第2章 创建数据集
2.1 数据集的概念
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
不同行业对数据集的行和列的叫法不同。
统计学家称它们为观测(observation)和变量(variable)
数据库分析师称为记录(record)和字段(field)
数据挖掘/机器学习学科的研究者则把他们称为示例(example)和属性(attribute)
2.2 数据结构

2.2.1 向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c( )可用来创建向量。
> a <- c(1, 2, 5, 3, 6, -2, 4) #数值型向量
> b <- c("one", "two", "three") #字符型向量
> d <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE) #逻辑型向量
> a
[1] 1 2 5 3 6 -2 4
> b
[1] "one" "two" "three"
> d
[1] TRUE TRUE TRUE FALSE TRUE FALSE
> a[c(2, 3)] #访问元素
[1] 2 5
单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。
标量是只含一个元素的向量,用于保存常量。
2.2.2 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过matrix创建矩阵。
代码清单2-1 创建矩阵
> y <- matrix(1:20, nrow=5, ncol=4) #创建5*4矩阵
> y
[,1] [,2] [,3] [,4]
[1,] 1 6 11 16
[2,] 2 7 12 17
[3,] 3 8 13 18
[4,] 4 9 14 19
[5,] 5 10 15 20
> cells <- c(1, 26, 24, 68)
> rnames <- c("R1", "R2") #行名
> cnames <- c("C1", "C2") #列名
> mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=TRUE, dimnames=list(rnames, cnames)) #创建2*2矩阵,行名rnames,列名cnames,按行填充
> mymatrix
C1 C2
R1 1 26
R2 24 68
> mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=FALSE, dimnames=list(rnames, cnames))
> mymatrix
C1 C2
R1 1 24
R2 26 68
**代码清单2-2 矩阵下标的使用
> x <- matrix(1:10, nrow=2)
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> x[2,]
[1] 2 4 6 8 10
> x[,2]
[1] 3 4
> x[1,4]
[1] 7
> x[1,c(4,5)] #第1行的4、5列
[1] 7 9
2.2.3 数组
数组(array)与矩阵类似,但是纬度可以大于2.数组通过array函数创建。
代码清单2-3 创建一个数组
> dim1 <- c("A1", "A2")
> dim2 <- c("B1", "B2", "B3")
> dim3 <- c("C1", "C2", "C3", "C4") #纬度
> z <- array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
>
以上是2×3×4三维数值型数组示例。从数组中选取元素的方式与矩阵相同。元素z[1, 2, 3]为15。
2.2.4 数据框
不同的列可以包含不同模式(数值型、字符型等)的数据,与SAS、SPSS和Stata中看到的数据集类似。数据框将是R中最常处理的数据结构。
数据框可通过函数data.frame( )创建。
代码清单2-4 创建一个数据框
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type2")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> patientdata <- data.frame(patientID, age, diabetes, status)
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type2 Poor
代码清单2-5 选取数据框中的元素
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type2 Poor
> patientdata[1:2]
patientID age
1 1 25
2 2 34
3 3 28
4 4 52
> patientdata[c("diabetes", "status")]
diabetes status
1 Type1 Poor
2 Type2 Improved
3 Type1 Excellent
4 Type2 Poor
> patientdata$age
[1] 25 34 28 52
每次定位变量名键入patientdatas$很麻烦,可以使用attach( )、detach( )和with( )简化代码。
函数attach( )将数据框添加到R的搜索路径中,R遇到一个变量名以后,将检查搜索路径中的数据框,以定位到变量。
函数detach( )将数据框从搜索路径中移除,但不会对数据本身做任何处理。
> summary(mtcars$mpg)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.42 19.20 20.09 22.80 33.90
> plot(mtcars$mpg, mtcars$disp)
> plot(mtcars$mpg, mtcars$wt)
> #以上代码可简化为
> attach(mtcars)
