1. HDFS优缺点
1.1 优点
1.1.1 高容错性
可以由数百或数千个服务器机器组成,每个服务器机器存储文件系统数据的一部分;
数据自动保存多个副本;
副本丢失后检测故障快速,自动恢复。
1.1.2 适合批处理
移动计算而非数据;
数据位置暴露给计算框架;
数据访问的高吞吐量;
运行的应用程序对其数据集进行流式访问。
1.1.3 适合大数据处理
典型文件大小为千兆字节到太字节;
支持单个实例中的数千万个文件;
10K+节点。
1.1.4 可构建在廉价的机器上
通过多副本提高可靠性;
提供了容错与恢复机制。
1.1.5 跨异构硬件和软件平台的可移植性强
轻松地从一个平台移植到另一个平台。
1.1.6 简单一致性模型
应用程序需要一次写入多次读取文件的访问模型;
除了追加和截断之外,不需要更改已创建,写入和关闭的文件;
简化了数据一致性问题,并实现了高吞吐量数据访问;
高度可配置,具有非常适合于许多安装的默认配置。大多数时候,只需要为非常大的集群调整配置。
1.2 缺点
1.2.1 不适合低延迟的数据访问
HDFS设计更多的是批处理,而不是用户交互使用。重点在于数据访问的高吞吐量,而不是数据访问的低延迟。
1.2.2 不适合小文件存取
占用NameNode大量内存;
寻道时间超过读取时间。
1.2.3 无法并发写入、文件随即修改
一个文件只能有一个写者;
仅支持追加和截断。
2. 基本组成
2.1 Namenode
2.1.1 接受客户端的读写服务
执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。
2.1.2 管理文件系统命名空间
记录对文件系统命名空间或其属性的任何更改。
2.1.3 metadata组成
Metadata是存储在Namenode上的元数据信息,它存储到磁盘的文件名为:fsimage。并且有个叫edits的文件记录对metadata的操作日志。总体来说,fsimage与edits文件记录了Metadata中的权限信息和文件系统目录树、文件包含哪些块、确定块到DataNode的映射、Block存放在哪些DataNode上(由DataNode启动时上报)。
NameNode将这些信息加载到内存并进行拼装,就成为了一个完整的元数据信息。
2.1.4 文件系统命名空间
HDFS支持传统的分层文件组织。用户或应用程序可以在这些目录中创建目录和存储文件。文件系统命名空间层次结构与大多数其他现有文件系统类似:可以创建和删除文件,将文件从一个目录移动到另一个目录,或重命名文件。HDFS支持用户配额和访问权限。但不支持硬链接或软链接。
NameNode维护文件系统命名空间。对文件系统命名空间或其属性的任何更改由NameNode记录。应用程序可以指定应由HDFS维护的文件的副本数。文件的副本数称为该文件的复制因子。此信息由NameNode存储。
2.1.5 文件系统元数据的持久性
NameNode的metadata信息在启动后会加载到内存,由于加载到内存的数据很不安全,断电后就没有了,因此必须对内存中存放的信息做持久化处理。
Namenode上保存着HDFS的命名空间。对于任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为Edits的事务日志记录下来。例如,在HDFS中创建一个文件,Namenode就会在Edits中插入一条记录来表示;同样地,修改文件的副本系数也将往Edits插入一条记录。Namenode在本地操作系统的文件系统中存储这个Edits。整个文件系统的命名空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在Namenode所在的本地文件系统上。
Namenode在内存中保存着整个文件系统的命名空间和文件数据块映射(Blockmap)的映像。这个关键的元数据结构设计得很紧凑,因而一个有4G内存的Namenode足够支撑大量的文件和目录。当Namenode启动时,它从硬盘中读取Edits和FsImage,将所有Edits中的事务作用在内存中的FsImage上,并将这个新版本的FsImage从内存中保存到本地磁盘上,然后删除旧的Edits,因为这个旧的Edits的事务都已经作用在FsImage上了。这个过程称为一个检查点(checkpoint)。
