本文主要总结的内容如下:
- 一、语法
- 1、变量与命名
- 2、基本类型
- 3、数组
- 二、面向对象
- 1、特性
- 2、构造器
- 3、修饰符
- 4、equals方法
- 5、类/对象(数组、反射、接口、内部类、代理)
- 三、相关类/对象
- 1、字符串
- 2、集合
- 3、异常
- 4、泛型
阅读建议:
不要一下子全看完,这些总结是我几天分段总结的,可以分步阅读,如果在阅读过程中发现有不准确或错误的地方,希望可以多多指正批评,谢谢。
一、语法:
1、变量与命名:
1、Java变量命名严格区分大小写
2、每条语句必须用
;结束,回车不是语句的结束标志,如果需要,可以将一条语句写在多行上。3、Java中的注释不能嵌套。
4、Java是一种强类型语言,即每一个变量必须声明一种类型。
2、基本类型
-
1、各种数值类型的表示:
int a = 10; //int类型 long b = 10L; //long类型 float c = 10.0f, d = 10.0F; //float类型 double e = 10.0, f = 10.0d, g = 10.0D; //double类型注意:
如果float类型的值不加后缀F(或f),则默认为double类型
-
在JDK5.0中,可以使用十六进制表示浮点数值:
float p = 0x1.0p-3f; //0.125 在十六进制表示法中,使用p表示指数,而不是e,尾数采用十六进制,指数采用十进制,指数的基数是2,而不是10。
-
计算结果:
10 / 0 = 正无穷大 0 / 0 = NaN Math. sqrt(-10) = NaN
2、对于使用
strictfp关键字标记的方法,必须使用严格的浮点计算来产生理想的结果。如果将一个类标记为strictfp,则这个类中的所有方法都要使用严格的浮点计算。3、如果基本的证书和浮点数精度不能满足需求,可以使用
java.math包中的两个类(可以处理包含任意长度数组序列的数值):
BigInteger实现了任意精度的整数运算
BigDecimal实现了任意精度的浮点数运算
3、数组:
- 在创建数组时,数组长度不要求是常量,举个简单的例子如下:
public int[] createArr(int n) { return new int[n]; }
二、面向对象(OOP):
1、特性
1、封装给对象赋予了“黑盒”特征,这是提高复用性和可靠性的关键。
-
2、类之间的关系:
- 依赖(“uses-a”)
一个类A的方法操纵另一个类B的对象,则A类依赖于B类
要尽量降低类之间的耦合,即低耦合 - 聚合(“has-a”)
一个对象A包含一些另一个对象B - 继承(“is-a”)
表示特殊与一般的关系
- 依赖(“uses-a”)
3、面向对象的三个特征:封装性,继承性,多态性
2、构造器
-
1、方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型和布尔型)。
- 一个方法可以改变一个对象参数的状态。
- 一个方法不能让对象参数引用一个新的对象。
-
2、初始化数据域的方法:
- 在构造器中设置值
- 在声明中赋值
- 在初始化块中赋值
- 在静态的初始化块中赋值
public class ClassName { //在声明中赋值 private String name = "nameValue"; private int name1; private int[] name2; private static boolean name3; public ClassName(int name1) { //在构造器中设置值 this.name1 = name1; } { //在初始化块中赋值 name2 = new int[]{1, 2, 3}; } static { //在静态的初始化块中赋值 name3 = true; } } 3、调用构造器的具体处理步骤:
1). 所有数据域(字段)被初始化为默认值
2). 按照在类声明中出现的次序,依次执行所有域初始化语句和初始化块
3). 如果构造器第一行调用了第二个构造器,则执行第二个构造器主体
4). 执行这个构造器主体-
4、
super与this-
super:不是一个对象的引用,不能将super赋值给另一个对象变量,它只是一个只是编译器调用超类方法的 特殊关键字 。它有两个用途:
1.调用超类的方法
2.调用超类的构造器 -
this:表示当前对象的引用,可以赋值给另一个对象变量。它的两个用途:
1.引用隐式参数
2.调用该类其他的构造器
-
3、修饰符
-
1、
final修饰的变量只能赋值一次,但java.lang.System比较特殊,其中的setOut方法可以修改final变量的值,原因在于setOut是一个本地方法,而不是用Java语言实现的。
