第1章 新手上路
自然语言处理是一门融合了计算机科学、人工智能以及语言学的交叉学科。这门学科研究的是如何通过机器学习等技术,让计算机学会处理人类语言,乃至实现终极目标----理解人类语言或人工智能。
自然语言处理这个术语没有被广泛的定义,注重语言学结构的学者喜欢使用计算语言学(CL),强调最终目的的学者更偏好自然语言理解(NLU)。
1.1 自然语言与编程语言
1.1.1 词汇量
自然语言中的词汇比编程语言中的关键词丰富。编程语言中,能使用的关键词数量有限且确定,比如,C语言一共有32个关键词,Java语言则有50个。但在自然语言中,我们可以使用的词汇量是无穷无尽的。
1.1.2 结构化
自然语言是非结构化的,而编程语言是结构化的。结构化是指信息具有明确的结构关系,比如编程语言中的类与成员、数据库的表与字段,而自然语言中则不存在这样的显式结构。
人类觉得很简单的一句话,要让计算机理解起来并不简单。
1.1.3 歧义性
自然语言含有大量歧义,而在编程语言中,则不存在歧义性。
1.1.4 容错性
自然语言中允许有错误,哪怕一句话错得再离谱,人们还是可以猜出它想表达的意思。而编程语言必须保证拼写绝对正确、语法绝对规范。
1.1.5 易变性
自然语言不是由某个个人或组织发明或制定标准的。编程语言由某个个人或组织发明并且负责维护。
1.1.6 简略性
人类语言往往简洁、干练。这也给自然语言处理带来了障碍。
1.2 自然语言处理的层次
1.2.1 语音、图像和文本
自然语言处理系统的输入源一共有3个,即语音、图像与文本。语音和图像受制于存储容量和传输速度,它们的信息总量还是没有文本多。
1.2.2 中文分词、词性标注和命名实体识别
这3个任务都是围绕词语进行的分析,所以统称词法分析。
1.2.3 信息抽取
1.2.4 文本分类与文本聚类
文本分类:有时我们想知道一段话是褒义还是贬义的,判断一封邮件是否是垃圾邮件,想把许多文档分门别类地整理一下,此时的任务称作文本分类。
文本聚类:有时只想把相似的文本归档到一起,或者排除重复的文档,而不关心具体类别。此时的任务称作文本聚类。
1.2.5 句法分析
1.2.6 语义分析与篇章分析
语义分析侧重语义而非语法。它包括词义消歧、语义角色标注乃至语义依存分析。本书不会涉及
1.2.7 其他高级任务
自动问答:微软的Cortana和苹果的Siri
自动摘要:为一篇长文档生成简短的摘要
机器翻译:将一句话从一种语言翻译到另一种语言。
1.3 自然语言处理的流派
1.3.1 基于规则的专家系统
规则,指的是由专家手工制定的确定性流程。专家系统要求设计者对所处理的问题具备深入的理解,并且尽量以人力全面考虑所有可能的情况。最大的弱点是难以拓展。
1.3.2 基于统计的学习方法
为了降低对专家的依赖,人们使用统计方法让计算机自动学习语言。所谓“统计”,指的是在语料库上进行的统计。语料库则是人工标注的结构化文本。
1.3.3 历史
1950基础研究----1980规则系统----1990统计方法------2010深度学习
1.3.4 规则与统计
随着机器学习的日渐成熟,领域专家的作用越来越小了。
本书尊重工程实践,以统计为主、规则为辅的方式介绍实用型NLP系统的搭建。
1.3.5 传统方法与深度学习
深度学习在自然语言处理领域中的基础任务上发力并不大。
1.4 机器学习
1.4.1 什么是机器学习
人工智能领域的先驱Arthur Samuel在1959年给出的机器学习定义是:不直接编程却能赋予计算机提高能力的方法。
机器学习是让机器学会算法的算法。机器学习算法则可以称作“元算法”,它指导机器自动学习出另一个算法,这个算法被用来解决实际问题。
1.4.2 模型
模型是对现实问题的数学抽象,由一个假设函数以及一系列参数构成。
假设需要预测中国人名对应的性别,假设中国人名由函数f(x)输出的符号决定,负数表示女性,非负数表示男性。
f(x) = w* x + b
w和b是函数的参数,而x是函数的自变量。
1.4.3 特征
特征指的是事物的特点转化的数值,比如牛的特征是4条腿、0双翅膀,而鸟的特征是2条腿、1双翅膀。
特征工程:如何挑选特征,如何设计特征模版。
1.4.4 数据集
如何让机器自动学习,以得到模型的参数呢?首先得有一本习题集。这本习题集在机器学习领域称作数据集,在自然语言处理领域称作语料库。
1.4.5 监督学习
如果习题集附带标准答案y,则此时的学习算法称作监督学习。这种在有标签的数据集上迭代学习的过程称为训练,训练用到的数据集称作训练集。
1.4.6 无监督学习
如果只给机器做题,不告诉它参考答案,此时的学习称作无监督学习。无监督学习一般用于聚类和降维,两者都不需要标注数据。
1.4.7 其他类型的机器学习算法
半监督学习:训练多个模型,然后对同一个实例进行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来扩充数据集。
强化学习:一边预测,一边根据环境的反馈规划下次决策。
1.5 语料库
1.5.1 中文分词语料库
语料规范很难制定,规范很难执行。
1.5.2 词性标注语料库
1.5.3 命名实体识别语料库
1.5.4 句法分析语料库
1.5.5 文本分类语料库
1.5.6 语料库建设
1.6 开源工具
1.6.1 主流NLP工具比较
HanLP开发者写的书,你懂得,HanLP是发展最迅猛的!
1.6.2 Python接口
HanLP的安装:
pip install pyhanlp
1.7 总结
本章给出了人工智能、机器学习与自然语言处理的宏观缩略图与发展时间线。在接下来的章节中,将由易到难去解决第一个NLP问题----中文分词。
写一下运行书上代码踩到的坑,试了好久终于跑通了。。。。
系统:win10,软件:Eclipse,java版本jdk1.8
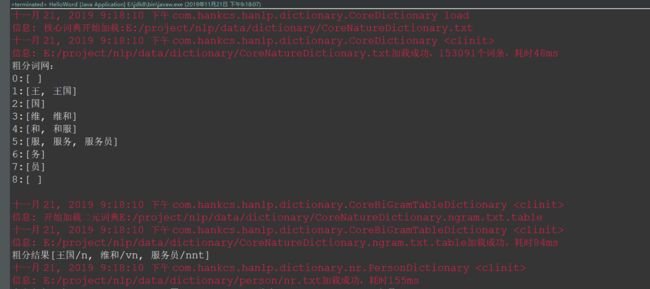
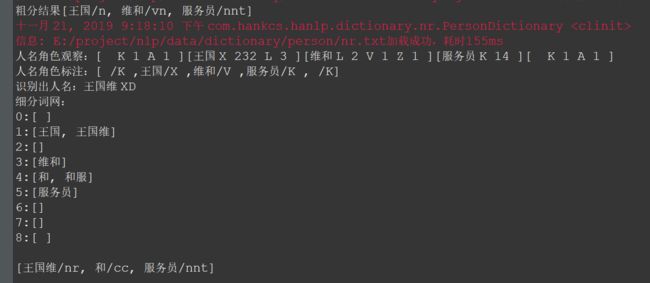
/* *Han He *[email protected] *2018-05-18 下午5:38 * ** Copyright (c) 2018, Han He. All Rights Reserved, http://www.hankcs.com/ * This source is subject to Han He. Please contact Han He for more information. * */ package com.hankcs.book.ch01; import com.hankcs.hanlp.HanLP; /** * 《自然语言处理入门》1.6 开源工具 * 配套书籍:http://nlp.hankcs.com/book.php * 讨论答疑:https://bbs.hankcs.com/ * * @author hankcs * @see 《自然语言处理入门》 * @see 讨论答疑 */ public class HelloWord { public static void main(String[] args) { HanLP.Config.enableDebug(); // 首次运行会自动建立模型缓存,为了避免你等得无聊,开启调试模式说点什么:-) System.out.println(HanLP.segment("王国维和服务员")); } }
在图灵社区下载的源码 https://www.ituring.com.cn/book/2706 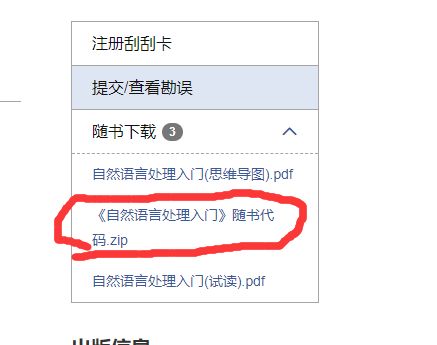
下载后解压,在Eclipse中创建项目,项目名称为nlp,找到项目目录,将解压出的 com 文件夹复制进src目录中,解压路径为
《自然语言处理入门》随书代码\hanlp-java\HanLP\src\main\java\com
将解压出的data文件夹复制到与src的同级目录,解压路径为
《自然语言处理入门》随书代码\hanlp-java\HanLP\data
bin文件夹中放入hanlp.properties配置文件,下载地址:https://github.com/hankcs/HanLP,配置hanlp.properties第一行为data文件夹路径,不要写data
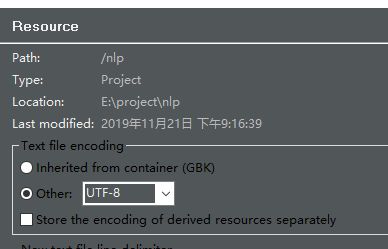
刷新项目,若出现中文乱码问题则右键项目,properties--resource--Text file encoding改为UTF-8,运行成功