Datanode将HDFS数据以文件的形式存储在本地的文件系统中,它并不知道有关HDFS文件的信息。它把每个HDFS数据块存储在本地文件系统的一个单独的文件中。Datanode并不在同一个目录创建所有的文件,实际上,它用试探的方法来确定每个目录的最佳文件数目,并且在适当的时候创建子目录。在同一个目录中创建所有的本地文件并不是最优的选择,这是因为本地文件系统可能无法高效地在单个目录中支持大量的文件。当一个Datanode启动时,它会扫描本地文件系统,产生一个这些本地文件对应的所有HDFS数据块的列表,然后作为报告发送到Namenode,这个报告就是块状态报告。
2.2 SecondaryNameNode
它不是NameNode的备份,但可以作为NameNode的备份,当因为断电或服务器损坏的情况,可以用SecondNameNode中已合并的fsimage文件作为备份文件恢复到NameNode上,但是很有可能丢失掉在合并过程中新生成的edits信息。因此不是完全的备份。
由于NameNode仅在启动期间合并fsimage和edits文件,因此在繁忙的群集上,edits日志文件可能会随时间变得非常大。较大编辑文件的另一个副作用是下一次重新启动NameNode需要更长时间。SecondNameNode的主要功能是帮助NameNode合并edits和fsimage文件,从而减少NameNode启动时间。
2.2.1 SNN执行合并时机
根据配置文件配置的时间间隔fs.checkpoint.period默认1小时;
dfs.namenode.checkpoint.txns,默认设置为1百万,也就是Edits中的事务条数达到1百万就会触发一次合并,即使未达到检查点期间。
2.2.2 SNN合并流程
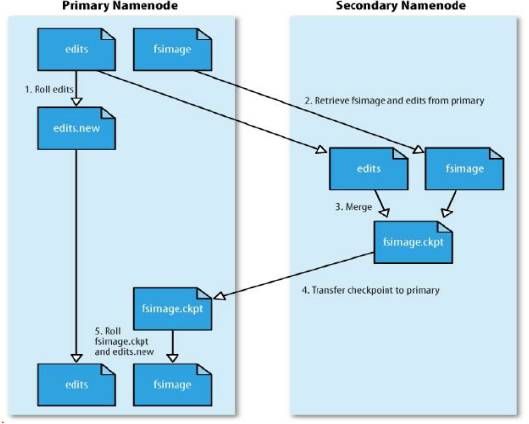
首先生成一个名叫edits.new的文件用于记录合并过程中产生的日志信息;
当触发到某一时机时(时间间隔达到1小时或Edits中的事务条数达到1百万)时SecondaryNamenode将edits文件、与fsimage文件从NameNode上读取到SecondNamenode上;
将edits文件与fsimage进行合并操作,合并成一个fsimage.ckpt文件;
将生成的合并后的文件fsimage.ckpt文件转换到NameNode上;
将fsimage.ckpt在NameNode上变成fsimage文件替换NameNode上原有的fsimage文件,并将edits.new文件上变成edits文件替换NameNode上原有的edits文件。
SNN在hadoop2.x及以上版本在非高可用状态时还存在,但是在hadoop2.x及以上版本高可用状态下SNN就不存在了,在hadoop2.x及以上版本在高可用状态下,处于standby状态的NameNode来做合并操作。
2.3 DataNode
管理附加到它们运行的节点的存储,并允许用户数据存储在文件中;
在内部,文件被分割成一个或多个块(Block),并且这些块被存储在一组DataNode中;
负责提供来自文件系统客户端的读取和写入请求;
执行块创建,删除;
启动DN进程的时候会向NN汇报Block信息;
通过向NN发送心跳保持与其联系(3秒一次),如果NN10分钟没有收到DN的心跳,则认为DN已经丢失,并且复制其上的Block到其他的DN上。
2.3.1 HDFS存储单元(block)
2.3.1.1文件被切分成固定大小的数据块
默认数据块大小为64MB(hadoop1.x)、128MB(hadoop2.x)、256MB(hadoop3.x),可配置;
若文件大小不到一个块大小,则单独存成一个block,block块是一个逻辑意义上的概念。文件大小是多少,就占多少空间。
2.3.1.2 一个文件存储方式
按大小被切分成不同的block,存储到不同的节点上;
默认情况下,每个block都有3个副本;
block大小与副本数通过client端上传文件时设置,文件上传成功后副本数可以变更,block size不可变更。
2.3.1.3 设计思想
将大文件拆分成256MB的block块,每个block块分别随机存放在不同的节点上,从而避免了数据倾斜的问题,但是在开发过程中,如果算法、程序写的不好,同样也会出现数据倾斜的问题。
2.3.2 数据复制
2.3.2.1 数据复制概述
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,除了最后一个,所有的数据块都是同样大小的。为了容错,文件的所有数据块都会有副本。每个文件的数据块大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
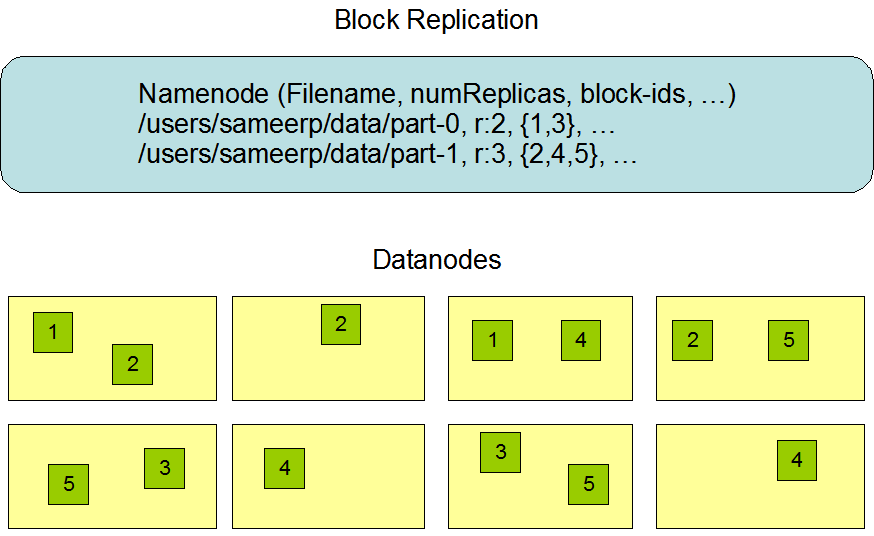
2.3.2.2 Block的副本放置策略
副本的存放是HDFS可靠性和性能的关键。优化的副本存放策略是HDFS区分于其他大部分分布式文件系统的重要特性。这种特性需要做大量的调优,并需要经验的积累。HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。目前实现的副本存放策略只是在这个方向上的第一步。实现这个策略的短期目标是验证它在生产环境下的有效性,观察它的行为,为实现更先进的策略打下测试和研究的基础。
大型HDFS实例一般运行在跨越多个机架的计算机组成的集群上,不同机架上的两台机器之间的通讯需要经过交换机。在大多数情况下,同一个机架内的两台机器间的带宽会比不同机架的两台机器间的带宽大。
通过一个机架感知的过程,Namenode可以确定每个Datanode所属的机架id。一个简单但没有优化的策略就是将副本存放在不同的机架上。这样可以有效防止当整个机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带宽。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效情况下的负载均衡。但是,因为这种策略的一个写操作需要传输数据块到多个机架,这增加了写的代价。
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。这种策略减少了机架间的数据传输,这就提高了写操作的效率。机架的错误远远比节点的错误少,所以这个策略不会影响到数据的可靠性和可用性。于此同时,因为数据块只放在两个(不是三个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之二的副本在一个机架上,其他副本均匀分布在剩下的机架中,这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
2.3.2.3 副本选择
为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
2.3.2.4 安全模式
NameNode在启动的时候会进入一个称为安全模式的特殊状态,它首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作;
一旦在内存中成功建立文件系统元数据映射,则创建一个新的fsimage文件(这个操作不需要SecondNameNode来做)与一个空的编辑日志;
此刻namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的,显示目录、显示文件内容等,写、删除、重命名都会失败;
在此阶段namenode搜集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的,在一定比例的数据块被认为是安全的以后(可设置),再过若干时间,安全模式结束;
当检测到副本数不足数据块时,该块会被复制,直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。