使用数据文件:tweets.json
{
"tweets": [
{
"user": "Al",
"content": "I really love seafood.",
"timestamp": " Mon Dec 23 2013 21:30 GMT-0800 (PST)",
"retweets": ["Raj", "Pris", "Roy"],
"favorites": ["Sam"]
}, {
"user": "Al",
"content": "I take that back, this doesn't taste so good.",
"timestamp": "Mon Dec 23 2013 21:55 GMT-0800 (PST)",
"retweets": ["Roy"],
"favorites": []
}, {
"user": "Al",
"content": "From now on, I'm only eating cheese sandwiches.",
"timestamp": "Mon Dec 23 2013 22:22 GMT-0800 (PST)",
"retweets": [],
"favorites": ["Roy", "Sam"]
}, {
"user": "Roy",
"content": "Great workout!",
"timestamp": " Mon Dec 23 2013 7:20 GMT-0800 (PST)",
"retweets": [],
"favorites": []
}, {
"user": "Roy",
"content": "Spectacular oatmeal!",
"timestamp": " Mon Dec 23 2013 7:23 GMT-0800 (PST)",
"retweets": [],
"favorites ": []},
{
"user": "Roy",
"content": "Amazing traffic!",
"timestamp": " Mon Dec 23 2013 7:47 GMT-0800 (PST)",
"retweets": [],
"favorites": []
},
{
"user": "Roy",
"content": "Just got a ticket for texting and driving!",
"timestamp": " Mon Dec 23 2013 8:05 GMT-0800 (PST)",
"retweets": [],
"favorites": ["Sam", "Sally", "Pris"]
},
{
"user": "Pris",
"content": "Going to have some boiled eggs.",
"timestamp": " Mon Dec 23 2013 18:23 GMT-0800 (PST)",
"retweets": [],
"favorites": ["Sally"]
},
{
"user": "Pris",
"content": "Maybe practice some gymnastics.",
"timestamp": " Mon Dec 23 2013 19:47 GMT-0800 (PST)",
"retweets": [],
"favorites": ["Sally"]
},
{
"user": "Sam",
"content": "@Roy Let's get lunch",
"timestamp": " Mon Dec 23 2013 11:05 GMT-0800 (PST)",
"retweets": ["Pris"],
"favorites": ["Sally", "Pris"]
}
]
}
首先先导入文件,并将文件数据存入变量Data_中。(但是因为导入方法是异步方法,它发送文件请求后就会返回,执行后面的逻辑。所以如果后续逻辑紧接着就是用Data_,可能面临此时数据未返回未赋予Data_从而其值为空的情况,在这里不考虑)。
var Data_;
d3.json('tweets.json',function(d){
Data_=d;
});
然后,在建立列表,当然此时html页面的body元素中是完全空白的:
d3.select("body").append("ul");
d3.select("ul").selectAll("li").data(Data_.tweets,function(d,i){
return d.user;
}).enter().append("li").text(d=>d.user);
这里有几个要点
首先选择了
body元素,然后创建(追加一个)ul元素。在此基础上选择所有li元素,显然此时没有li元素,所以.selectAll("li")会返回一个空集。-
在空集基础之上绑定数据,暂且先不管