> summary(mpg)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.42 19.20 20.09 22.80 33.90
> plot(mpg, disp)
> plot(mpg, wt)
> detach(mtcars)
数据框mtcars被绑定(attach)之前,如果环境中已有名为mpg的对象,这种情况下,原始对象将取得优先权,造成结果错误。
可以使用函数with( )。
with(mtcars, {summary(mpg, disp, wt) plot(mpg, disp) plot(mpg, wt)})
这种情况下,大括号{}之间的语句都针对数据框mtcars执行。
函数with( )的局限性在于,赋值仅在此函数的括号内生效。需要使用特殊赋值符<<-。
> with(mtcars, {
+ summary(mpg, disp, wt)
+ plot(mpg, disp)
+ plot(mpg, wt)
+ })
> with(mtcars, {
+ nokeepstats <- summary(mpg)
+ keepstats <<- summary(mpg)
+ })
> nokeepstats
错误: 找不到对象'nokeepstats'
> keepstats
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.42 19.20 20.09 22.80 33.90
- 实例标识符
病例数据中,病人编号(pathentID)用于区分数据集中不同的个体。在R中,实力标识符(case identifier)可通过数据框操作函数中的rowname选项指定。例如:
> patientdata <- data.frame(patientID, age, diabetes, status, row.names=patientID)
将patientID指定为R中标记各类打印输出和图形中实例名称所用的变量。
2.2.5 因子
变量归结为名义型、有序型或连续型变量。名义型变量是没有顺序之分的类别变量。
糖尿病类型Diabetes(Type1、Type2)是名义型变量的一例。即便数据中Type1编码有数字,也不意味二者是有序。
病情Status(poor,improved,excellent)是顺序型变量的一个示例。
年龄age是一个连续型变量。
类别(名义型)变量和有序类别(有序型)变量在R中成为因子(factor)。因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。
函数facor( )以一个整数向量的形式存储类别值,整数的取值范围是[1...k](其中k是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量映射到这些整数上。
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> diabetes <- factor(diabetes)
> status <- c("Poor", "Improved", "Excellent", "Poor")
> status <- factor(status, ordered=TRUE) #order=TRUE,表示有序变量。
对于字符型变量,因子的水平默认依字母顺序创建。默认的字母顺序与实际不符时,通过制定levels选项覆盖默认序列。例如:
`status <- factor(status, order=TRUE, levels=c("Poor", "Improved", "Excellent"))
将赋值为1=Poor、2=Improved、3=Excellent。注意保证制定水平与数据中的真实值相匹配,任何未出现在参数中列举的数据都被视为缺失值。
代码清单2-6 因子的使用
> patientID <- c(1, 2, 3, 4) #以向量形式输入数据
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> diabetes <- factor(diabetes)
> status <- factor(status, order=TRUE)
> patientdata <- data.frame(patientID, age, diabetes, status) #组合为数据框
> str(patientdata) #显示对象结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 2 1 3
> summary(patientdata) #显示对象的统计摘要
patientID age diabetes status
Min. :1.00 Min. :25.00 Type1:3 Excellent:1
1st Qu.:1.75 1st Qu.:27.25 Type2:1 Improved :1
Median :2.50 Median :31.00 Poor :2
Mean :2.50 Mean :34.75
3rd Qu.:3.25 3rd Qu.:38.50
Max. :4.00 Max. :52.00
2.2.6 列表
列表(list)是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分component)的有序集合。列表允许你整合若干(可能无关的)对象到单个对象名下。例如,某个列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list( )创建列表:mylist <- list(object1, object2, ...)
其中的对象可以是目前为止的任何结构。还可以为列表中的对象命名:
mylist <- lsit(name1=object1, name2=object2, ...)
代码清单2-7 创建一个列表
> g <- "My First List"
> h <- c(25, 26, 18, 39)
> j <- matrix(1:10, nrow=5)
> k <- c("one", "two", "three")
> mylist <- list(title=g, ages=h, j, k)
> mylist
$title
[1] "My First List"
$ages
