Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取B站排行榜中的总站榜的三日排行
2.主题式网络爬虫爬取的内容与数据特征分析
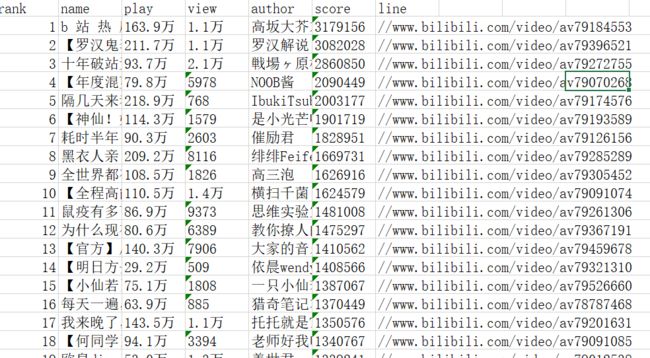
爬取内容:排名、视频名、排放量、弹幕数、up主、综合评分、视频链接
数据特征分析:分析排名、播放量、弹幕数和综合评分的关系
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
1.利用xlsxwriter建表
2.使用requests的get方法爬取页面源代码
3.使用re正则表达式爬取数据并存入表格
技术难点:
1.数据爬取时会出现错误
2.数据存入时会变成乱码
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
按F12查看,发现需爬取的数据皆为静态
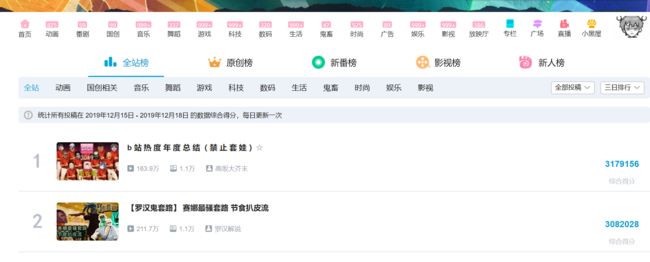
2.Htmls页面解析
div class=“content”标签中的便是要爬取的内容

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
利用requests中的get方法爬取网页,re中的findall的方法来遍历和查找需要获取的节点
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
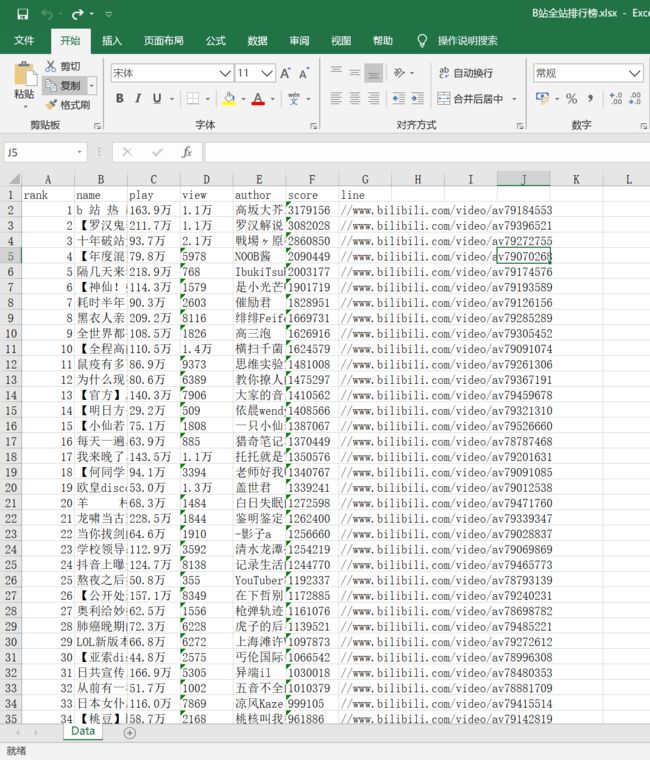
爬虫程序的代码如下 :



运行后生成表格
结果如下:
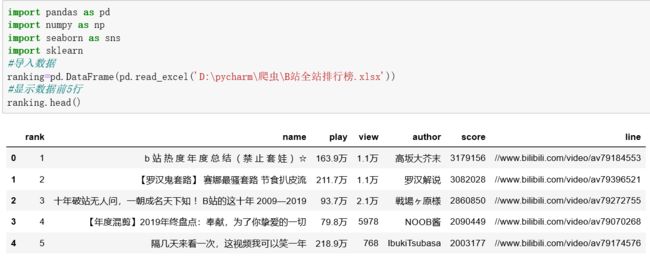
2.对数据进行清洗和处理
数据清洗:
导入数据
删除列

