-${DD:DD-3}
dependencies=activeHive,onlineHive
hive_active_online.sql
use azkaban;
INSERT overwrite TABLE user_retain_roll PARTITION (day_p='${now_day}') SELECT av.appid as appid, ol.channel as channel,ol.compaign as compaign,ol.publisher as publisher,ol.site as site, count(av.deviceId) AS total FROM adt_logstat_online AS ol INNER JOIN adt_logstat_active AS av ON ol.deviceId = av.deviceId and ol.appid = av.appid WHERE ol.day_p = '${now_day}' AND av.activeDate BETWEEN '${bef_day}' AND '${now_day}' GROUP BY av.appid, ol.channel,ol.compaign,ol.publisher,ol.site,av.activeDate;
9、activePaymentHive.job:付费LTV统计
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active_payment.sql
now_day=${DD:YYYY}-${DD:MM}-${DD:DD-1}
bef_day=${DD:YYYY}-${DD:MM}-${DD:DD-3}
dependencies=activeHive,paymentHive
hive_active_payment.sql
use azkaban;
INSERT overwrite TABLE user_retain_ltv PARTITION (day_p='${now_day}') select av.appid as appid, py.channel as channel,py.compaign as compaign,py.publisher as publisher,py.site as site, py.deviceId as deviceId, py.paymentCount AS payment from adt_logstat_payment as py inner join adt_logstat_active as av on av.deviceId = py.deviceId and av.appid = py.appid where py.day_p = '${now_day}' and av.day_p = '${now_day}';
10、kylin.job:kylin计算
type=hadoopJava
job.extend=false
job.class=com.dataeye.kylin.azkaban.JavaMain
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
kylin.url=http://mysql8:7070/kylin/api
cube.name=user_retain_roll_cube,user_retain_ltv_cube
cube.date=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=activeOnlineHive,activePaymentHive
四、打包运行
打包过程与之前一致,最终的目录结构如下:
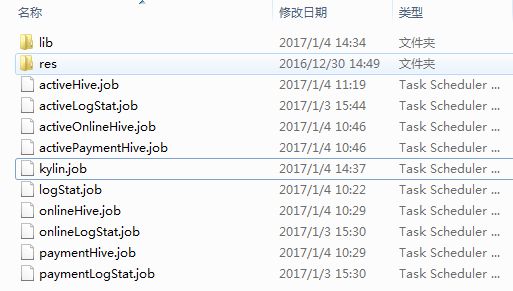
运行结果如下:
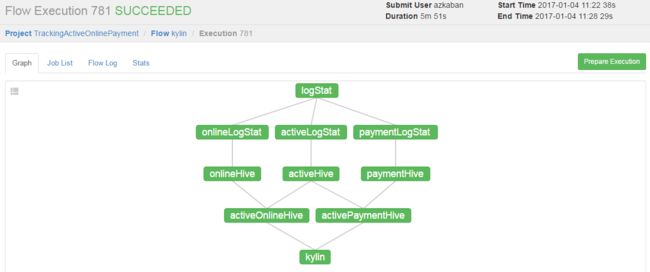
可以查看执行日志:
