现代神经网络依靠反向传播(Back Propogation)算法来对模型进行优化,其本质是大规模链式求导。因此,能够对通过编程来对网络参数进行求导是非常重要的。目前的深度学习框架神经网络如PyTorch和TensorFlow等都实现了自动求梯度的功能。
计算图
计算图(Computation Graph)是现代深度学习框架的核心,其为高效自动求导算法——反向传播(Back Propogation)提供了理论支持。如下所示,计算图是一种特殊的有向无环图(DAG),用于记录算子与变量之间的关系。
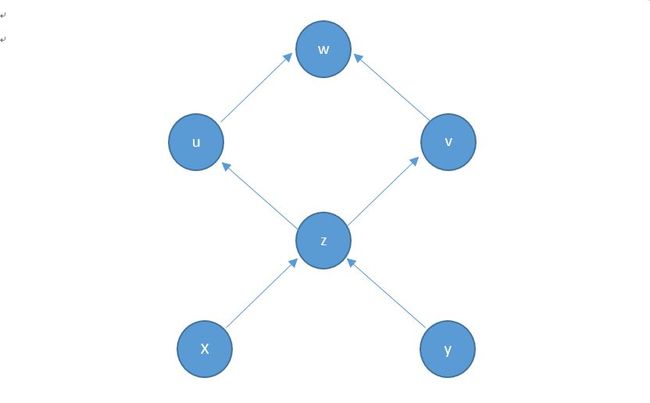
计算图具有两个优势:
a. 使用非常简单的函数就可以组合成一个极其复杂的模型;
b. 可以实现自动微分。
在PyTorch中,通过记录算子与变量之间的关系可以生成表达式对应的计算图。对于表达式y = wx + b,其中w、x和b是变量,+和=是算子。有DAG中,w、x和b是叶子节点(leaf node),这些节点通常由用户自己创建,不依赖于其他变量。y称为根节点,是计算图的最终目标。
>>> x = torch.ones(2, 2)
>>> w = torch.rand(2, 2, requires_grad=True)
>>> b = torch.rand(2, 2, requires_grad=True)
>>> y = w * x + b
>>> x.is_leaf, w.is_leaf, b.is_leaf
(True, True, True)
>>> y.is_leaf
False
>>>
自动求导
在创建tensor的时候指定requires_grad参数或者使用requires_grad_()函数来指定是否对该参数进行自动求导。
>>> x = torch.ones(2, 2)
>>> w = torch.rand(2, 2, requires_grad=True)
>>> b = torch.rand(2, 2, requires_grad=True)
>>> y = w * x + b
x.requires_grad未指定自动求导,因此是False,w.requires_grad和b.requires_grad为我们的求导对象,因此是True。虽然未指定y.requires_grad为True,但由于y依赖于需要求导的w,因此y.requires_grad为True。
>>> x.requires_grad, b.requires_grad, w.requires_grad
(False, True, True)
>>> y.requires_grad
True
有了计算图之后,对根节点调用backward()函数进行反向传播,就能够得到各个需要求导的叶子的导数,通过grad属性即可得到。
>>> y = w * x + b
>>> y.backward()
Traceback (most recent call last):
File "", line 1, in
File "F:\ProgramData\Anaconda3\lib\site-packages\torch\tensor.py", line 102, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "F:\ProgramData\Anaconda3\lib\site-packages\torch\autograd\__init__.py", line 84, in backward
grad_tensors = _make_grads(tensors, grad_tensors)
File "F:\ProgramData\Anaconda3\lib\site-packages\torch\autograd\__init__.py", line 28, in _make_grads
raise RuntimeError("grad can be implicitly created only for scalar outputs")
RuntimeError: grad can be implicitly created only for scalar outputs
如果对非标量y求导,函数需要额外指定grad_tensors,grad_tensors的shape必须和y的相同。
>>> weights = torch.ones(2, 2)
>>> y.backward(weights, retain_graph=True)
>>> w.grad
tensor([[1., 1.],
[1., 1.]])
此外,PyTorch中梯度是累加的,每次反向传播之后,当前的梯度值会累加到旧的梯度值上。
>>> y.backward(weights, retain_graph=True)
>>> w.grad
tensor([[2., 2.],
[2., 2.]])
>>> y.backward(weights, retain_graph=True)
>>> w.grad
tensor([[3., 3.],
[3., 3.]])
要清空变量当前的梯度,可以使用zero()和zero_()函数。
>>> w.grad.zero_()
tensor([[0., 0.],
[0., 0.]])
>>> w.grad
tensor([[0., 0.],
[0., 0.]])
PS:在我们使用PyTorch构建网络时,Model会在反向传播时会自行处理梯度更新问题,上述知识有助于理解PyToch中的自动求导。