慢查询日志
当查询超过一定的时间没有返回结果的时候,才会记录到慢查询日志中。默认不开启。手工开启后可以帮助我们找出执行慢的SQL语句
查看慢SQL日志是否启用(on表示启用):
show variables like 'slow_query_log';
查看执行慢于多少秒的SQL会记录到日志文件中
show variables like 'long_query_time';
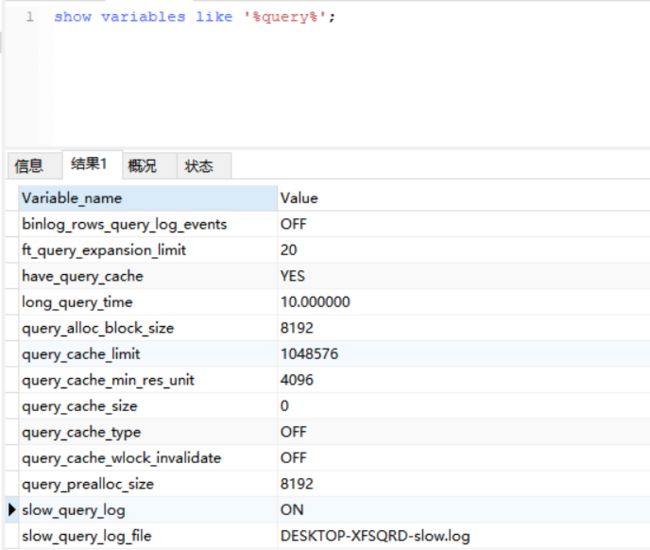
可以使用模糊搜索,查看所有含有query的变量信息
show variables like '%query%';
修改mysql配置参数
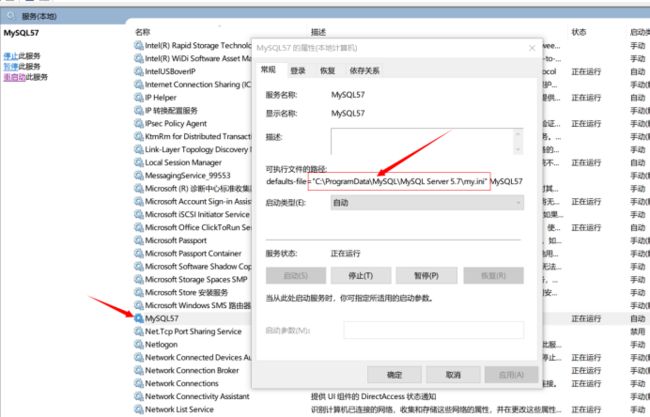
my.ini(Linux下文件名为my.cnf),查找到[mysqld]区段,增加日志的配置。
Windows下路径一般为C:\ProgramData\MySQL\MySQL Server 5.7\my.ini",可以在启动参数中查看使用的是那个配置文件。
常用的参数详解:
--是否开启慢查询日志
slow_query_log=1
--指定保存路径及文件名,默认为数据文件目录,
slow_query_log_file="bxg_mysql_slow.log"
--指定多少秒返回查询的结果为慢查询
long_query_time=1
--记录所有没有使用到索引的查询语句
log_queries_not_using_indexes=1
--记录那些由于查找了多于1000次而引发的慢查询
min_examined_row_limit=1000
--记录那些慢的optimize table,analyze table和alter table语句
log_slow_admin_statements=1
--记录由Slave所产生的慢查询
log_slow_slave_statements=1
datadir=C:/ProgramData/MySQL/MySQL Server 5.7\Data --数据文件目录
注意:修改以下参数,需要重新启动数据库服务才会生效。
命令行修改慢查询配置
命令行修改配置方式不需要不重启即可生效,但重启之后会自动失效。
set global slow_query_log=1;
set global slow_query_log_file='bxg_mysql_slow.log';
set long_query_time=1;
set global log_queries_not_using_indexes=1;
set global min_examined_row_limit=1000;
set global log_slow_admin_statements=1;
set global log_slow_slave_statements=1;
其他参数可通过以下命令查阅:
show variables like '%query%';
show variables like '%slow%';
慢日志格式
时间、主机信息、执行信息、执行时间、执行内容

查询缓存
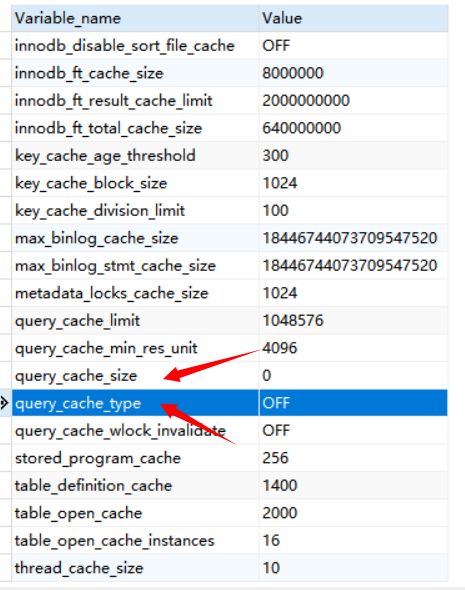
Query Cache 会缓存select 查询,安装时默认是开启的,但是如果对表进行INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE, DROP TABLE, or DROP DATABASE等操作时,之前的缓存会无效并且删除。这样一定程度上也会影响我们数据库的性能。所以对一些频繁的变动表的情况开启缓存是不明智的。还有一种情况我们测试数据库性能的时候也要关闭缓存,避免缓存对我们测试数据的影响。
