前言
最近在做有关迁移学习的实验时需要对Office-Home数据集进行DeCAF6特征的抽取,遂查找了一下相关博客,并决定将其过程记录一下,希望可以帮助到以后遇到同样问题的小伙伴~
1、 安装并成功编译Caffe,具体过程请自行查阅其它资料,此处不再赘述。
2、进入Caffe根目录。特别注意:接下来的所有操作均在此目录下进行。
cd Caffe
3、下载预训练好的bvlc_reference_caffenet文件:1、下载链接1;2、下载链接2;3、在命令行运行以下代码:
scripts/download_model_binary.py models/bvlc_reference_caffenet
上面三种方式任选一种即可,第二种应该下载速度最快,因为是我的百度网盘分享。此外特别需要注意的是:如果采用[下载链接]进行下载,需要将下载后得到的文件手动移动到models/bvlc_reference_caffenet目录下。
4、新建一个文件夹存放特征文件以及其余的一些必要信息。
mkdir examples/temp
5、生成图像对应的目录文件以及相应的类标,此处需要大家根据自己的实际情况进行生成。生成后的文件格式如下:
/home/ices/OfficeHomeDatase/Art/Alarm_Clock/00001.jpg 1
/home/ices/OfficeHomeDatase/Art/Alarm_Clock/00002.jpg 1
...................
/home/ices/OfficeHomeDatase/Art/Alarm_Clock/00003.jpg 1
/home/ices/OfficeHomeDatase/Art/Alarm_Clock/00004.jpg 1
这里我是利用Matlab代码进行目录文件生成的,可以给大家一个参考。
5.1 我的图像目录格式如下:

5.2 以Art子目录为例,接下来的任务需要将Art目录下的所有图像的目录文件以及类标文件写入到‘file_list_Art.txt’中,在OfficeHomeDataset_10072016目录下新建txtGenerate.m文件,写入以下代码并运行:
clear all;
clc;
imgDataPath = 'Art';
imgDataDir = dir(imgDataPath);
label = 0;
fid = fopen(['file_list_' imgDataPath '.txt'],'w');
for i = 1:length(imgDataDir)
if(isequal(imgDataDir(i).name,'.')||...
isequal(imgDataDir(i).name,'..')||...
~imgDataDir(i).isdir)
continue;
end
label = label + 1;
imgDir = dir([imgDataPath '/' imgDataDir(i).name, '/*.jpg']);
for j = 1:length(imgDir)
fprintf(fid,'%s %d\n',[imgDir(j).folder '/' imgDir(j).name],label);
end
end
fclose(fid);
6、获取图像的平均值文件:data/ilsvrc212/imagenet_mean.binaryproto,运行以下代码:
./data/ilsvrc12/get_ilsvrc_aux.sh
7、将网络配置文件复制到我们第一步建立的example/temp文件夹下,方便对其进行修改:
cp examples/feature_extraction/imagenet_val.prototxt examples/temp
8、修改刚才复制到example/temp文件夹下的imagenet_val.prototxt文件,如下图所示:
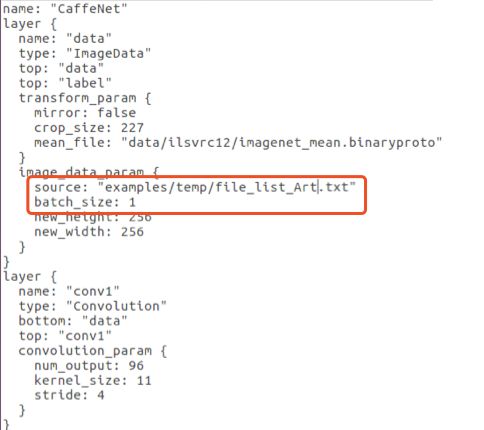
此处需要修改两个地方:1、在source:后面输入刚才生成的图像目录结构文件file_list_Art.txt的位置;2、batch_size的大小,为避免后续麻烦,我这里设置为1。
9、运行以下代码提取特征:
./build/tools/extract_features.bin models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel examples/temp/imagenet_val.prototxt fc6 examples/temp/features_Art 2427 lmdb GPU device_id=0

上面代码中只需要根据实际情况更改三处即可:
(a) fc6代表抽取的是第6层特征,如果需要抽取其余层,将其进行相应修改,比如fc7;
(b) features_Art代表抽出的特征保存到的文件夹名称,大家根据实际情况进行更改;
(c) 2427是Art目录下所有图像的数量,因为刚才的batch_size设置为1,所以此处batch_num设置为2427。
10、特征抽取成功后,会在features_Art文件夹下出现data.mdb和lock.mdb文件。上面两个文件便是需要的特征文件,分别存储着特征和类标信息。
11、将生成的mdb文件转换成mat文件:
11.1 新建feat_helper_pb2.py文件:
sudo gedit feat_helper_pb2.py
11.2 在feat_helper_pb2.py中输入以下代码:
# Generated by the protocol buffer compiler. DO NOT EDIT!
from google.protobuf import descriptor
from google.protobuf import message
from google.protobuf import reflection
from google.protobuf import descriptor_pb2
# @@protoc_insertion_point(imports)
DESCRIPTOR = descriptor.FileDescriptor(
name='datum.proto',
package='feat_extract',
serialized_pb='\n\x0b\x64\x61tum.proto\x12\x0c\x66\x65\x61t_extract\"i\n\x05\x44\x61tum\x12\x10\n\x08\x63hannels\x18\x01 \x01(\x05\x12\x0e\n\x06height\x18\x02 \x01(\x05\x12\r\n\x05width\x18\x03 \x01(\x05\x12\x0c\n\x04\x64\x61ta\x18\x04 \x01(\x0c\x12\r\n\x05label\x18\x05 \x01(\x05\x12\x12\n\nfloat_data\x18\x06 \x03(\x02')
_DATUM = descriptor.Descriptor(
name='Datum',
full_name='feat_extract.Datum',
filename=None,
file=DESCRIPTOR,
containing_type=None,
fields=[
descriptor.FieldDescriptor(
name='channels', full_name='feat_extract.Datum.channels', index=0,
number=1, type=5, cpp_type=1, label=1,
has_default_value=False, default_value=0,
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
descriptor.FieldDescriptor(
name='height', full_name='feat_extract.Datum.height', index=1,
number=2, type=5, cpp_type=1, label=1,
has_default_value=False, default_value=0,
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
descriptor.FieldDescriptor(
name='width', full_name='feat_extract.Datum.width', index=2,
number=3, type=5, cpp_type=1, label=1,
has_default_value=False, default_value=0,
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
descriptor.FieldDescriptor(
name='data', full_name='feat_extract.Datum.data', index=3,
number=4, type=12, cpp_type=9, label=1,
has_default_value=False, default_value="",
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
descriptor.FieldDescriptor(
name='label', full_name='feat_extract.Datum.label', index=4,
number=5, type=5, cpp_type=1, label=1,
has_default_value=False, default_value=0,
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
descriptor.FieldDescriptor(
name='float_data', full_name='feat_extract.Datum.float_data', index=5,
number=6, type=2, cpp_type=6, label=3,
has_default_value=False, default_value=[],
message_type=None, enum_type=None, containing_type=None,
is_extension=False, extension_scope=None,
options=None),
],
extensions=[
],
nested_types=[],
enum_types=[
],
options=None,
is_extendable=False,
extension_ranges=[],
serialized_start=29,
serialized_end=134,
)
DESCRIPTOR.message_types_by_name['Datum'] = _DATUM
class Datum(message.Message):
__metaclass__ = reflection.GeneratedProtocolMessageType
DESCRIPTOR = _DATUM
# @@protoc_insertion_point(class_scope:feat_extract.Datum)
# @@protoc_insertion_point(module_scope)
11.3 新建lmdb2mat.py文件:
sudo gedit lmdb2mat.py
11.4 在lmdb2mat.py中输入以下代码:
import lmdb
import feat_helper_pb2
import numpy as np
import scipy.io as sio
import time
def main(argv):
lmdb_name = sys.argv[1]
print "%s" % sys.argv[1]
batch_num = int(sys.argv[2]);
batch_size = int(sys.argv[3]);
window_num = batch_num*batch_size;
start = time.time()
if 'db' not in locals().keys():
db = lmdb.open(lmdb_name)
txn= db.begin()
cursor = txn.cursor()
cursor.iternext()
datum = feat_helper_pb2.Datum()
keys = []
values = []
for key, value in enumerate( cursor.iternext_nodup()):
keys.append(key)
values.append(cursor.value())
ft = np.zeros((window_num, int(sys.argv[4])))
for im_idx in range(window_num):
datum.ParseFromString(values[im_idx])
ft[im_idx, :] = datum.float_data
print 'time 1: %f' %(time.time() - start)
sio.savemat(sys.argv[5], {'feats':ft})
print 'time 2: %f' %(time.time() - start)
print 'done!'
if __name__ == '__main__':
import sys
main(sys.argv)
11.5 新建run_lmdb2mat.sh文件:
sudo gedit run_lmdb2mat.sh
11.6 在run_lmdb2mat.sh中输入以下代码:
#!/usr/bin/env sh
LMDB=./examples/temp/features_Art # lmdb文件路径
BATCHNUM=2427
BATCHSIZE=1
DIM=4096
OUT=./examples/temp/features_fc6_Art.mat #mat文件保存路径
python ./lmdb2mat.py $LMDB $BATCHNUM $BATCHSIZE $DIM $OUT
此处需要根据实际情况更改3处即可:
(a) LMDB 后面接lmdb文件的目录,即刚才生成的data.mdb和lock.mat文件的保存路径;
(b) BATCHNUM与BATCHSIZE需要与上面命令行运行代码以及网络配置文件中的设置一致!!!!!;
(c) OUT为对应的mat文件保存路径,根据实际情况更改最后的mat文件名即可。
11.7 运行run_lmdb2mat.sh:
sh run_lmdb2mat.sh
此时便可得到所需的特征文件。但是需要特别注意的是,此时的特征文件只有特征,并没有生成对应的类标信息,因此需要自己额外添加类标信息。本人通过实测发现特征文件中数据的顺序与目录格式文件‘file_list_Art.txt’中的文件顺序是一一对应的,因此根据此信息便可以得到对应的类标信息,具体方法此处不再赘述。至此,DeCAF6特征抽取全部完毕!!!
参考贴
[1] caffe 提取图像特征
[2] caffe 提取特征并可视化(已测试可执行)及在线可视化
[3] Extracting Features