data()。因为此时没有DOM元素(li)可以用来绑定数据,造成情况就是待绑定的数据多余了,这些多余的数据分别被封装为EnterNode类型对象,推入data方法所返回的对象的_enter属性之中,因此后续使用enter()方法时会处理这些多余的数据。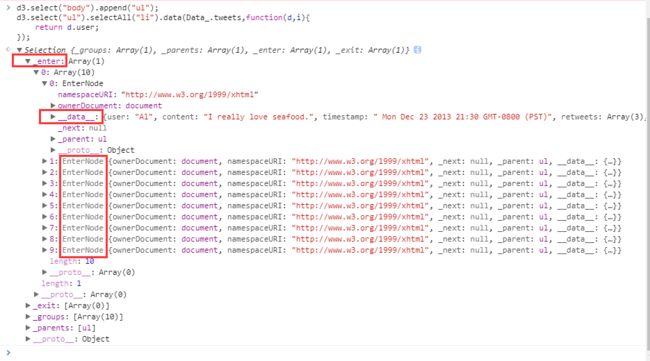 可以看见,data方法返回的Selection对象中有_enter、_exit、_groups、_parents四个属性,当绑定数据(调用data方法)后又多余数据,这些数据会被封装为EnterNode类型对象,推入_enter中,数据被放在_data_属性之中。当然可以想到,如果绑定数据之后,DOM元素反而多余了,那么这些元素就会被推入_exit属性之中,后面会看到
可以看见,data方法返回的Selection对象中有_enter、_exit、_groups、_parents四个属性,当绑定数据(调用data方法)后又多余数据,这些数据会被封装为EnterNode类型对象,推入_enter中,数据被放在_data_属性之中。当然可以想到,如果绑定数据之后,DOM元素反而多余了,那么这些元素就会被推入_exit属性之中,后面会看到 调用
enter()之后,后面的方法链会被循环调用。此时由于_enter属性中有10个EnterNode对象,则方法链会被调用10次,每一次都会传入EnterNode对象的__data__属性作为数据,在语句.enter().append("li").text(d=>d.user);,会插入一个li元素(append方法是上图中的_parent属性调用的,可见后面有一个[ul],它保存的就是父元素,在父元素上追加一个li子元素),一旦有这样一个li元素生成,那么li元素就会自动创建一个__data__属性,它的值和EnterNode对象的__data__是一致的,可以通过document.getElementsByTag("li")[i]._data_来查看。
text用来设置元素文本,它的参数是一个函数,这个d当然就是__data__。
另外要注意, 如果忽略了append,直接写成.enter().text(d=>d.user);则不会有任何效果,因为没有实际添加元素,自然也不会有数据被实际绑定。-
回到
data方法:data(Data_.tweets,function(d,i){ return d.user; })首先注意,写成
Data_.tweets而不能写成Data_,第一个参数是指定被绑定的数据集,它一定要是一个数组类型或类数组类型。在上面的json文件可知,引用Data_后,里面只有一个tweets对象,这显然不合适,需要使用Data_.tweets,它代表数据数组。
另外,第二个参数是指定主键,如果忽略,那么就按照数据数组的数字下标来充当主键。我们使用一个函数的返回值来充当主键,它是这么工作的:- 首先,计算selection中选中的DOM元素(
selectAll("li"))的主键,如果有多个DOM结点元素的主键值相同,则多余的DOM结点会被推入_exit_中,供之后的exit()方法连调用。 - 然后,按照给定的Key函数,基于数据集(
Data_.tweets)计算出每一个数据项的主键值。并与DOM元素的主键进行匹配。如果这个主键匹配成功,则该元素可以被用来后续操作;如果匹配不成功(或主键值重复),则说明该数据是多余的,那么它会被封装为EnterNode并被推入_enter中,供enter()之后的方法链调用
由于第一次使用,会创建li元素并且为其绑定
user作为主键值。注意,主键值(也就是函数返回值)必须是数字或者字符串,所以,如果想把一个对象作为主键,需要返回JSON.stringift(obj)或其他定义方法把它变成字符串,否则就会调用Object.prototype.toString().call,这样就会得出[object Object],则显然会造成主键重复 - 首先,计算selection中选中的DOM元素(
我们来看一个例子。上述代码运行后,会立刻在html页面中创建一个由10个列表项的列表,主键是每一个tweet的user,但是显然主键是有重复的。现在,我们再次运行代码
d3.select("ul").selectAll("li").data(Data_.tweets,function(d,i){
return d.user;
});
其返回结果
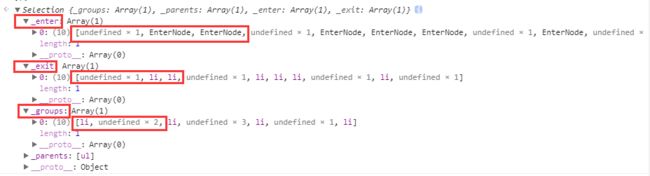
已知,前三个列表项的主键都是'Al'(用户名),所以只有第一个被推入
_groups中供后续操作,后面两个li的主键与第一个重复,它们就被推入了
_exit中,供
exit()调用后操作,同理,因为重复,这两个li所对应的
_data_属性数据也被封装并推入
_enter_之中。