show VARIABLES like '%cache%';
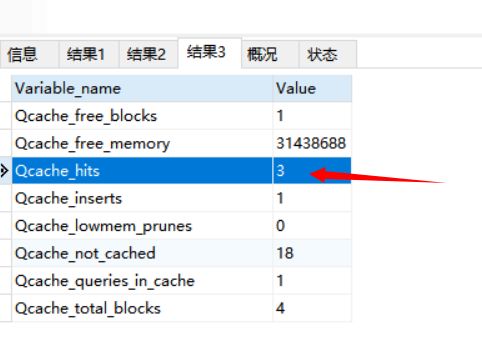
查看缓存命中情况
select count(*) FROM test;
select count(*) FROM test;
show status like '%qcache%';
关闭缓存有两种放法,一种临时的,一种永久的。临时的直接在命令行执行
set global query_cache_size=0;
set global query_cache_type=0; --如果配置文件中为关闭缓存的话,不能通过命令开启缓存
永久的修改配置文件my.cnf ,添加下面的配置即可。
query_cache_type=0
query_cache_size=0
另外,我们还可以通过sql_no_cache关键字在sql语句中直接禁用缓存,在开启缓存的情况下我们对sql语句做一些改动
Select sql_no_cache count(*) from pythonlearn.lianjia; -- 不缓存
Select sql_cache count(*) from pythonlearn.lianjia; -- 缓存(也可以不加,默认缓存已经开启了)
准备测试数据
创建测试表
-- 用户表
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NULL,
`fname` varchar(100) NOT NULL,
`lname` varchar(100) NOT NULL,
`age` tinyint(3) unsigned NOT NULL,
`sex` tinyint(1) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
--用户部门表
CREATE TABLE `department` (
`id` bigint(20) unsigned NOT NULL,
`department` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
-- 用户住址表
CREATE TABLE `address` (
`id` bigint(20) unsigned NOT NULL,
`address` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
创建存储过程,用于批量添加测试数据
delimiter $$
drop procedure if exists generate;
CREATE DEFINER=`root`@`localhost` PROCEDURE `generate`(IN num INT)
BEGIN
DECLARE chars VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE fname VARCHAR(10) DEFAULT '';
DECLARE lname VARCHAR(25) DEFAULT '';
DECLARE id int UNSIGNED;
DECLARE len int;
set id=1;
DELETE from person;
WHILE id <= num DO
set len = FLOOR(1 + RAND()*10);
set fname = '';
WHILE len > 0 DO
SET fname = CONCAT(fname,substring(chars,FLOOR(1 + RAND()*62),1));
SET len = len - 1;
END WHILE;
set len = FLOOR(1+RAND()*25);
set lname = '';
WHILE len > 0 DO
SET lname = CONCAT(lname,SUBSTR(chars,FLOOR(1 + RAND()*62),1));
SET len = len - 1;
END WHILE;
INSERT into person VALUES (id,fname,lname, FLOOR(RAND()*100), FLOOR(RAND()*2));
set id = id + 1;
END WHILE;
END $$
delimiter $$
drop procedure if exists genDepAdd;
CREATE DEFINER=`root`@`localhost` PROCEDURE `genDepAdd`(IN num INT)
BEGIN
DECLARE chars VARCHAR(100) DEFAULT '行政技术研发财务人事开发公关推广营销咨询客服运营测试';
DECLARE chars2 VARCHAR(100) DEFAULT '北京上海青岛重庆成都安徽福建浙江杭州深圳温州内蒙古天津河北西安三期';
DECLARE depart VARCHAR(10) DEFAULT '';
DECLARE address VARCHAR(25) DEFAULT '';
DECLARE id int UNSIGNED;
DECLARE len int;
set id=1;
WHILE id <= num DO
set len = FLOOR(2 + RAND()*2);
set depart = '';
WHILE len > 0 DO
SET depart = CONCAT(depart,substring(chars,FLOOR(1 + RAND()*26),1));
SET len = len - 1;
END WHILE;
set depart=CONCAT(depart,'部');
set len = FLOOR(6+RAND()*18);
set address = '';
WHILE len > 0 DO
SET address = CONCAT(address,SUBSTR(chars2,FLOOR(1 + RAND()*33),1));
SET len = len - 1;
END WHILE;
INSERT into department VALUES (id,depart);
INSERT into address VALUES (id,address);
set id = id + 1;
END WHILE;
END $$
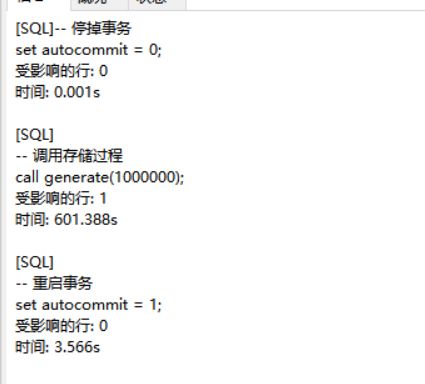
为了提高速度,可以暂停事务。测试添加100万随机数据,大概600s左右时间。
-- 停掉事务
set autocommit = 0;
-- 调用存储过程
call generate(1000000);
-- call genDepAdd(1000000);
-- 重启事务
set autocommit = 1;
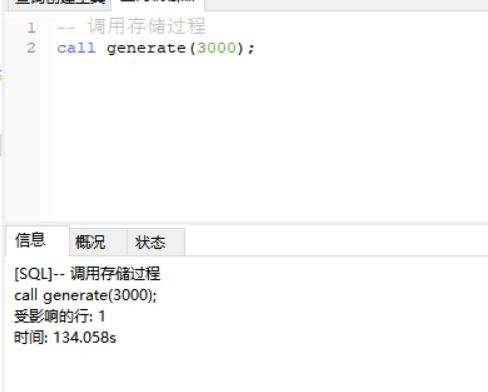
对比MyIsam:当创建表时选择MyIsam格式,插入数据会很慢,仅仅3000条数据就需要2分钟的时间,由此可见MyIsam和InnoDB的差距还是很大的。另外在执行过程中可以发现MyIsam插入的数据可以在表中实时看到,而InnoDB做了事务最终一次提交,所以数据不能实时看到,只有存储过程全部执行完成后才可以看到数据。
至此准备工作差不多了,下一章节我们将学习下数据库性能优化的一下常用工具和方法。
| 上一篇 | 《性能优化系列文章目录》 | 下一篇 |
|---|