[1] 25 26 18 39
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
[[4]]
[1] "one" "two" "three"
> mylist[2]
$ages
[1] 25 26 18 39
> mylist["ages"]
$ages
[1] 25 26 18 39
本例创建了一个列表,其中有四个成分:一个字符串、一个数值型向量、一个矩阵以及一个字符型向量。可以组合任意多的对象,并将它们保存为一个列表。
列表是R中重要的数据结构。首先,列表允许以一种简单的方式组织和重新调用任何不相干的信息。其次,许多R函数的运行结构都是以列表的形式返回的。需要取出哪些成份由分析人员决定。
- $ 意为指定一个对象中的某些部分。例如,A$x是指数据框A中的变量x。
- R不提供多行注释。
if(FALSE){ ... }可以是解释器忽略括号中代码。FALSE改为TRUE则允许这块代码执行。调试代码时有用。 - R中的下标不从0开始,而从1开始。
2.3 数据的输入
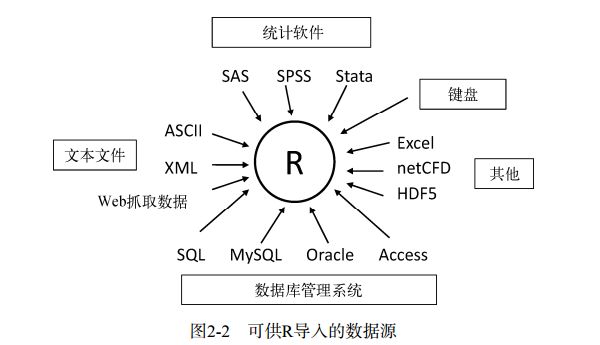
2.3.1使用键盘输入数据
R中的函数edit( )会自动调用一个允许手动输入数据的文本编辑框。
> mydata <- data.frame(age=numeric(0), gender=character(0), weight=numeric(0)) #创建三个变量 age、gender、weigth
> mydata <- edit(mydata) #调用文本编辑器,键入数据
注:numeric指字段是数字型
2.3.2 从带分隔符的文本文件导入数据
read.table( )从带分隔符的文本文件导入数据。语法如下:
mydataframe <- read.table(file, header=logical_value, sep="delimiter", row.names="name")
file是一个带分隔符的ASCII文本文件,header是一个表明首行是否包含了变量名的逻辑值(TRUE / FALSE),sep用来指定分隔数据的分隔符,row.names是一个可选参数,用以指定一个或多个表示行标识符的变量。
例如:
grades <- read.table("studentgrades.csv", header=TRUE, sep=",", row.names="STUDENTID")
从当前目录中读入一个名为studentgrades.csv的逗号分隔文件,从文件的第一行取得各变量的名称,将变量STUDENTID指定为行标识符,最后将结果保存到了名为grades的数据框中。
参数sep允许导入使用逗号以外的符号来分隔行内数据的文件。
2.3.3 导入Excel数据
读取Excel文件的最好方式,将Excel导出为逗号分隔文件(csv),并使用前文描述的方式将其导入R中。
在Windows系统中,也可以使用RODBC包来访问Excel文件。
xlsx包和rJava包,可以直接导入xlsx数据。确保Java版本与R版本匹配。
2.3.4 导入XML数据
R中有若干处理XML文件的包。
2.3.5 从网页抓取数据
使用函数readLines( )下载网页,然后使用如grep( )和gsub( )一类的函数处理它。对于结构复杂的网页,可以使用RCurl包和XML包来提取想要的信息。
2.3.6 导入SPSS数据
2.3.7 导入SAS数据
2.3.8 导入Stata数据
2.3.9 导入netCDF数据
2.3.10 导入HDF5数据
2.3.11 访问数据库管理系统
2.3.12 通过Stat/Transfer导入数据
2.4 数据集的标注
为使结果更易阶段,数据分析人员通常会对数据集进行标注。
标注包括为变量名添加描述性的标签,以及为类别型变量中的编码添加值标签。
例如:对于变量age,附加一个描述更详细的标签“Age at hospitalization(in years)”(入院年龄)。对于编码1或2的性别变量gender,关联到标签"male"和"female"上。
2.4.1 变量标签
R处理变量标签的能力有限。一种解决方法是将变量标签作为标量名,通过位置下标来访问这个变量。
在变量名太长时不适合重复输入。
2.4.2 值标签
函数factor( )可为类别型变量创建值标签。假设有一个gender的变量,1表示男性,2表示女性。可以使用代码:
patientdata$gender <- factor(patientdata$gender, levels = c(1, 2), labels = c("male", "female"))
来创建标签,levels代表变量的实际值,labels表示包含了理想值标签的字符型向量。
2.5 处理数据对象的实用函数
| 函数 | 用途 |
|---|---|
| length(object) | 显示对象中元素/成分的数量 |
| dim(object) | 显示某个对象的维度 |
| str(object) | 显示某个对象的结构 |
| class(object) | 显示某个对象的类或类型 |
| mode(object) | 显示某个对象的模式 |
| names(object) | 显示某对象中各成分的名称 |
| c(object, object, ...) | 将对象合并如一个向量 |
| cbind(object, object, ...) | 按列合并对象 |
| rbind(object, object, ...) | 按行合并 |
| object | 输出某个对象 |
| head(object) | 列出某个对象的开始部分 |
| tail(object) | 列出某个对象的最后部分 |
| ls | 显示当前的对象列表 |
| rm(object, object, ...) | 删除一个或更多个对象。rm(list = ls())除当前工作环境中所有对象,.开头的隐藏对象不受影响 |
| newobject <- edit(object) | 编辑对象并另存为newobject |
| fix(object) | 直接编辑对象 |
2.6 小结
向量、矩阵、数据库和列表的概念在后续章节反复使用。掌握通过括号表达式选取元素的能力,对数据的选择、取子集和变换将是非常重要的。
——2017.2.12
——于家中