查找重复值

删除重复值

查询空值,返回无空值

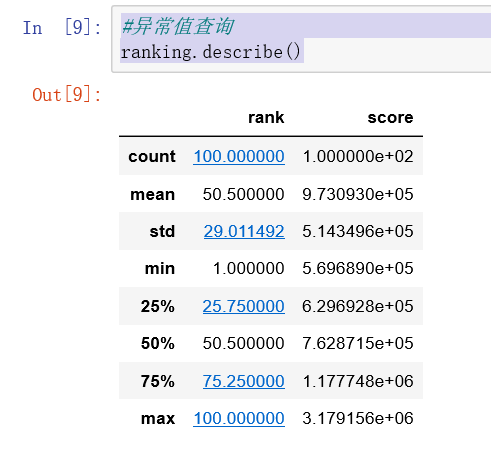
查询异常值
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
用散点图分析排名和综合评分的分布:
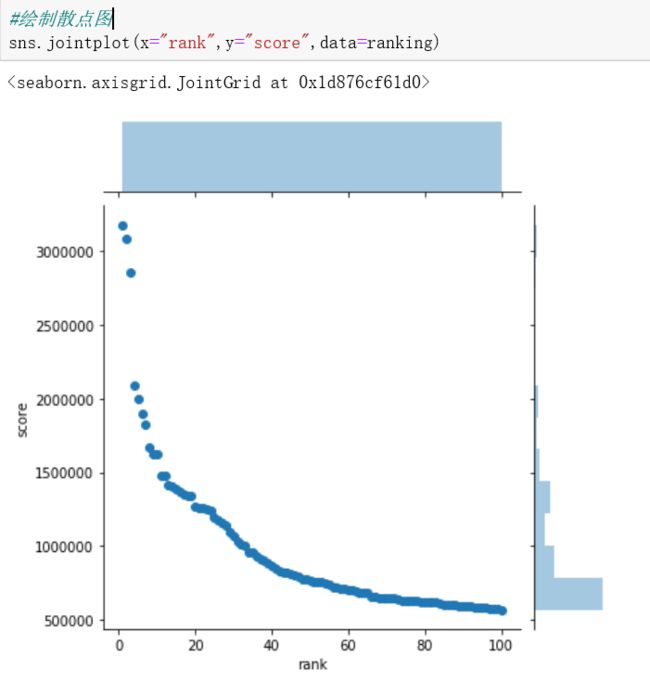
用盒图分析排名和综合评分的分布:

用直方图分析综合评分的分布:

用回归图分析排名和综合评分的关系:

(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化
6.附完整程序代码
#导入必须库 import requests import re import xlsxwriter import pandas as pd import numpy as np import seaborn as sns import sklearn #创建一个函数 def bilibili_craw(): #创建一个文件 #为文件命名 workbook=xlsxwriter.Workbook('B站全站排行榜.xlsx') #向文件添加数据 worksheet=workbook.add_worksheet('Data') #为文件每一列命名 row0=['rank','name','play','view','author','score','line'] #循环 for i in range(0,len(row0)): worksheet.write(0,i,row0[i]) #获取网站源代码 url='https://www.bilibili.com/ranking/all/0/0/3' r=requests.get(url) rs=r.text #循环 for i in range(1,101): try: #使用正则表达式获取排名 p='' v_title=re.compile(p_title).findall(n[0]) #用正则表达式爬取播放量 p_play='(.*?)' v_play=re.compile(p_play).findall(n[0]) # 用正则表达式爬取弹幕数 p_view='(.*?)' v_view=re.compile(p_view).findall(n[0]) # 用正则表达式爬取up主 p_author='(.*?)' v_author=re.compile(p_author).findall(n[0]) # 用正则表达式爬取综合评分 p_score='
(.*?)' v_score=re.compile(p_score).findall(n[0]) # 用正则表达式爬取视频链接 p_line='' v_line=re.compile(p_line).findall(n[0]) #向文件写入爬取到的数据 row1=[i,v_title[0],v_play[0],v_view[0],v_author[0],v_score[0],v_line[0]] #循环 for j in range(0,len(row1)): worksheet.write(i,j,row1[j]) except: continue #关闭文件 workbook.close() #运行函数 bilibili_craw() #导入数据 ranking=pd.DataFrame(pd.read_excel('D:\pycharm\爬虫\B站全站排行榜.xlsx')) #显示数据前5行 ranking.head() #删除视频链接那一列 ranking.drop('line',axis=1,inplace=True) ranking.head()
#查找重复值
ranking.duplicated()
#删除重复值
ranking=ranking.drop_duplicates()
#输出数据前五行
ranking.head()
#查询是否有空值
ranking['rank'].isnull().value_counts()
#异常值查询
ranking.describe()
#绘制散点图 sns.jointplot(x="rank",y="score",data=ranking) #绘制盒图 sns.boxplot(x='rank',y='score',data=ranking) #绘制直方图查看score的分布 sns.distplot(ranking['score']) #绘制回归图 sns.regplot(x='score',y='rank',data=ranking,color='b')
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?排名越高,综合评分越高
排名越高并不代表观看量,弹幕数越多,但观看量和弹幕数越多,排名都不低
2.对本次程序设计任务完成的情况做一个简单的小结。通过这次学习,初步了解了python的爬虫功能,对requests库和正则表达式,也有一定的了解,也对如何爬取HTML页面标签信息有了了解。