本地方法可以绕过Java语言的存储控制机制。public static void setOut(PrintStream out) { setOut0(out); } private static native void setOut0(PrintStream out);注意:
- 抽象类不能用final来修饰,即一个类不能既是最终类又是抽象类。
- 如果将一个类声明为final,只有其中的方法自动地成为final,而不包括域(字段)。
-
2、动态绑定与静态绑定
- 如果是private、static、final等修饰的方法或构造器,那么编译器将可以准确地知道应该调用哪个方法,此种调用方式称之为静态绑定(static bingding)。
- 调用方法依赖于隐式参数的实际类型,并且在运行时实现动态绑定。
4、equals方法
在使用
equals()方法进行两个对象的比较时,为了避免二者都可能为null的情况,需要使用Objects.equals(a, b)方法进行比较,此方法内部进行比较时,其中一个参数为null时,返回false,否则都不为null时,则进行a.equals(b)的比较。
注意:在比较两个枚举类型的值时,永远不需要调用equals方法,而直接使用==就可以了。Java语言规范要求
equals方法具有如下的特性:
1、自反性:对于任何非空引用x,x.equals(x)应该返回true。
2、对称性:对于任何引用x和y,当且仅当y.equals(x)返回true,x.equals(y)也应该返回true。
3、传递性:对于任何引用x,y和z,如果x.equals(y)返回true,y.equals(z)返回true,x.equals(z)也应该返回true。
4、一致性:如果x和y引用的对象没有发生变化,反复调用x.equals(y)应该返回同样的结果。
5、对于任意非空引用x,x.equals(null)应该返回false。
注意:如果隐式和显式参数不属于同一个类,当两个类是继承关系的时候,使用instanceof进行检测是否相等时,逻辑上就会出现问题,除非你能确保这种检测相等的方法是可行的,所以最好不要在重写equals方法时使用instanceof进行比较。如果重新定义
equals方法,就必须重新定义hashCode方法,以便用户可以将对象插入到散列表中。
5、类/对象
-
1、数组列表(集合)
- 如果对象中存在数组类型的域(属性),那么可以使用静态的
Arrays.hashCode方法计算一个散列码,这个散列码由数组元素的散列码组成。 - 菱形语法,即使用
<>的泛型类的语法:ArrayListnums = new ArrayList(); - 在Java SE 5.0以后的版本中,如果ArrayList没有后缀
<...>仍然可以使用,它将会被认为是一个删去了类型参数的原始类型。 - 数组列表的分配:
1、数组分配指定个数元素的存储空间后,数组就有指定个数的空位置可用
2、 数组列表(集合)分配指定个数元素后,只是有保存指定个数元素的潜力,但在最初甚至完成初始化构造之后,数组列表根本就不含有任何元素。ArrayListnumLists = new ArrayList<>(20); Integer[] nums = new Integer[20]; //listSize==>0 System.out.println("listSize==>" + numLists.size()); //arrSize==>20 其中的元素皆为默认值null System.out.println("arrSize==>" + nums.length); //nums[3]==>null System.out.println("nums[3]==>" + nums[3]);
- 如果对象中存在数组类型的域(属性),那么可以使用静态的
-
2、自动装箱规范要求
boolean、byte、chart<=127,-128<=short<=127,-128<=int<=127被包装到固定的对象中。Integer a = 1000; Integer b = 1000; Integer a1 = 111; Integer b1 = 111; //a==b? ===>false System.out.println("a==b? ===>" + (a==b)); //a1==b1? ===>true System.out.println("a1==b1? ===>" + (a1==b1)); -
3、反射:
反射机制的用途:
1、在运行中分析类的能力
2、在运行中查看对象,如编写一个toString方法供所有类使用
3、实现通用的数组操作代码
4、利用Method对象,这个对象很像C++中的函数指针-
利用反射分析类的能力:
1、Class类中的getFields、getMethods、getconstructors等方法将分别返回类提供的public域(属性)、方法和构造器数组,其中包括超类的共有成员。
2、Class类的getDeclareFields、getDeclareMethods、getDeclareConstructors方法将分别返回类中声明的全部域(属性)、方法和构造器,其中包括私有(private修饰的)和受保护(protected修饰的)成员,但不包括超类的成员。
注:为了可以获得私有成员的访问控制,需要调用Field、Method、Constructor类对象的setAccessible(AccessibleObject类的方法)方法:f.setAccessible(true);
-
4、接口:
接口定义与实现:
在接口声明中,抽象方法可以不显示声明public,因为接口中的所有方法都自动地是public。不过在实现接口时,必须把方法声明为public,否则,编译器将认为这个方法的访问属性是包可见性,即类的默认访问属性,之后编译器就会给出试图提供更加严格的访问权限的警告信息。接口可以提供多重继承的大多数好处,同时还能避免多重继承的复杂性和低效性。
clone方法:
1、默认的克隆操作是浅拷贝,它并没有克隆包含在对象中的内部对象。
2、即使clone的默认实现(浅拷贝)能满足需求,也应该实现Cloneable接口,将clone重定义为public,并调用super.clone()。
-
5、内部类
使用内部类的原因:
1、内部类方法可以访问该类定义的作用域中的数据,包括私有的数据。
2、内部类可以对同一个包中的其他类隐藏起来。
3、当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。局部类不能用
public或private访问说明符进行声明。它的作用域被限定在声明这个局部类的块中。局部类对外部世界可以完全隐藏起来。匿名内部类:由于构造器的名字必须与类名相同,而匿名类没有类名,所以,匿名类不能有构造器。
静态内部类:当使用内部类只为了把一个类隐藏在另一个类的内部,并不需要内部类引用外围类的对象时,可以将将内部类声明为
static,以便取消产生的引用。
-
6、代理:
代理是Java SE 1.3 新增加的特性。
代理类是在程序运行中创建的,然而,一旦被创建,就变成了常规类,与虚拟机中的任何其他类没有什么区别。
所有的代理类都覆盖了
Object类中的方法toString、equals、hashCode。代理类一定是
public和final。
三、相关类/对象
1、字符串
1、字符串通过拼接的方式来创建一个新的字符串效率不高。如果复制一个字符串变量,原始字符串与复制的字符串共享相同的字符。
2、只有字符串常量是共享的,而
+或substring等操作产生的结果并不是共享的,因此比较两个字符串是否相等,不要使用==来测试字符串的相等性。-
3、Java字符串有
char序列组成,char数据类型是一个采用UTF-16编码表示Unicode代码点的代码单元。大多数常用的Unicode字符使用一个代码单元就可以表示,而辅助字符一般需要一对代码单元表示。
要想获得实际的长度,即代码点数量,可以调用:String str = "hello"; //5 int cpCount = str.codePointCount(0, str.length(()); -
4、
StringBuilder与StringBufferStringBuilder在JDK5.0引入,
StringBuffer是StringBuilder的前身。StringBuilder是在单线程中进行字符串的编辑,效率相对较低
StringBuffer允许采用多线程的方式执行添加或删除字符的操作。使用StrinBuilder/StringBuffer来连接字符串的效率要高于采用字符串拼接(
+)的方式,因为每次使用+连接字符串都会构建一个新的String对象,既耗时,又浪费空间。
-
5、格式说明符语法:
格式说明符语法
2、集合
2.1、HashMap
-
1、概述:
HashMap中有 两个影响其性能的参数:初始容量 和 负载系数。其所需的容量表示
bucket的数量,初始容量是在创建时的容量。-
负载系数是在自动增加哈希表容量之前允许哈希表获取的程度的度量。
当哈希表中的条目数超过负载系数和当前容量的乘积时,哈希表进行
rehbed(即内部数据结构被重建),使得哈希表扩大至两倍的bucket。作为一般规则,默认负载系数(0.75)提供良好的性能时间和空间成本之间的折衷。较高的值降低了空间开销,但会增加查找成本(反映在大多数情况下)。
简单来说,HashMap有个初始容量(默认为16),当表中的条目超过这个负载容量(负载系数 x 当前容量),就会进行扩充到其两倍大小。
//默认大小 /** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 -
2、原理:
在Java1.7中,HashMap的实现方式是:数组+链表
在Java1.8中,HashMap的实现方式是:数组+链表(链表和红黑树会转换)put方法:
① 先根据 table 数组是否为空进行扩容操作,② 计算key的hash值并找到在数组的位置, ③ 未找到则加入,找到了则在当前位置的链表上判断key是否存在,存在就覆盖,否则就插入。-
get方法:
找到对应 key 的数组索引,然后遍历链表查找。
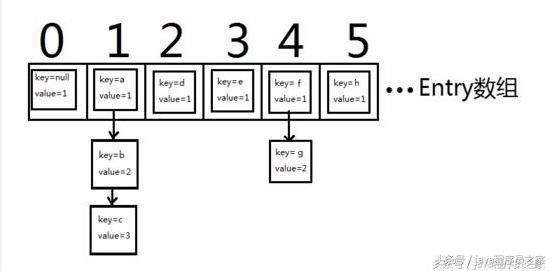 HashMap实现方式
HashMap实现方式 链表的作用就是处理hash碰撞的(产生碰撞的原因就是在计算key的时候是使用
除留余数法,可能导致不同的key值计算出来的结果是一样的,因此产生碰撞),将其插入到数组同一个位置的链表上。链表中存储的是
Entry,即键值对。在Java1.8中,链表达到阈值时(7或8)转为红黑树结构提高性能,当长度缩小到阈值(6)时,将红黑树转化为单向链表提高性能。
-
3、区别:
- 在Java 1.8 中,达到指定阈值时,链表会和红黑树进行转化
- 在 Java 1.8 中,Entry 被 Node 代替(换了一个马甲)
- 发生 hash 碰撞时,Java 1.7 会在链表头部插入,而 Java 1.8 会在链表尾部插入。
相关链接:
Android面试题:HashMap实现原理和源码分析
从源码的角度来谈一谈HashMap的内部实现原理
HashMap的工作原理
2.2、HashMap、HashTable、HashSet
-
1、HashMap与HashTable:
- 两者几乎可以等价,都实现了Map接口。
- 主要区别在于HashMap是非同步的,并可接收null的键和值,HashTable反之
- 单线程中推荐使用HashMap,因为HashTable是线程同步的,速度较HashMap慢
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
- 通过
Map m = Collections.synchronizeMap(hashMap);让HashMap进行同步。
-
2、HashMap和HashSet:
- 通过看
HashSet的源码可以看出,其内部就是依赖的一个HashMap,将HashSet的值作为key存储到HashMap中(value为静态常量PRESENT = new Object())。 - 两者都不能保证随着时间的推移,其中的元素次序不变。
- 对比:
HashMap HashSet HashMap实现了Map接口 HashSet实现了Set接口 HashMap储存键值对 HashSet仅仅存储对象 使用put()方法将元素放入map中 使用add()方法将元素放入set中 用键对象来计算hashcode值 用成员对象来计算hashcode值,若相等再用quals()判断对象的相等性 HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢 - 通过看
3、异常
- 在Java程序设计语言中,异常对象都是派生于
Throwable类的一个实例。 -
Throwable子类有两个分支:Error,Exception
1、Error类层次结构描述了Java运行时系统的内部错误和资源耗尽错误。应用程序不应该抛出这种类型的错误。
2、Exception类层次结构分为:RuntimeException、IOException
·RuntimeException:由程序错误导致的异常(一定是应用开发者导致的问题)
·IOException:由I/O错误这类问题导致的异常。 - try-catch-finally:
1、在catch子句中可以抛出一个异常,这样做的目的是改变异常的类型。
2、在Java SE 7之后,可以使用带资源的try语句(try-with-resources),最简单形式如下:try (Resource res = ...) { work with res }
4、泛型
4.1、定义:
类型变量使用大写形式,且比较短,在Java库中,使用变量
E表示集合的元素类型,K和V分别表示标的关键字和值的类型,T(需要时还可以用临近的字母U和S)表示“任意类型”。-
泛型方法的参数类型判断:
对于如下的示例:class ArrayAlg { public staticT getMiddle(T... a) { return a[a.length/2]; } } private void test() { double middle = ArrayAlg.getMiddle(3.14, 1234, 0); } 其中
test方法中会提示响应的错误信息:
 提示信息
提示信息
由于三个参数的类型不同,编译器将自动打包参数为1个Double 和两个Integer对象,而后寻找这些类的共同超类型。如果想知道编译器对一个泛型方法调用最终推断出哪种类型,可以有目的的引入一个错误,并研究所产生的错误信息,即上图所提示的信息。
-
一个类型变量(如下面的
T)或通配符(?)可以有多个限定(如Comparable和Serializable),如下:T extends Comparable & Serializable限定类型用
&分隔,二都好用来分隔类型变量。
在Java的继承中,可以根据需要拥有多个接口超类型,但限定中至多有一个类,如果用一个类作为限定,它必须是限定列表中的第一个。简单来说,上面的T可以继承多个接口,但最多只能继承一个类。
4.2、使用:
- 无论何时定义一个泛型类型,都自动提供了一个相应的原始类型(raw type)。原始类型的名字就是删去类型参数后的泛型类型名。
擦除(erased)类型变量,并替换为限定类型(无限定的变量用Object)。
1、例如,Pair的定义代码和原始类型如下所示:
2、如果声明了//Pair定义如下: public class Pair{ private T first; private T second; public Pair(T first, T second) { this.first = first; this.second = second; } public T getFirst() { return first; } public void setFirst(T first) { this.first = first; } public T getSecond() { return second; } public void setSecond(T second) { this.second = second; } } //原始类型如下: public class Pair { private Object first; private Object second; public Pair(Object first, Object second) { this.first = first; this.second = second; } public Object getFirst() { return first; } public void setFirst(Object first) { this.first = first; } public Object getSecond() { return second; } public void setSecond(Object second) { this.second = second; } } T继承了多个接口限定类型,则原始类型会用第一个接口限定类型作为替换类型,比如:
3、为了提高效率,应该将标签(public class Pair { private Comparable first; private Comparable second; public Pair(Comparable first, Comparable second) { this.first = first; this.second = second; } public Comparable getFirst() { return first; } public void setFirst(Comparable first) { this.first = first; } public Comparable getSecond() { return second; } public void setSecond(Comparable second) { this.second = second; } }tagging)接口(即没有方法的接口,如Serializable)放在边界列表的末尾。
4.3、约束与局限性:
不能用基本类型实例化类型参数
比如没有Pair,只有Pair。运行时类型查询只适用于原始类型
无论何时使用instanceof或涉及泛型类型的强制类型转换表达式都会看到一个编译器警告。-
不能创建参数化类型的数组
Pair[] table = new Pair [10]; //ERROR Varargs 警告
不能实例化参数变量
不能使用像new T(...),new T[...],T.class这样的表达式中的类型变量。泛型类的静态上下文中类型变量无效
不能再静态域或方法中引用类型变量。
禁止使用带有类型变量的静态域或方法。不能跑出或补货泛型类的实例
既不能抛出也不能捕获泛型类对象。甚至泛型类扩展Throwable都是不合法的。
通过使用泛型类、擦除和@SuppressWarings标注,就能消除Java类型系统的部分基本限制。注意擦除后的冲突